
Ochutnávka místo úvodu
Tato kniha vysvětluje, jak analyzovat a vizualizovat data ve výpočetním prostředí R. R je programovací jazyk a výpočetní prostředí (nejen) pro statistické výpočty a grafiku. Umožňuje dva režimy práce. Prvním je interaktivní režim, kdy zapíšete zvolené výrazy do konzole a R je okamžitě vyhodnotí a na obrazovku vypíše výsledky a vykreslí obrázky. Druhým režimem je psaní skriptů. Skripty jsou jednoduché programy, které je možné spouštět opakovaně na původních nebo modifikovaných datech.
R je známé svou obecností (jde v něm řešit téměř jakýkoli problém), množstvím funkcí (R pokrývá téměř každé odvětví statistiky, ekonometrie a data science vůbec) a schopností vytvářet prvotřídní grafy v publikační kvalitě. Cenou za tuto obecnost a šíři je však rozsah a jistá složitost tohoto jazyka. O R se často říká, že má “steep learning curve”. V této knize začínáme jazyk R vysvětlovat “od podlahy”. To znamená, že několik prvních kapitol strávíme poměrně nudnými a složitými, ale zároveň důležitými základy, a k zábavnějším věcem se dostaneme až po jejich zvládnutí. Nechceme však, aby vás tyto základy odradily. Proto jsme na samý začátek knihy zařadili tuto kapitolu.
Tato kapitola má dva cíle. Prvním je ukázat vám, že přes všechnu svoji složitost je R správná volba pro každého, kdo to myslí s analýzou dat vážně. Druhým cílem je ukázat vám pár příkladů toho, co budete po přečtení této knihy umět, abyste se měli na co těšit. Stejně jako celá kniha, i tato kapitola je vytvořená přímo v jazyce R pomocí jeho nadstavby Quarto (https://quarto.org/), se kterýou se seznámíte v kapitole 17 Tvorba článků, reportů a prezentací v jazyce R.
Proč právě R
Existuje mnoho dobrých důvodů, proč k analýze dat používat R. R je jedním ze dvou nejpoužívanějších nástrojů v data science, jak ukazuje např. studie, kterou v roce 2023 provedl Rexer Analytics (dalším je Python). Mezi třetinou a dvěmi třetinami respondentů této studie uvedlo, že ve své analytické práci používají R, viz obrázek 1. R je také jejich nejčastějším primárním analytickým nástrojem v akademii a druhým nejčastějím nástrojem v průmyslu, viz obrázek 2. R používají jak výzkumníci na univerzitách, tak i ve velkých komerčních firmách, mimo jiné v Microsoftu, Metě (Facebooku), Googlu, Amazonu, Twitteru, Fordu, Uberu, John Deere, Mozille, The New York Times a dalších firmách, viz např. https://data-flair.training/blogs/r-applications/ nebo https://careerkarma.com/blog/who-uses-r/.

Velké rozšíření užívání R mezi profesionály znamená, že R má velkou komunitu často velmi pokročilých uživatelů. Díky tomu je dostupné velké množství dobrých materiálů, ať už se jedná o knihy, blogy, návody na webu, video tutoriály nebo kurzů. Zároveň to znamená, že vždy najdete někoho, kdo je ochotný vám poradit.
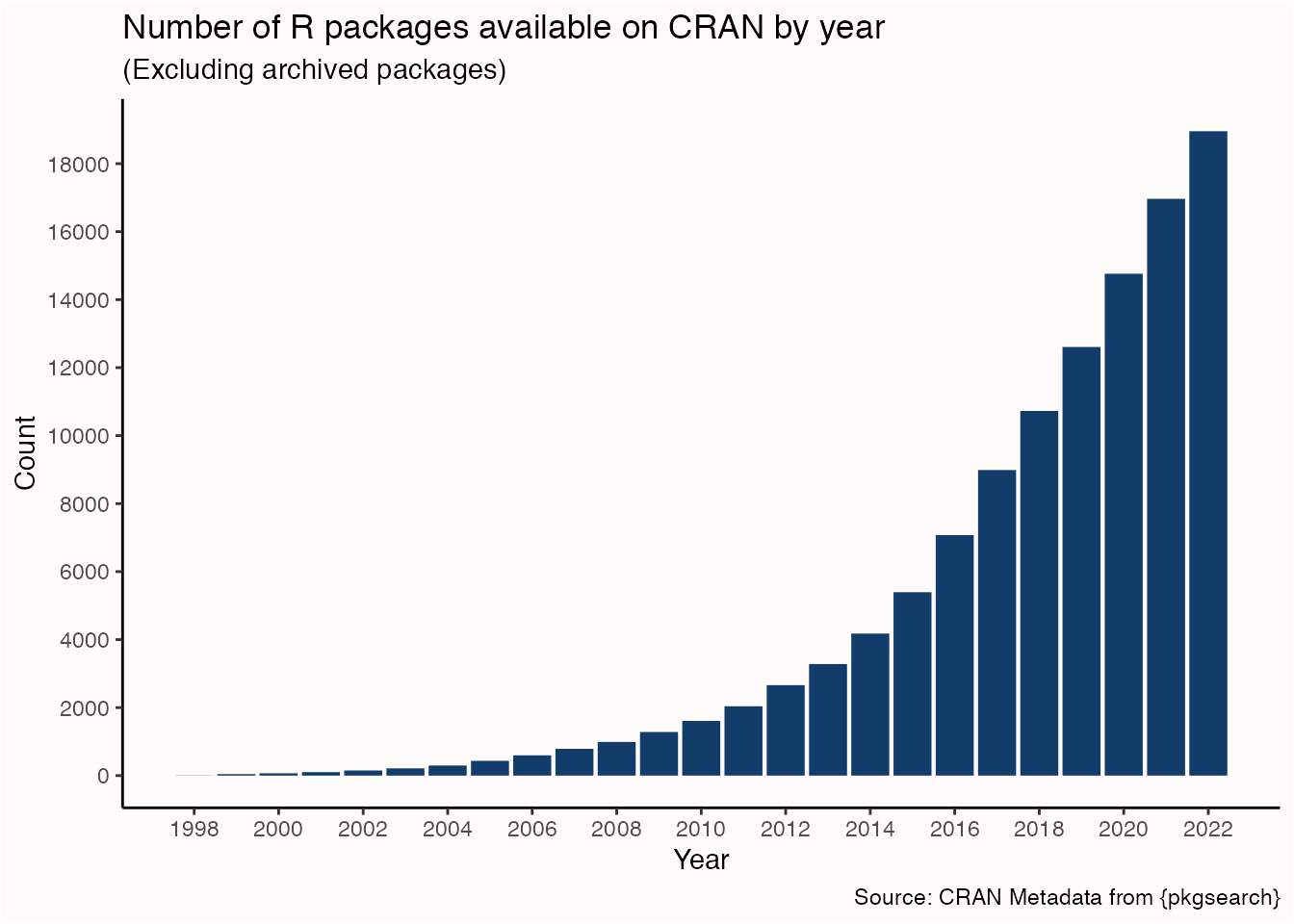
Dalším důsledkem existence velké a rostoucí komunity uživatelů je i to, že R obsahuje velké množství metod pro řešení téměř všech problémů v různých oblastech statistiky, ekonometrie a data science. Většina těchto metod je distribuována formou balíků, které jsou uloženy na jednom z centrálních repositářů. Růst počtu balíků na hlavním repositáři balíků pro R ukazuje obrázek 3. Všechny toto nástroje jsou přitom přítomné v jednom softwaru, takže už nemusíte používat jeden software na přípravu dat, jiný na jejich vizualizaci, jiný na ekonometrii, další na machine learning atd.
