library(tidyverse)
library(sloop)13 Manipulace s daty s nástroji z balíku dplyr
Balík tidyr obsahuje nástroje, které umožňují uživateli velmi jednoduše měnit organizační strukturu tabulky a provádět některé operace spojené s čištěním dat. Praktická práce s daty však vyžaduje více a to nejen v oblasti čištění dat. Typicky potřebujete subsetovat pozorování nebo proměnné, modifikovat nebo vytvářet nové proměnné a agregovat pozorování. Data také obvykle nejsou pouze v jediném zdroji – tabulce. Je tedy nutné tabulky různými způsoby slučovat. Pro tyto úkoly existuje v R balík dplyr – součást tidyverse. (Text odpovídá balíku dplyr ve verzi 1.1.2.)
V této lekci se naučíte:
- subsetovat pozorování a proměnné
- vytvářet nové a modifikovat stávající proměnné
- vytvářet agregované hodnoty z více pozorování
- provádět jednotlivé operace zvlášť pro různé skupiny pozorování
- spojovat (join) a slučovat (bind) tabulky
- a další…
Funkcionalitu, kterou Vám poskytuje dplyr můžete získat i s nástroji base R. Nicméně používání dplyr vám přinese snadnější interaktivní práci, vyšší rychlost (zejména pro “středně velká” data) a srozumitelnost kódu. Výhodou je i kompatibilita API s ostatními částmi tidyverse.
Pro uživatele, kteří hodlají pracovat s velkými objemy dat (včetně Big Data), je důležitá i další možnost, kterou dplyr nabízí. Kód napsaný v dplyr může být vykonán s pomocí různých backendů – nástrojů, které provádí samotnou práci s daty. Vedle základního (defaultního) backendu je k dispozici balík dtplyr, který umožňuje vykonat kód s pomocí tříd a funkcí data.table, nebo balík dbplyr, který umožňuje kód vnitřně přeložit do SQL a nechat ho vykonat vzdálenou databázi. Uživatelé, kteří mají k dispozici speciální infrastrukturu pro analýzu Big Data, mohou podobně využít i backend pro Apache Spark z balíku sparklyr. Možnost změnit backend dělá z dplyr mocný nástroj, protože umožňuje jednoduché škálování úloh.
dplyr má implementováno mnoho dalších pokročilých funkcí. Obsahem této lekce jsou však spíše základy, které nicméně pokrývají vše, co je běžně potřeba pro interaktivní práci s daty. O dplyr platí více než o všech jiných balících zmíněných v celém kurzu, že je stále ve velmi aktivním vývoji. Dochází k častým a hlubokým změnám jak v API, tak v backendu (respektive backendech). Tato kapitola byla připravována s požitím verze 1.0.0. Udržujte svůj dplyr aktualizovaný. Určitě je také doporučeníhodné sledovat vývoj a čas od času si projít seznam zahrnutých funkcí.
Co je obsahem balíku dplyr?
Hadley Wickham používá pro označení skupin funkcí slovní druhy. Základním slovním druhem v balíku dplyr je sloveso. dplyr obsahuje slovesa (funkce), které pracují s jednou tabulkou (např. vyber, seřaď, nebo agreguj), nebo (primárně) dvěma tabulkami (spoj a sluč).
Samostatnou funkcionalitou je schopnost dplyr spouštět slovesa nejen nad celou jednou tabulkou, ale také nad jejími částmi (skupinami pozorování). Takové operace se nazývají “zgrupované”.
