library(tidyverse)12 Správně formátovaná data a balík tidyr
Představte si výzkum vývoje dětí. Z populace si vybereme vzorek dětí, které budeme sledovat a následně u každého z nich každý měsíc naměříme řadu ukazatelů: výšku, váhu, počet červených krvinek, motorické a kognitivní schopnosti, počet prstů, atp.
Získáme tak soubor dat s mnoha pozorováními a mnoha dimenzemi. Jedno pozorování můžeme chápat jako moment měření – definuje ho tedy identita pozorovaného subjektu (průřezová jednotka) a čas pozorování (věk). Každá sledovaná charakteristika potom představuje samostatnou dimenzi.
Množství pozorování a dimenzí umožňuje nejrůznější organizaci naměřených dat. Data jsou typicky organizována do formátu pravoúhlé tabulky, kde jsou data zapsána v buňkách organizovaných v řádcích a sloupcích. Tabulky však mohou být různě vnitřeně organizované. Mohou se lišit v tom, které údaje se zapisují do sloupců, které do řádků a podobně
V této kapitole se naučíte:
- Jak vhodně organizovat data do tabulek – tzv. tidy formát
- S pomocí nástrojů z balíku tidyr upravovat data do tidy formátu
Balík tidyr nahradil starší balíky (např. reshape a reshape2). Načíst se dá buď individuálně a nebo s pomocí metabalíku tidyverse:
Poznámka: Stav této kapitoly odpovídá tidyr ve verzi 1.3.0.
12.1 Tidy data
Formát “tidy data” popisuje organizační strukturu dat v tabulkách. Data v tidy formátu splňují následující charakteristiky:
- Každé pozorování je popsáno jedním řádkem
- Každá proměnná je obsažena v jednom sloupci
- Každý typ pozorování má vlastní tabulku
Wickham (2016) ilustruje tidy fromát pomocí následujícího schématu:

Uvažujme příklad statistik o trhu práce. Statistický úřad sleduje na roční bázi počet nezaměstnaných a velikost dopělé populace pro obce, okresy a kraje. Pokud by ukládal data v tidy struktuře potom by:
- Data byla skladována ve třech tabulkách – v jedné tabulce by byly údaje pro kraje, v druhé pro okresy a ve třetí pro obce.
- Struktura každé tabulky by byla následující:
tibble(
area = c(rep("Kostelec",3),rep("Valtrovice",3)),
year = c(2001:2003,2001:2003),
adult_population = c(301,305,295,656,650,660),
unemployment_rate = runif(6, min=6,max=10) %>% round(digits=1)
) %>% print(n=6)# A tibble: 6 × 4
area year adult_population unemployment_rate
<chr> <int> <dbl> <dbl>
1 Kostelec 2001 301 6.5
2 Kostelec 2002 305 8.2
3 Kostelec 2003 295 8.1
4 Valtrovice 2001 656 9
5 Valtrovice 2002 650 9
6 Valtrovice 2003 660 8.5Každé pozorování je identifikováno správní jednotkou (area) a rokem (year). Každá sledovaná proměnná je potom uložena ve vlastním sloupci.
12.2 Transformace tabulek do tidy formátu
Ne všechny dostupné datasety jsou organizované v tidy formátu. Součástí tidyverse je balíček tidyr, který obsahuje nástroje pro transformaci tabulek do tidy formátu.
Základními funkcemi v balíku tidyr, které zvládnou většinu obvyklých problémů, jsou pivot_wider() a pivot_longer().
Poznámka 1
Funkce pivot_wider() a pivot_longer() přišly do tidyr od verze 1.0.0 (podzim 2019). Ve streších verzích balíku jejich funkci plnily funkce gather() a spread(), které byly vlastně speciálním případem obecnějších pivot_* funkcí. Funkce gather() a spread() byly v balíku podrženy pouze pro zachování zpětné kompatibility.
Transformace mnoha sloupců do jednoho s funkcí pivot_longer()
Mnoho datasetů obsahuje sloupce, jejichž jména nejsou samostatné proměnné, ale ve skutečnosti jde o hodnoty jedné proměnné. Jako příklad můžeme použít tabulku table4a z balíku tidyr, která zachycuje počet pozorovaných případů v několika letech a zemích:
print(table4a)# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 213766V tomto formátu obsahuje jeden řádek hned dvě pozorování (dvě pozorování z jedné země) a dva sloupce obsahují stejnou proměnnou (počet případů). Pro transformaci takové tabulky do tidy formátu slouží funkce pivot_longer().
pivot_longer() skládá hodnoty z vybraných sloupců do nově vytvořeného sloupce. Jména vybraných sloupců vytvoří další dodatečný sloupec. pivot_longer() tak nahradí vybrané sloupce dvěma novými:
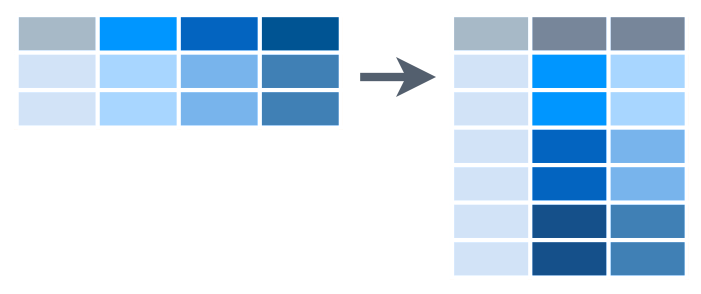 Výsledná tabulka je proto “delší”. Pro snadnější zapamatování se se proto funkce jmenuje
Výsledná tabulka je proto “delší”. Pro snadnější zapamatování se se proto funkce jmenuje pivot_longer().
Ukázkou praktické aplikace pivot_longer() může být transformace tabulky table4a:
table4a %>%
pivot_longer(-country)# A tibble: 6 × 3
country name value
<chr> <chr> <dbl>
1 Afghanistan 1999 745
2 Afghanistan 2000 2666
3 Brazil 1999 37737
4 Brazil 2000 80488
5 China 1999 212258
6 China 2000 213766Funkce pivot_longer() provedla transformaci ilustrovanou následujícím obrázkem:

gather() (Wickham, 2016)Původní tabulka měla 3 řádky. Nyní jich má 6. Každý původní řádek se rozpadl na dva nové.
Funkce pivot_longer() má následující syntax a parametry (více viz ?pivot_longer):
pivot_longer(
data,
cols,
...,
cols_vary = "fastest",
names_to = "name",
names_prefix = NULL,
names_sep = NULL,
names_pattern = NULL,
names_ptypes = NULL,
names_transform = NULL,
names_repair = "check_unique",
values_to = "value",
values_drop_na = FALSE,
values_ptypes = NULL,
values_transform = NULL
)Základní parametry jsou následující: - data…vstupní tabulka (data frame), která má projít transformací, - cols…identifikace sloupců, které mají být transformovány, - names_to…jméno sloupce, který ve výsledné tabulce bude obsahovat jména transformovaných sloupců, - values_to…jméno sloupce, který v transformované tabulce bude obsahovat hodnoty z původních sloupců.
Nyní se vraťme k úvodnímu příkladu:
table4a %>%
pivot_longer(-country)Vstupem do funkce pivot_longer() byla tabulka table4a. Parametr cols byl s využitím pomocné funkce - nastaven na hodnotu -country. To znamená, že transformovány byly všechny sloupce až na country. Nově vytvořená tabulka má tři sloupce: netransformovaný sloupec country a nově vytvořené sloupce name a value. Jména těchto sloupců jsou dána defaultním nastavením funkce pivot_longer().
Nyní se podíváme na složitější případ. Pro ilustraci upravenou tabulku table4a, které přidáme sloupec obsahující ID:
table4a %>%
mutate(id = row_number())# A tibble: 3 × 4
country `1999` `2000` id
<chr> <dbl> <dbl> <int>
1 Afghanistan 745 2666 1
2 Brazil 37737 80488 2
3 China 212258 213766 3Tabulku chceme transformovat tak, aby se sloupce s hodnotami (1999 a 2000) transformovaly do sloupců year a value. Je jasné, že chceme sáhnout po pivot_longer():
table4a %>%
# Tento řádek vytvoří nový sloupec s číslem řádku
mutate(id = row_number()) %>%
pivot_longer(-country, -id)Toto nebude fungovat, protože parametr cols má jenom jednu pozici – v jejím rámci musíme identifikovat všechny sloupce, které se mají transformovat.