R navíc obsahuje velmi mocný, ale relativně jednoduchý programovací jazyk, takže svoji analýzu můžete nejen provést interaktivně, ale i uložit si ji do skriptu a svůj výpočet kdykoli zopakovat stisknutím jednoho tlačítka, a to jak na původních, tak na nových nebo aktualizovaných datech. Díky tomu po vás může kdokoli vaši analýzu zopakovat, což je jedna ze zásad reproducible research. Přitom můžete smíchat výpočet a text a vytvořit “živé dokumenty” (jak ostatně vznikla tato kniha). Svoji práci můžete dále zautomatizovat tak, že si na často opakované úkoly vytvoříte vlastní funkci nebo skript. A pokud vám nějaká metoda v R chybí, můžete ji sami naprogramovat a případně i sdílet s ostatními ve formě nového balíku. (Ačkoli je R poněkud specializovaný programovací jazyk, RedMonk jej ve své analýze popularity programovacích jazyků umístil v roce 2025 R na 12 místo mezi všemi programovacími jazyky, viz obrázek 4.)

Poslední, ale nikoli nejméně významnou výhodou, je to, že R je volně šiřitelný software dostupný pro všechny hlavní operační systémy. To znamená, že jej budete mít k dispozici vždy a všude – a navíc zdarma.
Kromě výhod má R samozřejmě i slabé stránky. Jednou z nich je to, že R je jazyk specializovaný na analýzu dat, nikoli obecný programovací jazyk jako je např. Python, C++ nebo Java. V některých situacích se tedy může stát, že budete potřebovat i nějaký další nástroj. Pro vlastní analýzu dat si však s R naprosto vystačíte.
Často uváděným nedostatkem R je jeho rychlost. Tvrdívá se, že R je poměrně pomalý jazyk. Striktně vzato je to pravda (i když se jeho výkon neustále zlepšuje), ve většině případů to však nevadí, protože funkce, které by v R běžely pomalu, jsou dávno implementované v C++ nebo případně Fortranu a běží rychlostí těchto jazyků, tj. téměř rychlostí strojového kódu.
R také dokáže pracovat pouze s daty, která má uložená v operační paměti počítače. To je však zřídkakdy výrazné omezení. Např. tabulka s milionem pozorování o 50 proměnných bude mít typicky něco kolem 400 MB, takže se do operační paměti běžného počítače pohodlně vejde. R navíc dokáže velmi dobře spolupracovat s databázemi, a tak omezení pamětí počítač hravě obejít.
Překvapivě asi největší nevýhodou R je tak to, že se jedná o poměrně starý jazyk, který prošel dlouhým vývojem, přičemž se na jeho vývoji se podílely tisíce dobrovolníků bez výraznější centrální koordinace. To kromě dobrých vlastností zmíněných výše působí i některé problémy. Názvy funkcí a jejich syntaxe jsou někdy nekonzistenční. Každou věc je možné udělat mnoha různými způsoby a k řešení mnoha problémů existuje několik různých balíků funkcí, takže někdy strávíte nějaký čas rozhodováním, kterou cestu zvolit. Navíc je chování některých funkcí v některých speciálních situacích nečekané, protože to kdysi někomu přišlo jako dobrý nápad. V této knize budeme většinu věcí, kde to je možné, řešit s pomocí balíků ze skupiny tidyverse, které řeší většinu těchto problémů.