Obsah přednášky:
- slovesa (funkce) pracující s jednou tabulkou
- zgrupované operace
- slovesa (funkce) pracující se dvěma (nebo více) tabulkami
Pro demonstraci funkcí z balíku dplyr jsou použita data z balíku nycflights13 – údaje o letech z/do NYC v roce 2013:
library(nycflights13)Ve většině příkladů budeme používat tabulku planes s údaji o letadlech, která do NYC létala:
planes %>% print# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,312 more rowsPoznámka
dplyr je pokročilou evolucí balíku plyr. Balík plyr je stále v závislostech některých balíků, které využívají jeho služeb. To může (a pravděpodobně bude) vyvolávat konflikty, kterým se dá čelit jednoduchým způsobem – vždy nejprve načíst plyr a až následně dplyr. Pokud načtete balíky v opačném pořadí, tak Vám dplyr vypíše upovídané varování. (Tento problém se v čase zmenšuje. Stále však taková situace může reálně nastat.)
13.1 Slovesa pracující s jednou tabulkou
Výběr řádků (pozorování)
Základní funkcí, která umožňuje výběr řádků je filter(). Podobně jako většina funkcí z balíku dplyr má extrémně jednoduchou syntax:
filter(.data, ...)Vstupem funkce je tabulka (.data) a jeden nebo více logických predikátů. Výstupem funkce je podmnožina řádků, která splňuje všechny zadané predikáty.
Například se můžeme chtít podívat na letadla, která vyrobil Airbus nebo Boeing a mají více než dva motory:
planes %>%
filter(manufacturer %in% c("AIRBUS INDUSTRIE","BOEING"), engines > 2)# A tibble: 2 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N281AT NA Fixed wing multi … AIRBUS INDU… A340… 4 375 NA Turbo…
2 N670US 1990 Fixed wing multi … BOEING 747-… 4 450 NA Turbo…Vybrány byly pouze řádky splňující všechny podmínky najednou. Následující volání filter(), které spojuje dvě výše použité podmínky do jedné logickým AND (&) proto vrátí stejný výsledek:
planes %>%
filter(manufacturer %in% c("AIRBUS INDUSTRIE","BOEING") & engines > 2)# A tibble: 2 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N281AT NA Fixed wing multi … AIRBUS INDU… A340… 4 375 NA Turbo…
2 N670US 1990 Fixed wing multi … BOEING 747-… 4 450 NA Turbo…Podmínky použité ve funkci filter() musí po vyhodnocení vracet logické hodnoty TRUE/FALSE. Ve filter() tedy můžeme používat funkce, které vracejí logickou hodnotu.
Například nás mohou zajímat všechna letadla z rodiny A340. Budeme tedy chtít vybrat všechny řádky, u nichž proměnná model začíná na “A340”. Kromě balíku dplyr budeme potřebovat i stringr:
library(stringr)
planes %>%
filter(str_detect(model,"^A340"))# A tibble: 1 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N281AT NA Fixed wing multi … AIRBUS INDU… A340… 4 375 NA Turbo…Je možné používat i funkce, které nevracejí logické hodnoty. V takové případě je však nutné jejich výsledek na logickou proměnou transformovat. Řekněme, že by nás zajímala letadla, kde na jeden motor připadá méně než 10 sedadel:
planes %>%
filter(seats/engines < 10)# A tibble: 39 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N201AA 1959 Fixed wing singl… CESSNA 150 1 2 90 Recip…
2 N202AA 1980 Fixed wing multi… CESSNA 421C 2 8 90 Recip…
3 N315AT NA Fixed wing singl… JOHN G HESS AT-5 1 2 NA 4 Cyc…
4 N347AA 1985 Rotorcraft SIKORSKY S-76A 2 14 NA Turbo…
5 N350AA 1980 Fixed wing multi… PIPER PA-3… 2 8 162 Recip…
6 N364AA 1973 Fixed wing multi… CESSNA 310Q 2 6 167 Recip…
7 N365AA 2001 Rotorcraft AGUSTA SPA A109E 2 8 NA Turbo…
8 N376AA 1978 Fixed wing singl… PIPER PA-3… 1 7 NA Recip…
9 N377AA NA Fixed wing singl… PAIR MIKE E FALC… 1 2 NA Recip…
10 N378AA 1963 Fixed wing singl… CESSNA 172E 1 4 105 Recip…
# ℹ 29 more rowsVe speciálních případech je užitečné vybírat řádky ne podle splnění určitých podmínek, ale podle jiných kritérií. Pro tyto případy je v balíku dplyr obsažena funkce slice(). (Poznámka: zde diskutované funkce slice() získala s verzí dplyr mnoho nových úloh a rolí. V předchozích verzích umožňovala pouze výběr řádku na základě jeho čísla.)