# Použití negativní identifikace
table4a %>%
mutate(id = row_number()) %>%
pivot_longer(-c(country,id))# A tibble: 6 × 4
country id name value
<chr> <int> <chr> <dbl>
1 Afghanistan 1 1999 745
2 Afghanistan 1 2000 2666
3 Brazil 2 1999 37737
4 Brazil 2 2000 80488
5 China 3 1999 212258
6 China 3 2000 213766V tomto případě byl do jednomístného slotu vložen vektor vytvořený funkcí c(). Všiměte si, že i v něm jsou jména sloupců uvedena bez úvozovek.
Hint: V reálném nasazení je vždy užitečné zvážit použití negtivní identifikace sloupců. Představte si například situaci, kdy Vašim zdrojeme je databáze, do které každý rok přibude další sloupec. Pozitivní identifikace sloupců by způsobila, že Vaše skripty by po prvním updatu přestaly správně fungovat. Negativní identifikace tímto problémem netrpí.
Výše uvedená možnost není jediná možná. Následující příklady by vedly ke stejným výsledkům:
# Použití pozitivní identifikace
table4a %>%
mutate(id = row_number()) %>%
pivot_longer(c(`1999`,`2000`))
# Použití pozitivní identifikace a speciální funkce `:`
table4a %>%
mutate(id = row_number()) %>%
pivot_longer(`1999`:`2000`)
# Použití select helpers
table4a %>%
mutate(id = row_number()) %>%
pivot_longer(matches("\\d{4}"))Transformace dvojice sloupců do mnoha sloupců s funkcí pivot_wider()
Funkce pivot_wider() je inverzní k funkci pivot_longer(). Použijeme ji v případě, že sloupec ve skutečnosti neobsahuje hodnoty jedné proměnné, ale hodnoty mnoha proměnných. Funkce pivot_wider() transforumje dvojici sloupců do mnoha nových sloupců. Hodnoty prvního z původních sloupců obsahují určení proměnné a v druhém sloupci jsou uloženy jejich hodnoty.
Příkladem takového datasetu může být tabulka table2 z balíku tidyr:
print(table2)# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583Pozorování je opět identifikováno hodnotami ve sloupcích country a year. Nicméně jedno pozorování je roztaženo do dvou řádků a hodnoty pro počet případů (count) a velikost populace (population) jsou obsaženy v jednom sloupci count.
Pro převední takové tabulky do tidy fromátu je potřeba provést operaci popsanou následujícím schématem:

pivot_wider() (RStudio, 2015)Funkce pivot_wider() použije hodnoty z prvního sloupce (key) jako jména nově vytvořených sloupců. Nově vytvořené buňky jsou potom vyplněny hodnotami z druhého sloupce (value) v původní tabulce:
table2 %>%
pivot_wider(names_from = type, values_from = count)# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583Funkce pivot_wider() provedla transformaci ilustrovanou následujícím obrázkem:

pivot_wider() (Wickham, 2016)Funkce pivot_wider() má následující syntax a parametry (více viz ?pivot_wider):
pivot_wider(
data,
...,
id_cols = NULL,
id_expand = FALSE,
names_from = name,
names_prefix = "",
names_sep = "_",
names_glue = NULL,
names_sort = FALSE,
names_vary = "fastest",
names_expand = FALSE,
names_repair = "check_unique",
values_from = value,
values_fill = NULL,
values_fn = NULL,
unused_fn = NULL
)Klíčové parametry jsou následující:
data…vstupní tabulka (data frame), která má projít transformacíid_cols…sloupce, které identifikují jedno pozorování. V defaultní nastevením (tedyNULL) se k tomuto účelu použijí všechny sloupce, které neprocházejí transformací.names_from…sloupec (nebo sloupce), ze kterého se mají vytvořit jména nově vytvořených sloupců,values_from…sloupec (nebo sloupce), ze kterých se mají vzít hodnoty pro naplnění nově vytvořených sloupců.
Jak to funguje, pokud je parametr names_from delší než 1?
Předpokládejme, že chceme vytvořit tabulku, ve které budou sloupce definovány kombinací roku a proměnné:
table2 %>%
pivot_wider(names_from = c(type,year), values_from = count)# A tibble: 3 × 5
country cases_1999 population_1999 cases_2000 population_2000
<chr> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 745 19987071 2666 20595360
2 Brazil 37737 172006362 80488 174504898
3 China 212258 1272915272 213766 1280428583Jméno sloupců je teď vytvořené z kombinace type a year. Výslednou podobu jmen upravuje parametr names_sep z pivot_wider().
Praktické procvičení pivot_longer() a pivot_wider() I
Uvažujme tabulku vytvořenou v předchozím případě. Jak z ní vytvoříme tidy dataset?
Tabulka byla vytvořena s pivot_wider(). V prvním kroku tedy sáhneme tedy po inverzní funkci pivot_longer().
V tomto příkladě využijeme řadu zatím nediskutovaných parametrů pivot_longer():
table2 %>%
pivot_wider(names_from = c(type,year), values_from = count) %>%
pivot_longer(-country,
names_to = c("type","year"),
names_sep = "_",
names_transform = list(year = as.integer),
names_ptypes = list(type = character()),
values_to = "count"
)# A tibble: 12 × 4
country type year count
<chr> <chr> <int> <dbl>
1 Afghanistan cases 1999 745
2 Afghanistan population 1999 19987071
3 Afghanistan cases 2000 2666
4 Afghanistan population 2000 20595360
5 Brazil cases 1999 37737
6 Brazil population 1999 172006362
7 Brazil cases 2000 80488
8 Brazil population 2000 174504898
9 China cases 1999 212258
10 China population 1999 1272915272
11 China cases 2000 213766
12 China population 2000 1280428583Co se v nově použitých parametrech stalo? Parametr names_to je nyní délky 2. To znamená, že jména transformovaných sloupců se rozpadnou do dvou sloupců se zadanými jmény. Jak se má tento rozpad provést určuje parametr names_sep (u složitějších případů names_pattern). V současném nastavení říká, že znaky před _ mají být přeneseny do sloupce type a znaky za _ do sloupce year. Bylo by také vhodné, aby hodnoty ve sloupci type byly character a ve sloupci year integer. Tato konverze se nastavuje parametrem names_ptypes. Ten obsahuje pojmenovaný list. Jména odpovídají jménům nově vytvořených sloupců ke ketrým je přiřazen prázdný vektor požadovaného datového typu.
Tato transformace zvrátila účinky pivot_wider(). Nicméně data stále nejsou tidy. Potřebujeme mít dva nové sloupce cases a population s hodnotami ze sloupce count. A job for pivot_wider():
table2 %>%
pivot_wider(names_from = c(type,year), values_from = count) %>%
pivot_longer(-country,
names_to = c("type","year"),
names_sep = "_",
names_transform = list(year = as.integer),
names_ptypes = list(type = character()),
values_to = "count"
) %>%
pivot_wider(
id_cols = c(country,year), # V tomto případě ekvivalenttní k NULL
names_from = type,
values_from = count
)# A tibble: 6 × 4
country year cases population
<chr> <int> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583…and here we go.
Výsledek odpovídá formátu tidy data.