Ochutnávka práce s daty
V tomto oddíle začneme se slíbenou ochutnávkou toho, na co se můžete v R těšit. Začneme práci s daty. Nevadí, že nebudete rozumět všemu, co se v této kapitole děje. Věnujte však pozornost tomu, jak jednoduše můžete dostat celkem složitý výsledek.
Jak se v R zachází s datovými soubory, si ukážeme na příkladu data setu diamonds. Nejdříve načteme potřebné balíky pomocí funkce library() a následně i vlastní data.
library(dplyr)
library(purrr)
library(ggplot2)
library(modelsummary)
data("diamonds")Nejprve se na data podíváme. Data set obsahuje údaje o 53 940 diamantech. Pro každý diamant (řádek tabulky) data set uvádí váhu diamantu v karátech, kvalitu jeho řezu (cut), jeho barvu (color), rozměry a cenu (price). R inteligentně vypíše jen několik prvních řádků tabulky.
diamonds# A tibble: 53,940 × 10
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
7 0.24 Very Good I VVS1 62.3 57 336 3.95 3.98 2.47
8 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53
9 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49
10 0.23 Very Good H VS1 59.4 61 338 4 4.05 2.39
# ℹ 53,930 more rowsR umožňuje s daty manipulovat velmi elegantně. Například se můžeme podívat na cenu a váhu u nejlépe zbarvených kamenů. Následující kód nejprve z data setu vyfiltruje kameny se správnou barvou, a pak vybere zvolené sloupce:
diamonds |>
filter(color == "D") |>
select(color, price, carat)# A tibble: 6,775 × 3
color price carat
<ord> <int> <dbl>
1 D 357 0.23
2 D 402 0.23
3 D 403 0.26
4 D 403 0.26
5 D 403 0.26
6 D 404 0.22
7 D 552 0.3
8 D 552 0.3
9 D 552 0.3
10 D 553 0.24
# ℹ 6,765 more rowsData lze i jednoduše řadit. Například je možné se podívat na ty nejdražší kameny. Následující kód setřídí kameny sestupně podle ceny (tj. od nejvyšší po nejnižší cenu):
diamonds |>
arrange(desc(price))# A tibble: 53,940 × 10
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 2.29 Premium I VS2 60.8 60 18823 8.5 8.47 5.16
2 2 Very Good G SI1 63.5 56 18818 7.9 7.97 5.04
3 1.51 Ideal G IF 61.7 55 18806 7.37 7.41 4.56
4 2.07 Ideal G SI2 62.5 55 18804 8.2 8.13 5.11
5 2 Very Good H SI1 62.8 57 18803 7.95 8 5.01
6 2.29 Premium I SI1 61.8 59 18797 8.52 8.45 5.24
7 2.04 Premium H SI1 58.1 60 18795 8.37 8.28 4.84
8 2 Premium I VS1 60.8 59 18795 8.13 8.02 4.91
9 1.71 Premium F VS2 62.3 59 18791 7.57 7.53 4.7
10 2.15 Ideal G SI2 62.6 54 18791 8.29 8.35 5.21
# ℹ 53,930 more rowsJednotlivé operace lze snadno kombinovat do větších celků. Řekněme, že nás např. zajímá, jaká cena nejdražšího kamene pro každou barvu. Nejdříve rozdělíme tabulku do skupin podle barvy kamene, pak každou skupinu setřídíme podle ceny od nejvyšší po nejnižší, a pak vybereme 1. (tj. nejdražší) kámen v každé skupině.
diamonds |>
group_by(color) |>
arrange(desc(price)) |>
slice(1L)# A tibble: 7 × 10
# Groups: color [7]
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 2.19 Ideal D SI2 61.8 57 18693 8.23 8.49 5.17
2 2.02 Very Good E SI1 59.8 59 18731 8.11 8.2 4.88
3 1.71 Premium F VS2 62.3 59 18791 7.57 7.53 4.7
4 2 Very Good G SI1 63.5 56 18818 7.9 7.97 5.04
5 2 Very Good H SI1 62.8 57 18803 7.95 8 5.01
6 2.29 Premium I VS2 60.8 60 18823 8.5 8.47 5.16
7 3.01 Premium J SI2 60.7 59 18710 9.35 9.22 5.64Data lze i jednoduše agregovat. Můžeme např. snadno spočítat průměrnou cenu pro každou barvu kamenů. Opět kameny rozdělíme do skupin podle barvy a pro každou skupinu vypočítáme průměrnou cenu kamenů ve skupině:
diamonds |>
group_by(color) |>
summarise(average_price = mean(price, na.rm = TRUE))# A tibble: 7 × 2
color average_price
<ord> <dbl>
1 D 3170.
2 E 3077.
3 F 3725.
4 G 3999.
5 H 4487.
6 I 5092.
7 J 5324.Kritéria je možné i kombinovat. Následující tabulka obsahuje průměrnou cenu kamene pro kombinaci barvy a řezu:
diamonds |>
group_by(color, cut) |>
summarise(average_price = mean(price, na.rm = TRUE))`summarise()` has regrouped the output.