V základní variantě přijímá slice() číslo řádku, nebo jejich rozsah, který má být vybrán:
planes %>%
slice(1L)# A tibble: 1 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi … EMBRAER EMB-… 2 55 NA Turbo…planes %>%
slice(1L:5L)# A tibble: 5 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi … EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi … EMBRAER EMB-… 2 55 NA Turbo…planes %>%
slice(c(1,2:5))# A tibble: 5 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi … EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi … EMBRAER EMB-… 2 55 NA Turbo…Poslední příklad ukazuje, že (a) číslo řádku nemusí být nutně zadáno jako integer (L) a (b) vstupem může být vektor vytvořený funkcí c().
Speciální variantou slice() jsou varianty slice_head(), slice_tail(), slice_min() a slice_max(). Ty vrací n prvních/posledních řádků respektive n řádků s nejnižší/nejvyzšší hodnotou:
planes %>%
slice_head(n = 5)# A tibble: 5 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi … EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi … EMBRAER EMB-… 2 55 NA Turbo…planes %>%
slice_max(seats, n = 1)# A tibble: 1 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N670US 1990 Fixed wing multi … BOEING 747-… 4 450 NA Turbo…Počet řádků nemusí být určen jako absolutní číslo, ale je možné ho specifikovat v parametru prop jako podíl všech pozorování:
planes %>%
slice_head(prop = 0.001)# A tibble: 3 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi … EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo…Toto volání vrátí 0,1 % pozorování ze začátku tabulky.
Poslední speciální variantou slice() je slice_sample(), která umožňuje provést náhodný výběr pozorování z tabulky. (V předchozích verzích dplyr k tomu sloužily funkce sample_*().) Počet řádků v náhodném výběru může být stanoveno opět absolutním číslem (parametr n) nebo podílem (parametr prop). Funkce umožňuje používat ve výběru váhy (parametr weight_by) a zvolit výběr s nahrazením (parametr replace).
Obecně platí, že pokud používáte v kódu náhodné výběry, potom byste měli myslet na replikovatelnost Vašeho kódu. Minimálním nezbytným krokem je vždy nastavit tzv. seed pomocí funkce set.seed().
Aplikace
V souboru sipv_training.RData najdete tabulku (ispv), která mimikují strukturu dat z Informačního systému o průměrném výdělku (ISPV). Data v ní ale nejsou vyčištěná.