Praktická aplikace pivot_longer() a pivot_wider() II
Klasickým příkladem dat, které nejsou tidy jsou nejrůznější matice vzdáleností/podobností. Příklad níže ukazuje jeden z mnoha způsobů, jak se k podobné matici můžeme v R dostat. Pomocí balíku stringdist zde počítáme podobnost mezi textovými řetezci. Něco takového je užitečné třeba tehdy, pokud chceme dělat fuzzy matching – propojování podobných pozorování například u napojování dat, ve kterých jsou překlepy.
library(stringdist)
Attaching package: 'stringdist'The following object is masked from 'package:tidyr':
extractsurnames <- c("Nováková","Novaková","Nosálová","Novakowa")
dist_matrix <- stringdistmatrix(surnames, method = "lv")
print(dist_matrix) 1 2 3
2 1
3 2 3
4 3 2 5Výsledný objekt dist_matrix je třídy dist. Tu můžeme překlopit do obvyklé matice pomocí as.matrix(). Vy výsledku však chceme mít tidy tibble:
dist_matrix %>%
# Konvereze do matice, která má jeména řádků a sloupců
as.matrix() %>%
# Tibble nic jako "jména řádků" nemá. Musíme mu říct,
# jak s nimi má při konverzi naložit.
as_tibble(rownames = "stringA") %>%
# Tabulka stále není tidy (je "široká").
# Chceme ji transformovat na "dlouhou", kde je pozorování určeno
# stringem "A" a "B":
pivot_longer(-stringA, names_to = "stringB")# A tibble: 16 × 3
stringA stringB value
<chr> <chr> <dbl>
1 1 1 0
2 1 2 1
3 1 3 2
4 1 4 3
5 2 1 1
6 2 2 0
7 2 3 3
8 2 4 2
9 3 1 2
10 3 2 3
11 3 3 0
12 3 4 5
13 4 1 3
14 4 2 2
15 4 3 5
16 4 4 0Praktická aplikace pivot_longer() a pivot_wider() III
Jedním z nejfrekventovanějších zdrojů makro dat je bezpochyby databáze WDI, kterou provozuje World Bank. Tato databáze má API přes které je možné stahovat data přímo do R. Tato funkcionalita je implementována v balících WDI a wbstats (doporučuji právě wbstats).
Stáhněte si tabulku, která bude obsahovat data míře porodnosti (SP.DYN.CBRT.IN), úmrtnosti (SP.DYN.CDRT.IN) a čisté migraci (SM.POP.NETM):
library(wbstats)
wbdata <- wb(indicator = c(
"SP.DYN.CDRT.IN",
"SP.DYN.CBRT.IN",
"SM.POP.NETM"
)) %>%
as_tibble()load("tidyr_wbdata.RData")Každé API má svoje slabší chvilky. Pokud Vám nejde tabulka stáhnout, můžete si ji nahrát ze souboru tidyr_wbdata.RData.
Nyní se podívejme na strukturu tabulky:
wbdata %>% print(n = 5)# A tibble: 30,060 × 6
value date indicatorID indicator iso2c country
* <dbl> <chr> <chr> <chr> <chr> <chr>
1 5.75 2015 SP.DYN.CDRT.IN Death rate, crude (per 1,000 people) 1A Arab Wo…
2 5.79 2014 SP.DYN.CDRT.IN Death rate, crude (per 1,000 people) 1A Arab Wo…
3 5.84 2013 SP.DYN.CDRT.IN Death rate, crude (per 1,000 people) 1A Arab Wo…
4 5.88 2012 SP.DYN.CDRT.IN Death rate, crude (per 1,000 people) 1A Arab Wo…
5 5.93 2011 SP.DYN.CDRT.IN Death rate, crude (per 1,000 people) 1A Arab Wo…
# ℹ 30,055 more rowsTabulka obsahuje následující sloupce:
countryaiso2cje (opět) duplicitní ID pro průřezovou jednotku (zemi nebo agregát)dateje rok pozorování – pozor,wbstatsvrací rok jako characterindicatorIDaindicatorje duplicitní ID (skutečné ID a jméno) proměnnévalues pozorovanou hodnotou
Je jasné, že tabulka wbdata znovu není v tidy formátu. Jeden řádek obsahuje pozorovanou hodnotu pro kombinaci místa, času a proměnné. Tabulku tedy potřebujeme transformovat tak, aby jeden řádek obsahoval hodnoty všech proměnných pro unikátní kombinaci místa a času.
Řešení může být například takovéto:
# A tibble: 13,754 × 6
date iso2c country SP.DYN.CDRT.IN SP.DYN.CBRT.IN SM.POP.NETM
<chr> <chr> <chr> <dbl> <dbl> <dbl>
1 2015 1A Arab World 5.75 26.4 NA
2 2014 1A Arab World 5.79 26.8 NA
3 2013 1A Arab World 5.84 27.1 NA
4 2012 1A Arab World 5.88 27.3 -1168750
5 2011 1A Arab World 5.93 27.5 NA
6 2010 1A Arab World 5.97 27.5 NA
7 2009 1A Arab World 6.02 27.4 NA
8 2008 1A Arab World 6.07 27.4 NA
9 2007 1A Arab World 6.12 27.4 4413525
10 2006 1A Arab World 6.18 27.3 NA
# ℹ 13,744 more rowsProměnné jsou pojmenovány podle unikátních identifikátorů proměnných z databáze WDI a jejich hodnoty pochází ze sloupce value.
Řešení:
Zjevným problém při řešení problému je duplicita ID pro indikátory (indicatorID a indicator). Zkuste spustit následující kód. Proběhne bez varování a chyb, ale výsledek nebu správný. Proč? (Srovnejte počet řádků ze vzorového řešení s výsledkem následujícího kódu.)
wbdata %>%
pivot_wider(names_from = indicatorID)# A tibble: 30,060 × 7
date indicator iso2c country SP.DYN.CDRT.IN SP.DYN.CBRT.IN SM.POP.NETM
<chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
1 2015 Death rate, cr… 1A Arab W… 5.75 NA NA
2 2014 Death rate, cr… 1A Arab W… 5.79 NA NA
3 2013 Death rate, cr… 1A Arab W… 5.84 NA NA
4 2012 Death rate, cr… 1A Arab W… 5.88 NA NA
5 2011 Death rate, cr… 1A Arab W… 5.93 NA NA
6 2010 Death rate, cr… 1A Arab W… 5.97 NA NA
7 2009 Death rate, cr… 1A Arab W… 6.02 NA NA
8 2008 Death rate, cr… 1A Arab W… 6.07 NA NA
9 2007 Death rate, cr… 1A Arab W… 6.12 NA NA
10 2006 Death rate, cr… 1A Arab W… 6.18 NA NA
# ℹ 30,050 more rowsK dosažení správného výsledku musíme z tabulky vyloučit sloupec indicator a nebo použít parametr id_cols:
wbdata %>%
pivot_wider(id_cols = c(country,iso2c,date), names_from = indicatorID)# A tibble: 13,754 × 6
country iso2c date SP.DYN.CDRT.IN SP.DYN.CBRT.IN SM.POP.NETM
<chr> <chr> <chr> <dbl> <dbl> <dbl>
1 Arab World 1A 2015 5.75 26.4 NA
2 Arab World 1A 2014 5.79 26.8 NA
3 Arab World 1A 2013 5.84 27.1 NA
4 Arab World 1A 2012 5.88 27.3 -1168750
5 Arab World 1A 2011 5.93 27.5 NA
6 Arab World 1A 2010 5.97 27.5 NA
7 Arab World 1A 2009 6.02 27.4 NA
8 Arab World 1A 2008 6.07 27.4 NA
9 Arab World 1A 2007 6.12 27.4 4413525
10 Arab World 1A 2006 6.18 27.3 NA
# ℹ 13,744 more rows12.3 Další funkce z tidyr
Kromě funkcí pivot_*(), které jsou bezesporu nejvíce používané při čistění a transformaci dat, obsahuje tidyr řadu dalších funkcí, které pomáhají s:
- Odstraněním méně obvyklých případů při transformaci tabulek do tidy fromátu.
- Nakládáním s chybějícími hodnotami.
- Konstrukcí vlastních tabulek.
Různé typy pozorování v jedná tabulce: nest() a unnest()
Definice tidy formátu vyžaduje, aby byl každý typ pozorování uchován v oddělené tabulce. Obvyklejší vyřešením tohoto problému je filtrování dat. Pro některé aplikace se hodí i funkce nest() a unnest(). Jejich využití však není obyvklé a pro základní i pokročilejší práci obyvkle nejsou potřeba (tj. přeskočíme je).