ℹ Summaries were computed grouped by color and cut.
ℹ Output is grouped by color.
ℹ Use `summarise(.groups = "drop_last")` to silence this message.
ℹ Use `summarise(.by = c(color, cut))` for per-operation grouping
(`?dplyr::dplyr_by`) instead.# A tibble: 35 × 3
# Groups: color [7]
color cut average_price
<ord> <ord> <dbl>
1 D Fair 4291.
2 D Good 3405.
3 D Very Good 3470.
4 D Premium 3631.
5 D Ideal 2629.
6 E Fair 3682.
7 E Good 3424.
8 E Very Good 3215.
9 E Premium 3539.
10 E Ideal 2598.
# ℹ 25 more rowsOchutnávka vizualizace dat
Další část ochutnávky schopností jazyka R se týká vizualizace dat, tj. tvorby grafů. R je schopné vytvářet komplexní grafy v publikační kvalitě – a přitom velmi elegantně a snadno. Všechny grafy v tomto oddíle byly vytvořeny přímo v R nebyly nijak ručně upravovány. Do webové i PDF verze knihy je upravilo samo R.
I nadále budeme pracovat s tabulkou diamonds. Nejdříve ze všeho by nás mohlo zajímat, jak časté jsou různé ceny diamantů. K tomuto účelu se obvykle používá histogram, viz obrázek 5, vytvořený následujícím kódem:
diamonds |>
ggplot(aes(price)) +
geom_histogram() +
theme_bw()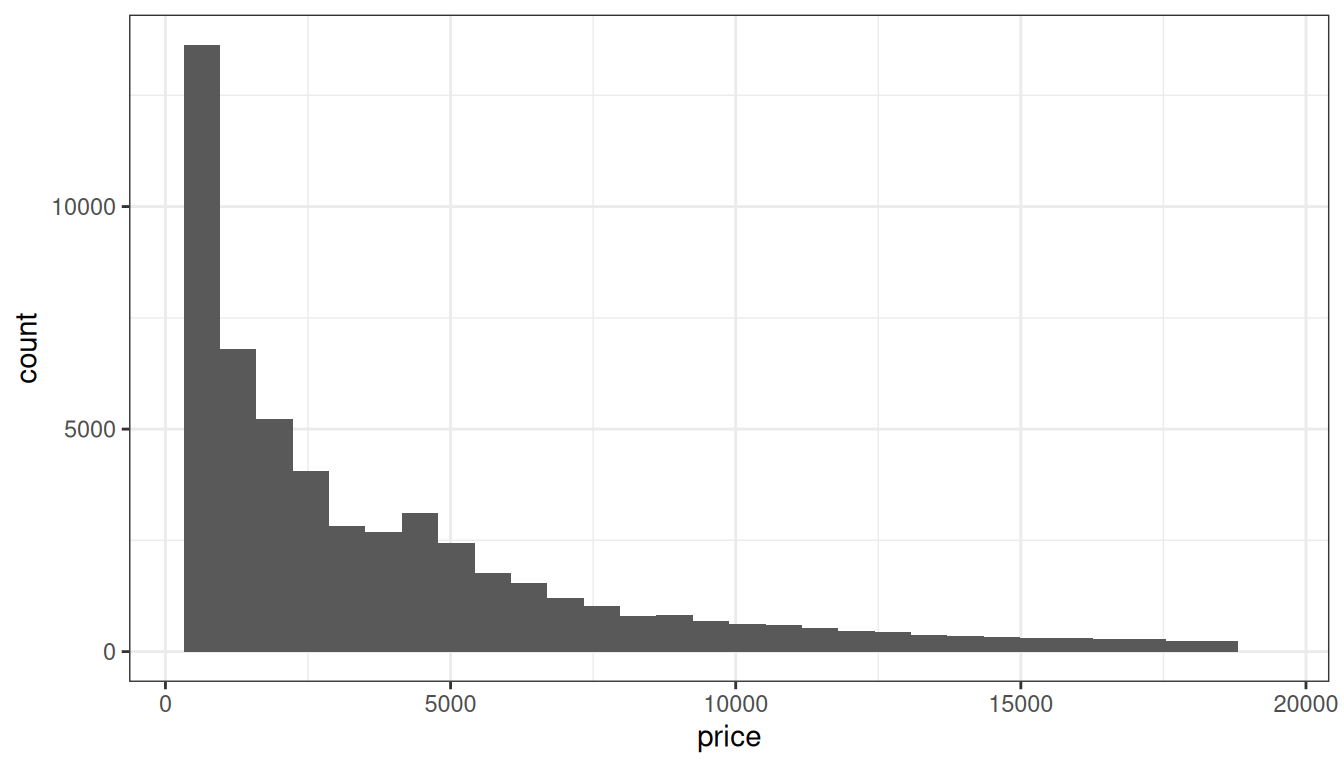
Výsledek není překvapivý – čím vyšší cena, tím méně kamenů se za ni prodává. Zajímavější otázka však je, zda se ceny liší podle kvality řezu kamene. Zde nám histogram nepomůže. Existuje však celá řada jiných možností. První z nich je tzv. boxplot, viz obrázek 6. Výška každé krabice ukazuje mezikvartilovou vzdálenost, tlustá vodorovná čára mediánovou cenu a jednotlivé tečky odlehlá pozorování. Histogram byl vytvořen takto:
diamonds |>