load("data/dplyr/ispv_training.RData")
print(ispv)# A tibble: 1,000 × 36
ICO IDZAM ROKNAR POHLAVI STOBC VZDELANI INVALD MISTOVP CZICSE CZISCO
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 9a1b22d03ab… 480 1985 1 CZ M Z CZ0100 1111 54141
2 b545141626d… 1639 1965 1 CZ H Z CZ0323 1111 82197
3 3fce46ceb84… 7854… 1961 1 CZ T Z CZ0427 1112 31155
4 55d7abb8e1c… 1163… 1956 2 CZ T Z CZ0100 1111 91122
5 902c3df93cd… 2077… 1983 2 CZ H Z CZ0513 1111 24339
6 9d30f64c730… 0525… 1983 1 CZ E Z CZ0806 1112 13213
7 7f9356f49ab… 399 1968 2 CZ T Z CZ0803 1112 81899
8 a1952d7be7a… 2556… 1982 1 CZ C Z CZ0100 1112 81720
9 0530aa024e6… 55310 1981 2 CZ V Z CZ0204 1111 43220
10 13b3afe68f8… 12553 1980 1 CZ H Z CZ0805 1111 44125
# ℹ 990 more rows
# ℹ 26 more variables: VEDOUCI <chr>, KONTOPD <chr>, DOBAZAM <chr>,
# EVIDDNY <chr>, KONECEP <chr>, FONDSTA <chr>, FONDSJE <chr>, ODPRACD <chr>,
# PRESCAS <chr>, ABSCELK <chr>, ABSPLAC <chr>, ABSDOVOL <chr>,
# ABSNEMOC <chr>, ABSNEMZ <chr>, MZDA <chr>, POPRAV <chr>, PONEPRAV <chr>,
# PRIPPCAS <chr>, PRIPLAT <chr>, NAHRADY <chr>, NAHRNEMZ <chr>,
# POHOTOV <chr>, PRUMVYD <chr>, ISCED <chr>, OBORVZD <chr>, year <chr>Vyberte řádky, kde je kód pro vzdělání (VZDELANI) nevalidní – tj. není ani chybějící hodnota (NA) a ani velké písmeno.
ispv %>%
filter(!(VZDELANI %in% LETTERS), !is.na(VZDELANI))# A tibble: 11 × 36
ICO IDZAM ROKNAR POHLAVI STOBC VZDELANI INVALD MISTOVP CZICSE CZISCO
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 20bd45a7c16… 0034… 1986 2 CZ - Z CZ0100 1111 81602
2 2e9c2ea8308… 99 1971 2 CZ - Z CZ0203 1112 52232
3 28c9bfcdd42… 1800… 1975 Z CZ - Z CZ0209 1111 91129
4 81072464e40… 0025… 1958 1 CZ - Z CZ0413 1112 54141
5 29f00871098… 2838 1958 2 CZ - Z CZ0635 1112 81319
6 79278119b40… 1251 1994 Z CZ - Z CZ0100 1111 54142
7 65e1f2c5761… 11233 1987 1 CZ - Z CZ0202 1111 12212
8 11b20229df9… Z180 1986 2 cz - Z CZ0642 1111 83322
9 3b94383a0fc… 3837 1964 Z CZ - Z CZ0312 1112 26312
10 6abd43fb86d… 0100… 1978 M CZ h Z CZ0532 1112 81609
11 5bb89f648df… 8717… 1983 1 CZ - Z CZ0422 1111 24240
# ℹ 26 more variables: VEDOUCI <chr>, KONTOPD <chr>, DOBAZAM <chr>,
# EVIDDNY <chr>, KONECEP <chr>, FONDSTA <chr>, FONDSJE <chr>, ODPRACD <chr>,
# PRESCAS <chr>, ABSCELK <chr>, ABSPLAC <chr>, ABSDOVOL <chr>,
# ABSNEMOC <chr>, ABSNEMZ <chr>, MZDA <chr>, POPRAV <chr>, PONEPRAV <chr>,
# PRIPPCAS <chr>, PRIPLAT <chr>, NAHRADY <chr>, NAHRNEMZ <chr>,
# POHOTOV <chr>, PRUMVYD <chr>, ISCED <chr>, OBORVZD <chr>, year <chr>Výběr sloupců (proměnných)
Pro výběr sloupců slouží funkce select(). Syntax je podobná jako v případě filter():
select(.data, ...)Do select() vstupuje tabulka a identifikace sloupců, které mají být vybrány. Například:
planes %>%
select(tailnum, manufacturer)# A tibble: 3,322 × 2
tailnum manufacturer
<chr> <chr>
1 N10156 EMBRAER
2 N102UW AIRBUS INDUSTRIE
3 N103US AIRBUS INDUSTRIE
4 N104UW AIRBUS INDUSTRIE
5 N10575 EMBRAER
6 N105UW AIRBUS INDUSTRIE
7 N107US AIRBUS INDUSTRIE
8 N108UW AIRBUS INDUSTRIE
9 N109UW AIRBUS INDUSTRIE
10 N110UW AIRBUS INDUSTRIE
# ℹ 3,312 more rowsPříklad ukazuje první a základní možnost, jak identifikovat sloupec – a to jeho jménem. select() však umožňuje specifikovat sloupec i pomocí čísla pozice.