Tabulka population_world obsahuje data, která toto kritérium nesplňují. Obsahuje pozorování jak za jednotlivá pozorování, tak jejich agregované hodnoty:
print(population_world)# A tibble: 9 × 5
country observation year Female Male
<chr> <chr> <int> <dbl> <dbl>
1 Iceland unit 2005 148. 149.
2 Iceland unit 2010 158. 160.
3 Iceland unit 2015 164. 165.
4 Malta unit 2005 201. 196.
5 Malta unit 2010 207. 205.
6 Malta unit 2015 210. 208.
7 World aggregate 2005 348. 346.
8 World aggregate 2010 365. 365.
9 World aggregate 2015 375. 374.Pomocí funkce nest() je možné vytvořit datovou strukturu, která tento problém vyřeší. nest() vytvoří “tabulku tabulek”. Můžeme ji použít pro vytvoření tabulky, která bude obsahovat jednotlivé tabulky v tidy formátu:
population_world_nested <- population_world %>% nest(data = -observation)
print(population_world_nested)# A tibble: 2 × 2
observation data
<chr> <list>
1 unit <tibble [6 × 4]>
2 aggregate <tibble [3 × 4]>Tabulky v tidy formátu jsou obsaženy v nově vytvořeném sloupci data:
print(population_world_nested$data)[[1]]
# A tibble: 6 × 4
country year Female Male
<chr> <int> <dbl> <dbl>
1 Iceland 2005 148. 149.
2 Iceland 2010 158. 160.
3 Iceland 2015 164. 165.
4 Malta 2005 201. 196.
5 Malta 2010 207. 205.
6 Malta 2015 210. 208.
[[2]]
# A tibble: 3 × 4
country year Female Male
<chr> <int> <dbl> <dbl>
1 World 2005 348. 346.
2 World 2010 365. 365.
3 World 2015 375. 374.Fungování nest() ilustruje následující diagram:
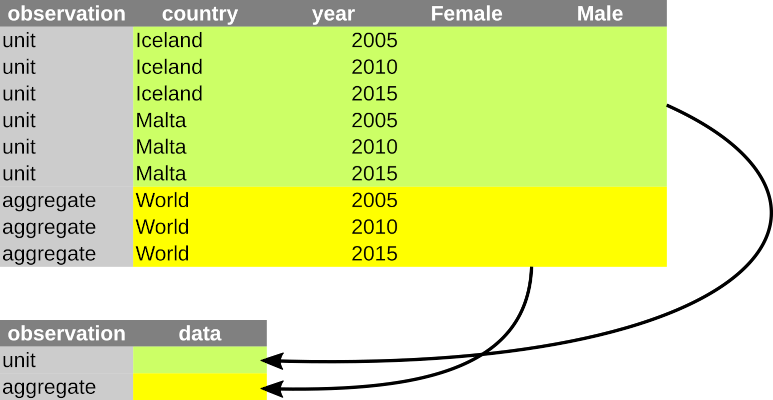
nest()Hlavním praktickým využitím nest() je vytvoření datové struktury, která může sloužit pro následnou datovou analýzu s pomocí nástrojů, které nejsou plně kompatibilní s logikou tidyverse. Zejména u vysoce specializivaných aplikací je takových funkcí překvapivě mnoho. Na některé případy narazíme zejména na konci kurzu.
Syntaxe funkce nest() je velmi jednoduchá (viz ?nest):
nest(data, ...)data…vstupní tabulka (data frame)...…identifikace sloupců, které mají být součástí nově vytvořených (pod)tabulek. Podobně jako v případěpivot_longer()lze využít více způsobů, jak sloupce specifikovat: select helpers, atp.
Základním způsobem identifikace sloupců je podle jejich jmen:
population_world %>%
nest(data = c(year,Female,Male))# A tibble: 3 × 3
country observation data
<chr> <chr> <list>
1 Iceland unit <tibble [3 × 3]>
2 Malta unit <tibble [3 × 3]>
3 World aggregate <tibble [3 × 3]>Jméno vektoru data se použije jako název nově vytvořeného sloupce. Pokud vektor nijak nepojmenujete, vrátí Vám nest() varování a nový sloupec pojmenuje právě data.
Na příkladech výše bylo ukázán příklad výběru sloupců s pomocí speciální funkce -. Funkční by měly být všechny způsoby identifikace podle tidyselect.
Datovou strukturu vytvořenou funkcí nest() lze transformovat do původního stavu pomocí funkce unnest():
population_world_nested %>% unnest(data)# A tibble: 9 × 5
observation country year Female Male
<chr> <chr> <int> <dbl> <dbl>
1 unit Iceland 2005 148. 149.
2 unit Iceland 2010 158. 160.
3 unit Iceland 2015 164. 165.
4 unit Malta 2005 201. 196.
5 unit Malta 2010 207. 205.
6 unit Malta 2015 210. 208.
7 aggregate World 2005 348. 346.
8 aggregate World 2010 365. 365.
9 aggregate World 2015 375. 374.Syntaxe funkce unnest() je následující:
unnest(data,
cols,
...,
keep_empty = FALSE,
ptype = NULL,
names_sep = NULL,
names_repair = "check_unique"
)Základní parametry jsou: - data…je vstupní tabulka, - cols…je parametr vymezující sloupce, které se mají transformovat (obsahujících tabulky, které se mají “rozbalit”).
Více hodnot v jedné buňce
Některé tabulky obsahují v jedné buňce hodnoty více proměnných. Jako příklad může sloužit tabulka tidyr::table3:
print(table3)# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583Ve sloupci rate je obsažen podíl počtu případů (cases) na celkové populaci (population). Proměnná rate je navíc nutně uložena jako text (character). S takovou proměnnou nelze rozumně pracovat. tidyr obsahuje nástroje, pomocí kterých je možné taková data převést do tidy formátu, který vyžaduje, aby obsahem jedné buňky byla vždy hodnota právě jedné proměnné.
Rozdělení jednoho sloupce do mnoha s funkcemi separate_wider_*()
Sloupec rate v tabulce table3 obsahuje v každé buňce dva údaje – počet případů (cases) a velikost populace (population). Obě hdonoty jsou při tom oddělené znakem “/”. Pro transformaci proměnné rate na několik sloupců máme k dispozici tři funkce:
separate_wider_delim()separate_wider_position()separate_wider_regex()
Všechny tři mají za cíl nejen nahradit původní funkce separate() a extract(), ale i rozšířit její možnosti. (Všechny tři funkce mají zatím tag experimental, je tak možné očekávat i podstatné změny v jejich fungování.)
Přímou náhradou separate() je separate_wider_delim(), která rozděluje proměnnou do nových znaků podle jasně definovaného znaku – v našem případě by šlo o “/”:
table3 %>% separate_wider_delim(
rate,
delim="/",
names = c("cases","population")
)# A tibble: 6 × 4
country year cases population
<chr> <dbl> <chr> <chr>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583Použití starší funkce separate() by bylo velmi podobné:
table3 %>% separate(rate, c("cases","population"), sep="/")separate_wider_delim() provádí operaci ilustrovanou následujícím digramem:

separate() (Wickham, 2016)Funkce separate_wider_delim() má následující syntaxi a parametry:
separate_wider_delim(
data,
cols,
delim,
...,
names = NULL,
names_sep = NULL,
names_repair = "check_unique",
too_few = c("error", "debug", "align_start", "align_end"),
too_many = c("error", "debug", "drop", "merge"),
cols_remove = TRUE
)data…vstupní tabulka (data frame)col…specifikace sloupce, který se má rozdělit. Sloupec je specifikován jako jméno bez úvozovek.names…jména nově vytvářených sloupců specifikovaná jako vektor (character vector)delim…udává znak, který se použije pro rozdělení vstupního sloupce na výstupní sloupce.cols_remove…Má být vstupní sloupec zachován ve výstupní tabulce?too_fewatoo_many…udávají, co se má stát, pokud rozdělovaný řeťezec obsahuje přílíš málo nebo naopak příliš mnoho kousků.