ggplot(aes(cut, price)) +
geom_boxplot() +
theme_bw()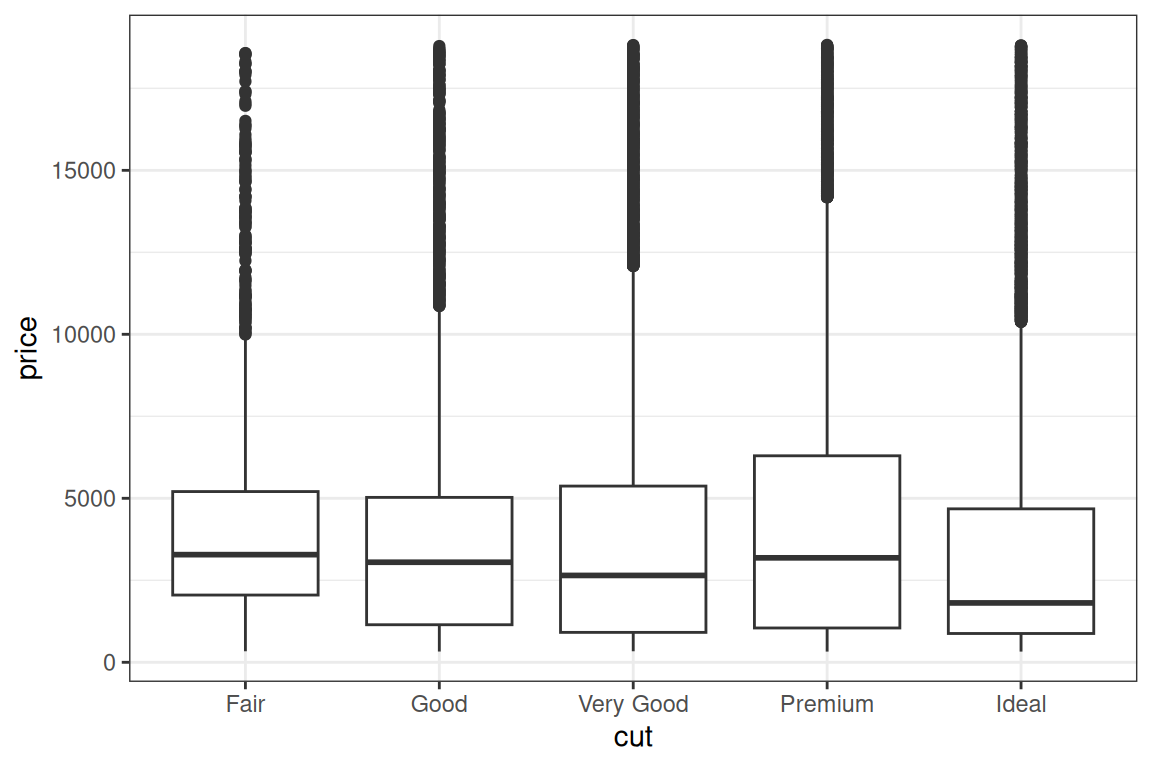
Výsledek je překvapivý: zdaleka neplatí, že dokonalejší řez znamená vyšší ceny. Možná je to však tím, že boxploty neukazují celý tvar statistického rozdělení, ale jen pár vybraných charakteristik tohoto rozdělení. Celé rozdělení můžeme zobrazit např. pomocí odhadu jádrové hustoty. Abychom mohli pozorovat rozdíly mezi jednotlivými typy řezů, částečně grafy hustot zprůhledníme, viz obrázek 7 vytvořený takto:
diamonds |>
ggplot(aes(price, fill = cut)) +
geom_density(alpha = 0.35) +
theme_bw()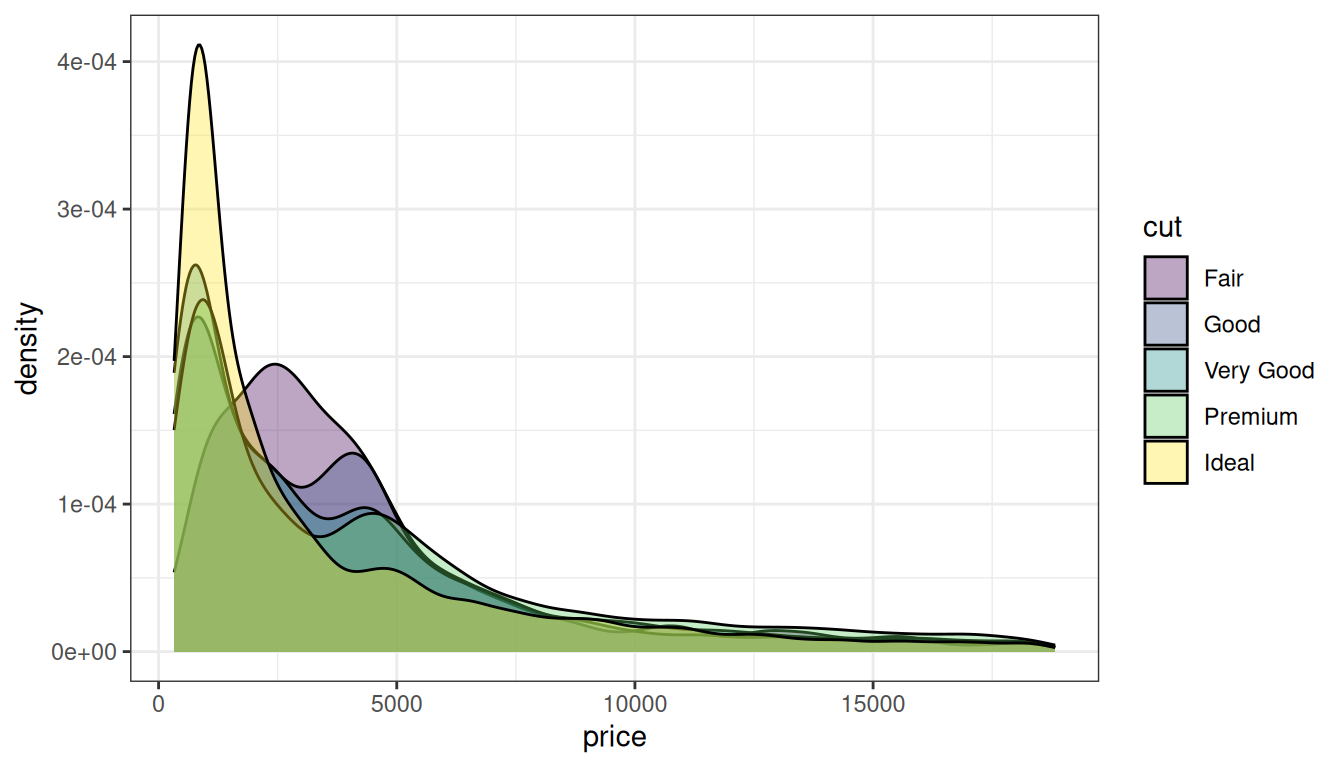
Nejzajímavější otázky se však vždy týkají vztahů mezi veličinami. Řekněme, že nás například zajímá, jak souvisí cena kamene s jeho váhou. Takový vztah dokáže pěkně zobrazit scatter plot, viz obrázek 8. Vlastní trend vztahu zobrazíme snadno přidáním regresní přímky. V tomto grafu navíc nebudeme líní a změníme nápisy v grafu do češtiny:
diamonds |>
ggplot(aes(carat, price)) +
geom_point(alpha = 0.05) +
geom_smooth(method = lm) +
xlab("váha") + ylab("cena") +
ylim(0, 20000) +
theme_bw()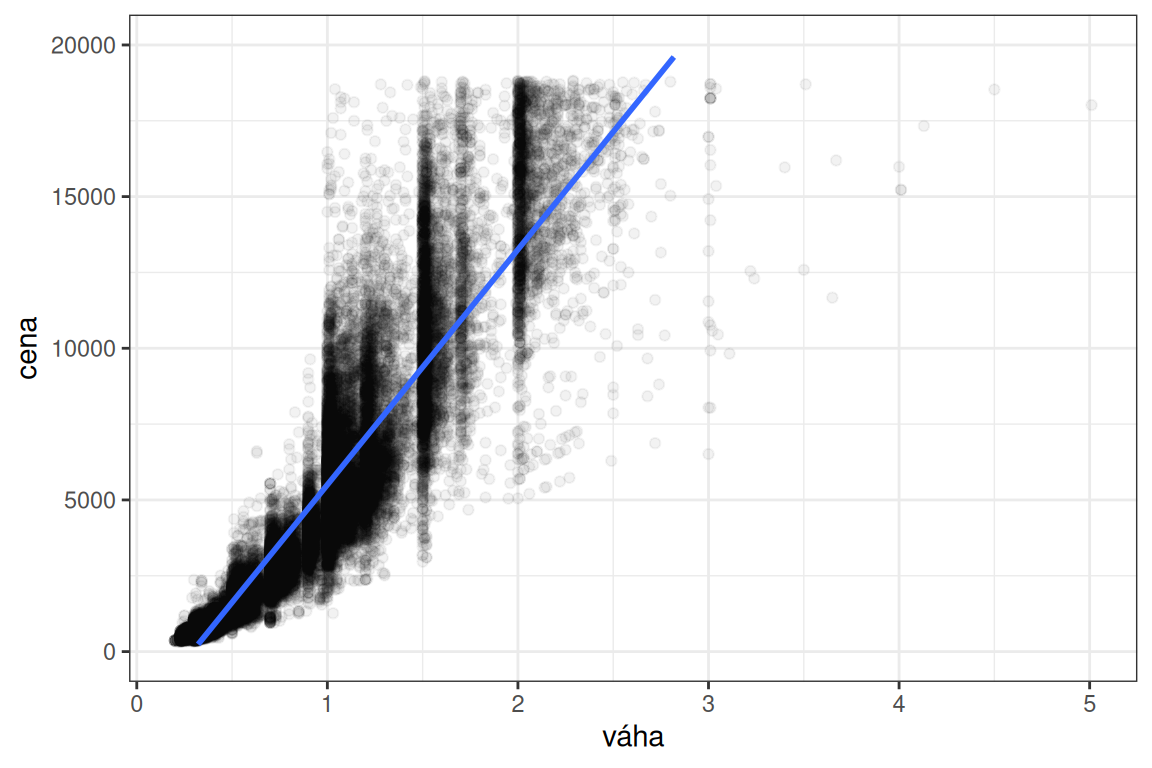
Mohlo by nás ovšem zajímat, zda je vztah mezi cenou a váhou kamene stejný bez ohledu na barvu kamene. Abychom toho dosáhli, musíme do grafu přidat další rozměr. Na první pohled se zdá, že budeme potřebovat třírozměrný graf. Takové grafy jsou však velmi nepřehledné. R má v zásobě něco lepšího: umožní nám přidáním jednoho řádku do předchozího kódu rozdělit kameny do dílčích grafů, viz obrázek 9:
diamonds |>
ggplot(aes(carat, price)) +