Následující volání funkce select() tak vrací stejný výsledek, jako tomu byl v případě identifikace sloupců jejich jménem.
planes %>%
select(1,4)# A tibble: 3,322 × 2
tailnum manufacturer
<chr> <chr>
1 N10156 EMBRAER
2 N102UW AIRBUS INDUSTRIE
3 N103US AIRBUS INDUSTRIE
4 N104UW AIRBUS INDUSTRIE
5 N10575 EMBRAER
6 N105UW AIRBUS INDUSTRIE
7 N107US AIRBUS INDUSTRIE
8 N108UW AIRBUS INDUSTRIE
9 N109UW AIRBUS INDUSTRIE
10 N110UW AIRBUS INDUSTRIE
# ℹ 3,312 more rowsplanes %>% names[1] "tailnum" "year" "type" "manufacturer" "model"
[6] "engines" "seats" "speed" "engine" Funkce select() a speciální funkce
Při identifikaci sloupců je možné využít speciální funkce. Některé fungují pouze “uvnitř” select() a některých dalších funkcí z tidyverse.
První taková funkce je :. Umožňuje specifikovat rozsah sloupců, místo vypisování všech prvků. Všechny následující volání tak vrací stejný výsledek:
planes %>%
select(1,2,3,4,8)
planes %>%
select(tailnum, year, type, manufacturer, speed)
planes %>%
select(1:4, 8)
planes %>%
select(tailnum:manufacturer, speed)Další speciální funkcí je - (mínus). Tato funkce umožňuje “negativní” výběr. Při jejím použití není sloupec zahrnut, ale naopak vypuštěn:
planes %>%
select(-tailnum, -year, -type, -manufacturer, -speed)# A tibble: 3,322 × 4
model engines seats engine
<chr> <int> <int> <chr>
1 EMB-145XR 2 55 Turbo-fan
2 A320-214 2 182 Turbo-fan
3 A320-214 2 182 Turbo-fan
4 A320-214 2 182 Turbo-fan
5 EMB-145LR 2 55 Turbo-fan
6 A320-214 2 182 Turbo-fan
7 A320-214 2 182 Turbo-fan
8 A320-214 2 182 Turbo-fan
9 A320-214 2 182 Turbo-fan
10 A320-214 2 182 Turbo-fan
# ℹ 3,312 more rowsSpeciální funkce je možné kombinovat – je například možné vypustit sloupce identifikované rozsahem (:):
planes %>%
select(-tailnum:-manufacturer, -speed)# A tibble: 3,322 × 4
model engines seats engine
<chr> <int> <int> <chr>
1 EMB-145XR 2 55 Turbo-fan
2 A320-214 2 182 Turbo-fan
3 A320-214 2 182 Turbo-fan
4 A320-214 2 182 Turbo-fan
5 EMB-145LR 2 55 Turbo-fan
6 A320-214 2 182 Turbo-fan
7 A320-214 2 182 Turbo-fan
8 A320-214 2 182 Turbo-fan
9 A320-214 2 182 Turbo-fan
10 A320-214 2 182 Turbo-fan
# ℹ 3,312 more rowsVýsledné tabulky jsou pochopitelně shodné.
Obě tyto speciální funkce vyžadují přesnou specifikaci jména nebo pozice sloupce. V reálném životě občas pracujeme s poněkud vágnějším zadáním. Mohli bychom chtít například vybrat všechny sloupce, které obsahují informace o motorech. Ty jsou v tabulce planes dva engine (typ motoru) a engines (počet motorů).