Základní nastavení parametrů too_few a too_many je error. To je určitě správně, protože výzkumník by si v takovém případě měl vždy oveřit, co přesně se v datech děje. K tomu dobře slouží nastavení paramterů na debug:
table3 %>%
separate_wider_delim(
rate,
delim = "/",
# Tady způsobíme problém. Řeknu, že se dvě hodnoty z rate mají "rozdělit"
# do jednoho sloupce:
names = c("cases"),
too_many = "debug"
)Warning: Debug mode activated: adding variables `rate_ok`, `rate_pieces`, and
`rate_remainder`.# A tibble: 6 × 7
country year cases rate rate_ok rate_pieces rate_remainder
<chr> <dbl> <chr> <chr> <lgl> <int> <chr>
1 Afghanistan 1999 745 745/19987071 FALSE 2 /19987071
2 Afghanistan 2000 2666 2666/20595360 FALSE 2 /20595360
3 Brazil 1999 37737 37737/172006362 FALSE 2 /172006362
4 Brazil 2000 80488 80488/174504898 FALSE 2 /174504898
5 China 1999 212258 212258/1272915272 FALSE 2 /1272915272
6 China 2000 213766 213766/1280428583 FALSE 2 /1280428583 V tomto případě funkce “projde”, ale vytvoří se nové sloupce, které umožní uživateli najít problémové řádky a diagnostikovat problém.
Vedle funkce separate_wider_delim() existují i funkce separate_wider_position() a separate_wider_regex(), které fungují analogicky. Rozdíl je v kritériích, které se použijí pro rozdělení původního sloupce. V případě separate_wider_position() jde o fixně nastavené počty znaků (parametr widths) a v případě separate_wider_regex() o regulární výraz (parametr patterns).
Rozdělení jednoho řádku do mnoha s funkcemi separate_longer_*()
Dalšími experimentálními funkcemi jsou separate_longer_*(), které nahrazují původní separate_rows(). Tyto funkce nerozkládá vstupní sloupec do nových sloupců při zachování počtu řádků, ale zachovávají počet sloupců a navyšují počet řádků. V životě praktickém se samozřejmě jedná o méně častou variantu, která najde využití zejména u transformace dat z dotazníků. Je však extrémně užitečná, protože nemá žádný jednoduchý substitut.
Funkce separate_longer_*() jsou dvě: separate_longer_delim() a separate_longer_position(), které jsou svou logikou analogické k sesterským funkcím separate_wider_*():
table3 %>% separate_longer_delim(rate, delim = "/")# A tibble: 12 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745
2 Afghanistan 1999 19987071
3 Afghanistan 2000 2666
4 Afghanistan 2000 20595360
5 Brazil 1999 37737
6 Brazil 1999 172006362
7 Brazil 2000 80488
8 Brazil 2000 174504898
9 China 1999 212258
10 China 1999 1272915272
11 China 2000 213766
12 China 2000 1280428583Funkce semozřejmě nemají parametr names, protože nevytváří žádné nové sloupce.
Použití separate_longer_*() na table3 nemá smysl. Hodí se například v situaci, kdy jsou v buňce obsaženy identifikátory více různých stavů. Praktickým příkladem může být údaj o zatržení různých checkboxů ve formuláři – takto je obsahují např. CSV exportované z Google Forms – viz následující aplikace
Aplikace
Google Forms je platforma, která umožňuje tvorbu jednoduchých dotazníků. Odpovědi jsou ukládány do tabulek a mohou být staženy ve formátu CSV. Pro cvičené účely byl vytvořen následující dotazník:

Dotazník obsahuje tři typy otázek:
- radiobutton – je možné zvolit pouze jednu nabízenou odpověď
- checkbox – respondent může zvolit více odpovědí
- radiobutton grid – respondent může v každém řádku zvolit právě jednu odpověď
Data vytvořená pomocí tohoto dotazníku najdete v souboru tidyr_GoogleForms.csv.
gforms <- read_csv("tidyr_GoogleForms.csv")print(gforms)# A tibble: 5 × 6
Timestamp Choose one of follow…¹ Choose multiple answ…² Radiobutton grid: [R…³
<chr> <chr> <chr> <chr>
1 2016/07/… Option A Option 1;Option 3 Column 2
2 2016/07/… Option C Option 3 Column 4
3 2016/07/… Option B Option 2 <NA>
4 2016/07/… Option A Option 1;Option 2 Column 2
5 2016/07/… Option C Option 1;Option 2;Opt… Column 2
# ℹ abbreviated names: ¹`Choose one of following (radiobutton):`,
# ²`Choose multiple answers (checkbox):`, ³`Radiobutton grid: [Row 1]`
# ℹ 2 more variables: `Radiobutton grid: [Row 2]` <chr>,
# `Radiobutton grid: [Row 3]` <chr>Vidíte, že výsledná tabulka má velmi komplikovanou strukturu. Každý řádek reprezentuje jednoho respondenta (pozorování). Jména sloupců jsou založena na znění otázek a hodnoty v buňkách jsou všechny vybrané hodnoty:
# A tibble: 5 × 1
`Choose multiple answers (checkbox):`
<chr>
1 Option 1;Option 3
2 Option 3
3 Option 2
4 Option 1;Option 2
5 Option 1;Option 2;Option 3 To je problém zejména u druhé otázky (checkbox): více hodnot oddělených “;” je namačkáno v jedné buňce. Data tedy nejsou tidy.
Úkol:
- Přejmenujte sloupce tak, aby nová jména odpovídala kódům otázek: q1, q2, q3a, q3b a q3c.
- Transformujte sloupec q2 tak, že ho rozdělíte na 4 sloupce (q2_1, q2_2, q2_3 a q2_2), odpovídající jednotlivým možnostem, které respondent mohl zvolit. V každém nově vytvořeném sloupci bude logická proměnná, která bude nebývat hodnoty
TRUEpokud respondent tuto variantu zvolil. Pozor, variantu 4 si nezvolil nikdo. Přesto má mít svůj sloupec!
Řešení:
Řešení prvního úkolu je jednoduché. Můžeme pro něj použít například funkci names(), nebo některou jinou funkci, která dokáže přejmenovávat sloupce.
names(gforms)[-1] <- c("q1","q2","q3a","q3b","q3c")
print(gforms)# A tibble: 5 × 6
Timestamp q1 q2 q3a q3b q3c
<chr> <chr> <chr> <chr> <chr> <chr>
1 2016/07/04 8:58:36 am EET Option A Option 1;Option 3 Colu… Colu… Colu…
2 2016/07/04 8:58:56 am EET Option C Option 3 Colu… Colu… Colu…
3 2016/07/04 8:59:11 am EET Option B Option 2 <NA> Colu… Colu…
4 2016/07/04 8:59:35 am EET Option A Option 1;Option 2 Colu… Colu… Colu…
5 2016/07/04 9:00:58 am EET Option C Option 1;Option 2;Option… Colu… Colu… <NA> Alternativně pomocí rename() z dplyr:
gforms <- gforms %>%
rename(
q1 = `Choose one of following (radiobutton):`,
q2 = `Choose multiple answers (checkbox):`,
q3a = `Radiobutton grid: [Row 1]`,
q3b = `Radiobutton grid: [Row 2]`,
q3c = `Radiobutton grid: [Row 3]`
)Druhý úkol je složitější. Využijeme pro něj funkci separate_longer_delim(). Pro lepší pochopení toho, jak separate_longer_delim() funguje přidáme nejprve do tabulky sloupec ID s identifikátorem respondenta (využijeme k tomu funkce z balíku dplyr):
gforms <- gforms %>%
mutate(ID = row_number()) %>%
relocate(ID, everything())
print(gforms)# A tibble: 5 × 7
ID Timestamp q1 q2 q3a q3b q3c
<int> <chr> <chr> <chr> <chr> <chr> <chr>
1 1 2016/07/04 8:58:36 am EET Option A Option 1;Option 3 Colu… Colu… Colu…
2 2 2016/07/04 8:58:56 am EET Option C Option 3 Colu… Colu… Colu…
3 3 2016/07/04 8:59:11 am EET Option B Option 2 <NA> Colu… Colu…
4 4 2016/07/04 8:59:35 am EET Option A Option 1;Option 2 Colu… Colu… Colu…
5 5 2016/07/04 9:00:58 am EET Option C Option 1;Option 2;… Colu… Colu… <NA> Jako ID lze zpravidla použít proměnnou Timestamp generovanou Google Forms.