geom_point(alpha = 0.05) +
geom_smooth(method = lm) +
facet_wrap(~ color) +
xlab("váha") + ylab("cena") +
ylim(0, 20000) +
theme_bw()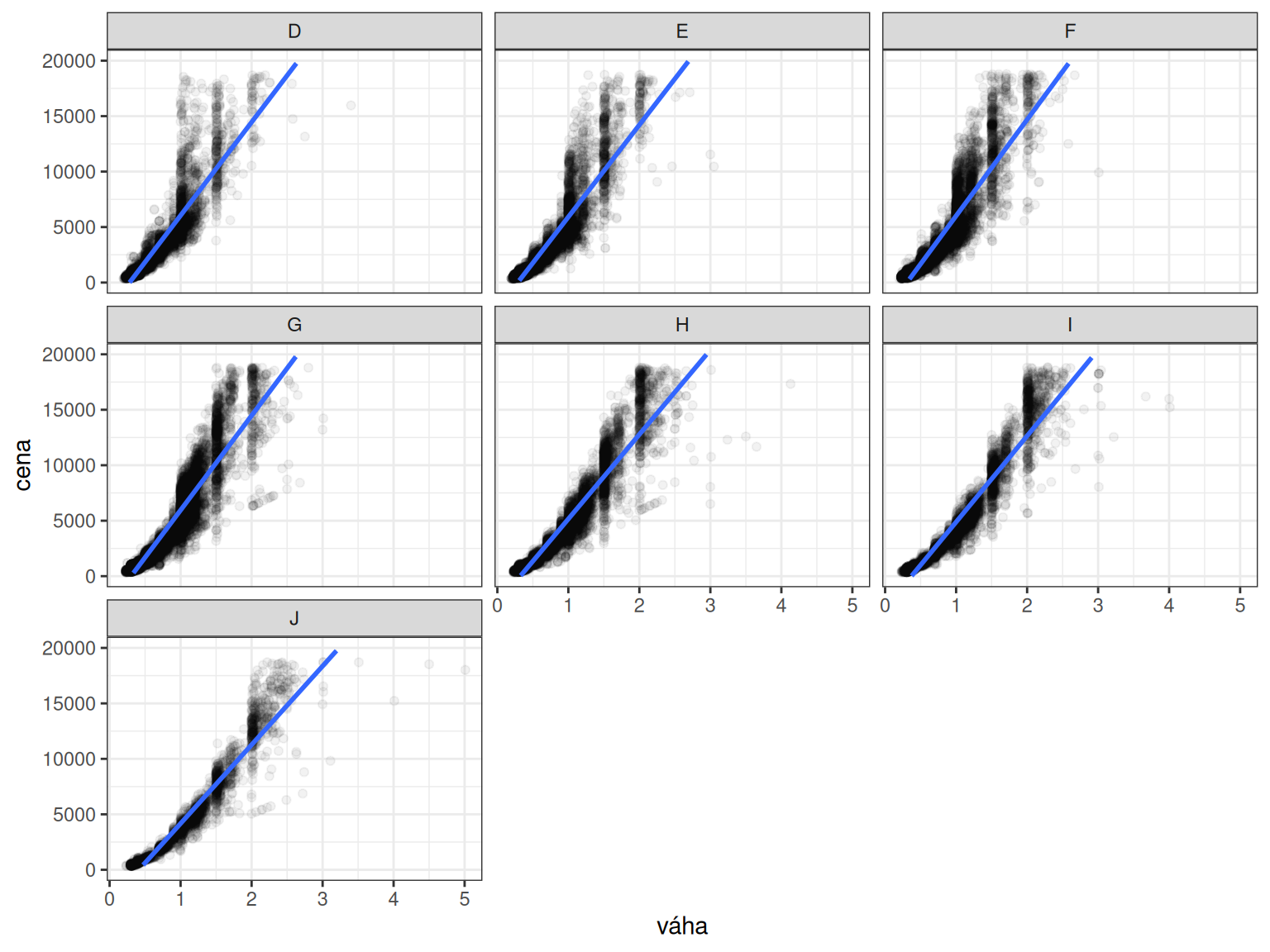
Ochutnávka regresní analýzy
Nejdůležitějším nástrojem analýzy dat je beze sporu regrese. R obsahuje nástroje pro velmi pokročilé regresní techniky, zde se však podíváme na jednoduchou lineární regresi. Pokusíme se vysvětlit, jak závisí cena diamantů na jejich charakteristikách, jako jsou váha, typ řezu, barva a velikost. Začneme tím, že odhadneme jednodušší model, který je popsaný rovnicí:
\[\textrm{price} = \beta_0 + \beta_1 \textrm{ carat} + \beta_2 \textrm{ color} + \beta_3 \textrm{ cut} + \beta_4 \textrm{ table} + \varepsilon.\]
Proměnné cut a color jsou kategoriální. R pro ně automaticky připraví potřebné umělé proměnné. Nejdříve však tyto faktory převedeme na ne-ordinální, protože tak bude mít odhad modelu jednodušší interpretaci:
diamonds <- mutate(diamonds,
color = factor(color, ordered = FALSE),
cut = factor(cut, ordered = FALSE))Vlastní model odhadneme takto:
model <- price ~ carat + color + cut + table
em <- lm(model, diamonds)
summary(em) # vypíše výsledek regrese
Call:
lm(formula = model, data = diamonds)
Residuals:
Min 1Q Median 3Q Max
-17351.4 -751.5 -84.3 544.7 12226.7
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2471.895 201.814 -12.248 < 2e-16 ***
carat 8192.894 13.962 586.784 < 2e-16 ***
colorE -89.573 22.625 -3.959 7.53e-05 ***
colorF -72.834 22.772 -3.198 0.00138 **
colorG -106.719 22.070 -4.836 1.33e-06 ***
colorH -734.724 23.702 -30.999 < 2e-16 ***
colorI -1077.256 26.574 -40.537 < 2e-16 ***