Nejjednodušší řešení je následující:
gforms %>%
separate_longer_delim(
q2,
delim = ";"
)# A tibble: 9 × 7
ID Timestamp q1 q2 q3a q3b q3c
<int> <chr> <chr> <chr> <chr> <chr> <chr>
1 1 2016/07/04 8:58:36 am EET Option A Option 1 Column 2 Column 1 Column 4
2 1 2016/07/04 8:58:36 am EET Option A Option 3 Column 2 Column 1 Column 4
3 2 2016/07/04 8:58:56 am EET Option C Option 3 Column 4 Column 3 Column 2
4 3 2016/07/04 8:59:11 am EET Option B Option 2 <NA> Column 3 Column 2
5 4 2016/07/04 8:59:35 am EET Option A Option 1 Column 2 Column 3 Column 1
6 4 2016/07/04 8:59:35 am EET Option A Option 2 Column 2 Column 3 Column 1
7 5 2016/07/04 9:00:58 am EET Option C Option 1 Column 2 Column 3 <NA>
8 5 2016/07/04 9:00:58 am EET Option C Option 2 Column 2 Column 3 <NA>
9 5 2016/07/04 9:00:58 am EET Option C Option 3 Column 2 Column 3 <NA> Sloupec ID ukazuje, co se vlastně stalo. Jeden respondent je momentálně “namnožený do více řádků”.
gforms %>%
separate_longer_delim(
q2,
delim = ";"
)# A tibble: 9 × 7
ID Timestamp q1 q2 q3a q3b q3c
<int> <chr> <chr> <chr> <chr> <chr> <chr>
1 1 2016/07/04 8:58:36 am EET Option A Option 1 Column 2 Column 1 Column 4
2 1 2016/07/04 8:58:36 am EET Option A Option 3 Column 2 Column 1 Column 4
3 2 2016/07/04 8:58:56 am EET Option C Option 3 Column 4 Column 3 Column 2
4 3 2016/07/04 8:59:11 am EET Option B Option 2 <NA> Column 3 Column 2
5 4 2016/07/04 8:59:35 am EET Option A Option 1 Column 2 Column 3 Column 1
6 4 2016/07/04 8:59:35 am EET Option A Option 2 Column 2 Column 3 Column 1
7 5 2016/07/04 9:00:58 am EET Option C Option 1 Column 2 Column 3 <NA>
8 5 2016/07/04 9:00:58 am EET Option C Option 2 Column 2 Column 3 <NA>
9 5 2016/07/04 9:00:58 am EET Option C Option 3 Column 2 Column 3 <NA> Sloučení mnoha sloupců do jednoho s unite()
tidyr obsahuje funkci, které umožňuje provádět inverzní operaci – tedy slučovat více sloupců do jednoho. Tabulka tidyr::table5 obsahuje rok pozorování rozložený na století a rok:
print(table5)# A tibble: 6 × 4
country century year rate
<chr> <chr> <chr> <chr>
1 Afghanistan 19 99 745/19987071
2 Afghanistan 20 00 2666/20595360
3 Brazil 19 99 37737/172006362
4 Brazil 20 00 80488/174504898
5 China 19 99 212258/1272915272
6 China 20 00 213766/1280428583Kompletní letopočet můžeme složit pomocí funkce unite():
table5 %>% unite(year,century,year, sep="")# A tibble: 6 × 3
country year rate
<chr> <chr> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583unite() má obdobné rozhraní a parametry jako funkce určené k rozdělování hodnot (viz ?unite):
unite(data, col, ..., sep = "_", remove = TRUE)data…vstupní tabulka (data frame)col…jméno nově vytvořeného sloupce (prosté jméno bez úvozovek)...…sloupce, ze kterých má být nově vytvořený sloupec vytvořen (vizdplyr::select)sep…znak oddělující hodnoty z jednotlivých sloupcůremove…mají být původní sloupce odstraněny?
12.4 Implicitní a explicitní chybějící hodnoty
Tabulky často nejsou úplné – některá pozorování chybějí. Chybějící pozorování je účelné rozdělit na implicitní a explicitní.
Rozdíl mezi nimi je demonstrován na následujících tabulkách vytvořených z table1.
První tabulka table1_expl obsahuje explicitní chybějící hodnoty. Pozorování (Brazílie v roce 1999) je v tabulce přítomno, ale místo naměřených hodnot vidíme NA:
table1_expl <- table1
table1_expl[table1_expl$country == "Brazil" & table1_expl$year == 1999, c("cases","population")] <- NA
table1_expl[table1_expl$country == "Afghanistan" & table1_expl$year == 1999, "cases"] <- NA
print(table1_expl)# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 NA 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 NA NA
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583Tabulka table1_impl obsahuje implicitní chybějící hodnoty. Pozorování s nenaměřenými chybami v tabulce vůbec není přítomno:
table1_impl <- table1
table1_impl <- table1_impl[!(table1_impl$country == "Brazil" & table1_impl$year == 1999),]
print(table1_impl)# A tibble: 5 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 2000 80488 174504898
4 China 1999 212258 1272915272
5 China 2000 213766 1280428583Implicitní chybějící hodnoty jsou při analýze dat velmi zákeřné – nejsou viditelné “pouhým okem” a ani testem na přítomnost NA:
table1_impl[!complete.cases(table1_impl),]# A tibble: 0 × 4
# ℹ 4 variables: country <chr>, year <dbl>, cases <dbl>, population <dbl>Odstranění implicitních chybějících hodnot s complete()
Při analýze dat je proto vhodné konvertovat implicitní chybějící hodnoty na explicitní. Pro tento účel je možné použít funkci complete():
complete(table1_impl, country, year)# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 NA NA
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583Syntaxe funkce complete() je velmi přímočará:
complete(data, ..., fill = list())data…vstupní tabulka (data frame)...…sloupce, ze které definují (jednoznačně identifikují) pozorování (v příkladu výšecountryayear)
Ve výchozím nastavení jsou implicitní chybějící hodnoty nahrazeny NA. Toto chování lze změnit parametrem fill. Můžeme například vědět, že pokud není žádný případ zaznamenán, tak statistický úřad pozorování nezapisuje – i když by měl správně zapsat hodnotu 0. (Takto skutečně v některých případech postupuje ČSÚ.) Znalost dat nás tedy vede k tomu, že chybějící pozorování ve sloupci cases jsou ve skutečnosti nulová pozorování. Správně doplněné chybějící hodnoty je tedy možné získat nastavením parametru fill:
complete(table1_impl, country, year, fill = list(cases = 0))# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 0 NA
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583Do parametru fill se vkládá list s pojmenovanými položkami. Jména položek musí odpovídat jménům sloupců v tabulce a musí obsahovat právě jednu hodnotu. Ta je použita pro nahrazení chybějících hodnot.
V příkladu výše zůstalo chybějící pozorování v population nahrazeno NA. Pokud není pravidlo pro náhradu explicitně stanoveno ve fill, zůstává v platnosti výchozí nastavení.
Odstranění explicitních chybějících hodnot s drop_na()
V některých případech je naopak vhodné odstranit explicitní chybějící hodnoty a pracovat s tabulkou, ve které jsou implicitní chybějící hodnoty. Pro to je možné využít funkci drop_na():
drop_na(table1_expl)# A tibble: 4 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 2000 2666 20595360
2 Brazil 2000 80488 174504898
3 China 1999 212258 1272915272
4 China 2000 213766 1280428583Ve výchozím nastavení drop_na() zahazuje všechny řádky, na nichž se vyskytla chybějící hodnota – a to v libovolném sloupci. Toto chování lze změnit pomocí jediného dodatečného parametru funkce ..., který umožňuje specifikovat, které sloupce mají být brány v potaz. Sloupce mohou být identifikovány všemi způsoby srozumitelnými pro dplyr::select().
V následujícím příkladě je vypuštěn pouze řádek, ve kterém je chybějící hodnota ve sloupci population:
drop_na(table1_expl, population)# A tibble: 5 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 NA 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 2000 80488 174504898
4 China 1999 212258 1272915272
5 China 2000 213766 1280428583Nahrazení explicitních chybějících hodnot s fill(), replace_na()
První funkcí pro nahrazování explicitních chybějících pozorování je replace_na(). Její syntaxe a fungování je analogické k parametru fill funkce complete(). (complete() je nakonec pouze wrapper okolo replace_na() a několika dalších funkcí.)
Následující použití replace_na() nahradí chybějící pozorování ve sloupci cases nulami a v population milionem:
replace_na(table1_expl, replace = list(cases = 0, population = 1000000))# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 0 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 0 1000000
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583replace_na() je užitečná ve velmi omezeném množství případů (viz complete()). Častěji je pravděpoodbně v praxi využívána funkce fill(). fill() nahrazuje chybějící hodnotu hodnotou z předcházejícího (výchozí možnost) nebo následujícího řádku. Pozor, fill() pracuje pouze tehdy, pokud jsou chybějící hodnoty explicitní!
Funkci fill() je nutné v parametru ... specifikovat sloupce, u kterých se má nahrazení chybějících hodnot provést. (fill() opět rozumí všem možnostem dostupným v dplyr::select().) Následující ukázka demonstruje úskalí používání funkce fill():
fill(table1_expl, cases)# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 NA 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 2666 NA
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583- Chybějící hodnota v prvním řádku nebyla nahrazena – neexistuje totiž žádný předcházející řádek.
- Údaj pro Brazilii byl nahrazen údajem pro Afganistán.
První problém samozřejmě nemá řešení. Výzkumník může zvážit nahrazení hodnotou z následujícího řádku (pomocí parametru .direction = "up"). Pro druhý problém je řešení následující:
- Rozdělit tabulku na mnoho dílčích tabulek podél proměnné
country. - Provést nahrazení v každé z nich.
- Tabulky složit zpátky.
Takový úkol je jistě proveditelný, ale velmi složitý. Naštěstí právě takovou funkcionalitu poskytuje group_by() z balíku dplyr. group_by() umožňuje každou definovanou skupinu zpracovat odděleně:
table1_expl %>%
group_by(country) %>%
fill(cases)# A tibble: 6 × 4
# Groups: country [3]
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 NA 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 NA NA
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583V tomto případě je výsledek v pořádku – Brazílie “nedědí” hodnoty Afganistánu.
Aplikace
OSN publikuje ve World Population Prospects demografická data a projekce pro roky dělitelné pěti a všechny státy světa. Zaměříme se na tabulku pop, která obsahuje počet obyvatel v tisících pro všechny státy světa a období 1950–2015. Tabulku z WPP 2017 najdete v souboru tidyr_wpp_pop.RData. (Data z World Population Prospects jsou pro R uvolňována v balíčcích wpp*.)
load("tidyr_wpp_pop.RData")head(pop) country_code name 1950 1955 1960 1965 1970 1975 1980 1985
1 4 Afghanistan NA NA NA NA NA NA NA NA
2 8 Albania NA NA NA NA NA NA NA NA
3 12 Algeria NA NA NA NA NA NA NA NA
4 24 Angola NA NA NA NA NA NA NA NA
5 28 Antigua and Barbuda NA NA NA NA NA NA NA NA
6 31 Azerbaijan NA NA NA NA NA NA NA NA
1990 1995 2000 2005 2010 2015
1 12249.115 17099.541 20093.767 25070.796 28803.164 33736.494
2 3281.452 3106.719 3121.965 3079.180 2940.517 2923.354
3 25912.369 28904.297 31183.657 33288.436 36117.641 39871.531
4 12171.437 14268.990 16440.921 19552.538 23369.124 27859.303
5 66.698 73.612 83.586 89.256 94.654 99.926
6 7242.768 7775.420 8122.743 8538.610 9032.465 9617.494Úkolem je:
- přeskládat data v tabulce
popdo tidy formátu - přeměnit implicitní chybějící hodnoty na explicitní
- doplnit chybějící hodnoty poslední pozorovanou hodnotou
Výsledná tabulka má vypdat takto:
# A tibble: 15,906 × 4
country_code name year population
<int> <fct> <int> <dbl>
1 4 Afghanistan 1950 NA
2 4 Afghanistan 1951 NA
3 4 Afghanistan 1952 NA
4 4 Afghanistan 1953 NA
5 4 Afghanistan 1954 NA
6 4 Afghanistan 1955 NA
7 4 Afghanistan 1956 NA
8 4 Afghanistan 1957 NA
9 4 Afghanistan 1958 NA
10 4 Afghanistan 1959 NA
# ℹ 15,896 more rows1. Konverze do tidy formátu
V tabulce pop obsahuje jeden řádek více pozorování – velikosti populace jedné země ve více letech. Jedno pozorování je přitom definováno jako kombinace země (určené kódem a jménem) a rokem. Transformujte tabulku tak, aby jeden řádek obsahoval právě jedno pozorování:
pop %>%
pivot_longer(
-c(country_code,name),
names_to = "year",
values_to = "population",
names_transform = list(year = as.integer)
)# A tibble: 3,374 × 4
country_code name year population
<int> <fct> <int> <dbl>
1 4 Afghanistan 1950 NA
2 4 Afghanistan 1955 NA
3 4 Afghanistan 1960 NA
4 4 Afghanistan 1965 NA
5 4 Afghanistan 1970 NA
6 4 Afghanistan 1975 NA
7 4 Afghanistan 1980 NA
8 4 Afghanistan 1985 NA
9 4 Afghanistan 1990 12249.
10 4 Afghanistan 1995 17100.
# ℹ 3,364 more rowsVšiměte si v řešení dvou věcí. První je, že je explicitně nastavena hodnota parametru names_to. Defaultní hodnota je totiž stejná jako jméno existujícího sloupce. To by vedlo ke konfliktu a chybě. Druhé věc je nastavení konverze roku do integer.
Všimněte si, že výčet řádků, které se mají transformovat funkcí pivot_longer() je vymezen negativně. Použitý kód je tak univerzálnější a připraven na updaty.
pop %>%
pivot_longer(
c(`1950`:`2015`),
names_repair = "minimal",
names_to = "year",
values_to = "population",
names_transform = list(year = as.integer)
)je zcela korektní a vrátí stejný výsledek. Pokud ovšem v budoucnosti uvolní OSN data i pro rok 2020, potom kód s pozitivním výčtem přestane fungovat správně. Museli byste procházet své skripty a přepisovat je. Vyhýbejte se kódování takových parametrů “natvrdo”.
Je také taktické konvertovat data do přirozeného formátu. Pro rok je to celkem jednoznačně celé číslo. V tomto případě dosáhneme konverze jednoduše s použitím parametru names_transform. Výhodou konverze roků do čísel je například snadnější vytváření lagovaných proměnných nebo subsetování (viz lekce s dplyr).