colorJ -1909.932 32.863 -58.118 < 2e-16 ***
cutGood 1120.648 41.223 27.185 < 2e-16 ***
cutVery Good 1495.866 38.273 39.084 < 2e-16 ***
cutPremium 1437.307 37.774 38.050 < 2e-16 ***
cutIdeal 1742.944 38.589 45.167 < 2e-16 ***
table -21.951 3.366 -6.521 7.05e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1432 on 53927 degrees of freedom
Multiple R-squared: 0.8713, Adjusted R-squared: 0.8712
F-statistic: 3.041e+04 on 12 and 53927 DF, p-value: < 2.2e-16Často potřebujeme porovnat odhady různých specifikací modelu. Například by mohlo být zajímavé nahradit proměnnou table jiným měřítkem velikosti kamene. Zde odhadneme původní model a čtyři jeho alternativy:
model <- list(
model,
model |> update(. ~ . - table + depth),
model |> update(. ~ . - table + x),
model |> update(. ~ . - table + y),
model |> update(. ~ . - table + z)
)
em <- map(model, ~ lm(., data = diamonds))Výsledky porovnáme v tabulce 2.
modelsummary(em,
fmt = 3,
stars = c("*" = 0.1, "**" = 0.05, "***" = 0.01),
gof_omit = "IC|Lik|F|RMSE")| (1) | (2) | (3) | (4) | (5) | |
|---|---|---|---|---|---|
| * p < 0.1, ** p < 0.05, *** p < 0.01 | |||||
| (Intercept) | -2471.895*** | -1458.123*** | 965.254*** | -1622.037*** | -1055.518*** |
| (201.814) | (297.291) | (101.796) | (77.707) | (82.654) | |
| carat | 8192.894*** | 8183.774*** | 11041.864*** | 9492.338*** | 9725.135*** |
| (13.962) | (13.889) | (58.130) | (42.709) | (43.207) | |
| colorE | -89.573*** | -91.842*** | -97.617*** | -92.161*** | -93.096*** |
| (22.625) | (22.621) | (22.115) | (22.416) | (22.342) | |
| colorF | -72.834*** | -72.405*** | -52.582** | -61.845*** | -62.069*** |