2. Konverze implicitních chybějících hodnot na explicitní
Data WPP obsahují hodnoty pouze pro roky dělitelné pěti. Žádné jiné roky se v tabulce pop nevyskytují. Ergo jejich hodnoty jsou implicitní chybějící hodnoty. Implicitní chybějící hodnoty mohou být nebezpečné a proto je chceme konvertovat na hodnoty explicitní. Chceme, aby výsledná tabulka vypadala takto:
pop %>%
as_tibble() %>%
pivot_longer(
-c(country_code,name),
names_to = "year",
values_to = "population",
names_transform = list(year = as.integer)
) %>%
complete(nesting(country_code, name), year = min(.$year):max(.$year)) # A tibble: 15,906 × 4
country_code name year population
<int> <fct> <int> <dbl>
1 4 Afghanistan 1950 NA
2 4 Afghanistan 1951 NA
3 4 Afghanistan 1952 NA
4 4 Afghanistan 1953 NA
5 4 Afghanistan 1954 NA
6 4 Afghanistan 1955 NA
7 4 Afghanistan 1956 NA
8 4 Afghanistan 1957 NA
9 4 Afghanistan 1958 NA
10 4 Afghanistan 1959 NA
# ℹ 15,896 more rowsTohoto výsledku lze dosáhnout mnoha způsoby. tidyr však obsahuje funkci complete(), která tento úkol výrazně zjednodušuje:
pop %>%
pivot_longer(-c(country_code,name),
names_to = "year",
values_to = "population",
names_transform = list(year = as.integer)) %>%
complete(country_code, name, year = 1950:2015)# A tibble: 3,833,346 × 4
country_code name year population
<int> <fct> <int> <dbl>
1 4 Afghanistan 1950 NA
2 4 Afghanistan 1951 NA
3 4 Afghanistan 1952 NA
4 4 Afghanistan 1953 NA
5 4 Afghanistan 1954 NA
6 4 Afghanistan 1955 NA
7 4 Afghanistan 1956 NA
8 4 Afghanistan 1957 NA
9 4 Afghanistan 1958 NA
10 4 Afghanistan 1959 NA
# ℹ 3,833,336 more rowsVšimněte si, jak jsou nastaveny argumenty complete(). Funkce najde všechny unikátní kombinace zadaných sloupců, které identifikují pozorování a k nim přiřadí hodnoty – v našem případě ze sloupce population.
Tady přichází první problém. Tabulka pop neobsahuje všechny roky, ale jen ty, dělitelné pěti. Pro sloupec year je tedy nutné zadat všechny hodnoty, kterých může nebývat. V našem případě interval od 1950 do 2015. Obecně však není dobré zadávat parametry “natvrdo”. Deklarace 1950:2015 nás totiž prakticky zbavuje výhody negativního výču transformovaných sloupců, porotže s každým updatem tabulky by bylo nutné tento parametr měnit.
Tento problém ale můžeme vyřešit s pomocí placeholderu .:
pop %>%
as_tibble() %>%
pivot_longer(
-c(country_code,name),
names_to = "year",
values_to = "population",
names_transform = list(year = as.integer)
) %>%
complete(country_code, name, year = min(.$year):max(.$year)) # A tibble: 3,833,346 × 4
country_code name year population
<int> <fct> <int> <dbl>
1 4 Afghanistan 1950 NA
2 4 Afghanistan 1951 NA
3 4 Afghanistan 1952 NA
4 4 Afghanistan 1953 NA
5 4 Afghanistan 1954 NA
6 4 Afghanistan 1955 NA
7 4 Afghanistan 1956 NA
8 4 Afghanistan 1957 NA
9 4 Afghanistan 1958 NA
10 4 Afghanistan 1959 NA
# ℹ 3,833,336 more rowsJe ale toto řešení správné? Není. Tabulka pop obsahuje údaje pro \(N = 241\) zemí a pro každou z nich chceme údaj pro každý rok mezi lety 1950 a 2015 ( \(T = 66\)). Výsledná tabulka by tedy měla mít \(N \times T = 15.906\) řádků. Tabulka v předchozí řešení jich ale má mnohem víc! Problém je v tom, že ID pro průřezovou jednotku je vlastně duplicitní. Země je identifikována jak sloupcem name, tak sloupcem country_code a complete se snaží dosadit hodnoty ke všem kombinacím hodnot z těchto sloupců – výsledná tabulka tedy má \(N \times N \times T = 3.833.346\) řádků a hlavně nesmyslný obsah.
Možným řešením tohoto problému je využití funkce nesting(). Ta řekne funkci complete(), aby zacházela se dvěma sloupci, jako by to byl jeden:
# A tibble: 15,906 × 4
country_code name year population
<int> <fct> <int> <dbl>
1 4 Afghanistan 1950 NA
2 4 Afghanistan 1951 NA
3 4 Afghanistan 1952 NA
4 4 Afghanistan 1953 NA
5 4 Afghanistan 1954 NA
6 4 Afghanistan 1955 NA
7 4 Afghanistan 1956 NA
8 4 Afghanistan 1957 NA
9 4 Afghanistan 1958 NA
10 4 Afghanistan 1959 NA
# ℹ 15,896 more rows3. Doplnění chybějících hodnot
Ve výsledné tabulce chybí hodnoty u velikosti populace. Musíme je doplnit poslední pozorovanou hodnotou (příklad řešení je omezen na Bulharsko po roce 1990):
# A tibble: 26 × 4
country_code name year population
<int> <fct> <int> <dbl>
1 100 Bulgaria 1990 8841.
2 100 Bulgaria 1991 8841.
3 100 Bulgaria 1992 8841.
4 100 Bulgaria 1993 8841.
5 100 Bulgaria 1994 8841.
6 100 Bulgaria 1995 8379.
7 100 Bulgaria 1996 8379.
8 100 Bulgaria 1997 8379.
9 100 Bulgaria 1998 8379.
10 100 Bulgaria 1999 8379.
# ℹ 16 more rowsNejsnazší cestou k výsledku je použití funkce fill(). Ta ovšem umí nahradit pouze explicitní chybějící hodnoty a proto je bylo nutné nejprve vytvořit z těch implicitních:
pop %>%
pivot_longer(-c(country_code,name),
names_to = "year",
values_to = "population",
names_transform = list(year = as.integer)) %>%
complete(nesting(country_code, name), year = min(.$year):max(.$year)) %>%
fill(population, .direction = "down")Funkce fill() má parametr .direction, který nastavuje chování této funkce. V případě nastavení down doplněju hodnoty z předchozích řádků.
Při použití fill() musíte být velmi opatrní. Podívejte se na výběr řádků vyprodukovaných předchozím kódem:
# A tibble: 11 × 4
country_code name year population
<int> <fct> <int> <dbl>
1 4 Afghanistan 2011 28803.
2 4 Afghanistan 2012 28803.
3 4 Afghanistan 2013 28803.
4 4 Afghanistan 2014 28803.
5 4 Afghanistan 2015 33736.
6 8 Albania 1950 33736.
7 8 Albania 1951 33736.
8 8 Albania 1952 33736.
9 8 Albania 1953 33736.
10 8 Albania 1954 33736.
11 8 Albania 1955 33736.Jsoou zde zjevné dva problémy. První je, že funkce fill() neví, zda dělá něco, co dává smysl. V tomto případě vesele doplní pro Albánii v roce 1950 (chybějící pozorování) hodnotu pro Afghánistán z roku 2015. Prostě to byl předchozí řádek. S tím souvisí i druhý problém. Musíte se postarat o to, aby byly řádky ve správném pořadí. Správné protektované řešení by tedy vypadalo takto:
pop %>%
as_tibble() %>%
pivot_longer(
-c(country_code,name),
names_to = "year",
values_to = "population",
names_transform = list(year = as.integer)
) %>%
complete(nesting(country_code, name), year = min(.$year):max(.$year)) %>%
group_by(country_code) %>%
arrange(year, .by_group = TRUE) %>%
fill(population, .direction = "down") %>%
ungroup()Toto řešení používá koncepty a funkce z balíku dplyr (group_by() a arrange()), kterým se budeme věnovat příště.
12.5 Konstrukce vlastních tabulek s crossing()
V některých případech je užitečné vytvořit si vlastní tabulku. Typickým příkladem může být vytvoření “kostry” tabulky, která bude obsahovat všechny možné varinty (identifikátory) pozorování, které se ve výsledné tabulce mohou vyskytnout.
Například můžeme chtít vytvořit panelová data pro země V4 a pro roky 2000–2001. Tento úkol je možné efektivně vyřešit pomocí crossing():
crossing(
country = c("Czech Republic","Slovakia","Poland","Hungary"),
year = 2000:2001
)# A tibble: 8 × 2
country year
<chr> <int>
1 Czech Republic 2000
2 Czech Republic 2001
3 Hungary 2000
4 Hungary 2001
5 Poland 2000
6 Poland 2001
7 Slovakia 2000
8 Slovakia 2001