| (22.772) | (22.767) | (22.262) | (22.564) | (22.488) | |
| colorG | -106.719*** | -100.884*** | -107.555*** | -104.873*** | -101.694*** |
| (22.070) | (22.064) | (21.568) | (21.862) | (21.789) | |
| colorH | -734.724*** | -727.123*** | -761.310*** | -744.271*** | -740.949*** |
| (23.702) | (23.703) | (23.172) | (23.484) | (23.404) | |
| colorI | -1077.256*** | -1070.565*** | -1138.112*** | -1104.141*** | -1100.604*** |
| (26.574) | (26.577) | (26.004) | (26.344) | (26.250) | |
| colorJ | -1909.932*** | -1902.818*** | -1992.011*** | -1945.948*** | -1939.625*** |
| (32.863) | (32.865) | (32.165) | (32.581) | (32.463) | |
| cutGood | 1120.648*** | 1067.103*** | 1184.977*** | 1195.907*** | 1058.334*** |
| (41.223) | (41.910) | (40.300) | (40.889) | (40.738) | |
| cutVery Good | 1495.866*** | 1438.418*** | 1576.936*** | 1596.985*** | 1428.780*** |
| (38.273) | (39.451) | (37.283) | (37.851) | (37.721) | |
| cutPremium | 1437.307*** | 1342.996*** | 1545.595*** | 1509.262*** | 1316.495*** |
| (37.774) | (39.854) | (36.970) | (37.474) | (37.444) | |
| cutIdeal | 1742.944*** | 1724.554*** | 1873.955*** | 1880.359*** | 1706.301*** |
| (38.589) | (38.768) | (36.460) | (37.001) | (36.909) | |
| table | -21.951*** | ||||
| (3.366) | |||||
| depth | -35.979*** | ||||
| (4.602) | |||||
| x | -1232.425*** | ||||
| (24.372) | |||||
| y | -566.150*** | ||||
| (17.492) | |||||
| z | -1082.736*** | ||||
| (28.780) | |||||
| Num.Obs. | 53940 | 53940 | 53940 | 53940 | 53940 |
| R2 | 0.871 | 0.871 | 0.877 | 0.874 | 0.874 |
| R2 Adj. | 0.871 | 0.871 | 0.877 | 0.874 | 0.874 |