První možností je samozřejmě možné použít následující volání a vybrat sloupce jejich výčtem:
planes %>%
select(engine,engines)To však není praktické v případě, že pracujeme s větším množstvím sloupců, jejichž názvy jsou systematické. V tom případě je užitečné sáhnout po select helpers (funkcích pomocníčcích chcete-li). dplyr jich nabízí hned několik:
starts_with()vybírá sloupce, jejichž jméno začíná na řetězec, který je argumentem funkcestarts_with()ends_with()vybírá sloupce, jejichž jméno končí na řetězec, který je argumentem funkceends_with()contains()vybírá sloupce, jejichž jméno obsahuje řetězec, který je argumentem funkcecontains()matches()vybírá sloupce, jejichž jméno odpovídá zadanému regulárnímu výrazunum_range()slouží pro výběr sloupců, jejichž jméno je tvořeno kombinací řetězce a čísla – napříkladtrial_1,trial_2,…everything()vrací všechny sloupcelast_col()vrací poslední sloupec
Pro výběr proměnných se vztahem k motorům lze použít hned tři funkce:
planes %>%
select(starts_with("engine"))
planes %>%
select(contains("engine"))
planes %>%
select(matches("^engine"))První a třetí varianta vybere všechny sloupce, které začínají na “engine”. Druhé variantě postačí k výběru, že řetězec “engine” se vyskytuje kdekoliv ve jméně sloupce.
Další select helpers umožňují vybrat sloupce podle jmen ze vstupního vektoru.
all_of()vrátí tabulku s vybranými sloupci pouze tehdy, pokud se ji podaří najít všechna jména obsažená ve vstupním vektoru. V opačném případě vrátí chybu.any_of()vrátí prostě jenom ty sloupce, které v tabulce najde.
planes %>%
select(all_of("engine")) # Vrátí jeden sloupec
planes %>%
select(all_of(c("engine","Engine"))) # Vrátí chybu
planes %>%
select(any_of(c("engine","Engine"))) # Vrátí jeden sloupec
planes %>%
select(any_of(c("Engine"))) # Nevrátí řádný sloupec.Select helpers mohou být kombinováni se všemi ostatními způsoby identifikace sloupců:
planes %>%
select(tailnum, starts_with("engine"))# A tibble: 3,322 × 3
tailnum engines engine
<chr> <int> <chr>
1 N10156 2 Turbo-fan
2 N102UW 2 Turbo-fan
3 N103US 2 Turbo-fan
4 N104UW 2 Turbo-fan
5 N10575 2 Turbo-fan
6 N105UW 2 Turbo-fan
7 N107US 2 Turbo-fan
8 N108UW 2 Turbo-fan
9 N109UW 2 Turbo-fan
10 N110UW 2 Turbo-fan
# ℹ 3,312 more rowsPosledním select helper je where(). Tato funkce umožňuje vybrat sloupce s pomocí funkce vracející logickou hdonotu. Je tak možné například vybrat pouze sloupce, které obahují celá čísla:
planes %>%
select(where(is.integer))# A tibble: 3,322 × 4
year engines seats speed
<int> <int> <int> <int>
1 2004 2 55 NA
2 1998 2 182 NA
3 1999 2 182 NA
4 1999 2 182 NA
5 2002 2 55 NA
6 1999 2 182 NA
7 1999 2 182 NA
8 1999 2 182 NA
9 1999 2 182 NA
10 1999 2 182 NA
# ℹ 3,312 more rowsVšiměte si, že samotná funkce is.integer je parametrem where() a nikoliv její výstup. Je proto nutné do funkce zadat is.integer a nikoliv is.integer().
Funkce where() je jedna z novinek v dplyr 1.0.0 a společně s dalšími funkcemi nahradila tzv. scoped varianty základních funkcí (select_if() atp.).
Select helper s velmi specifickým využitím je everything(), které slouží k vybrání všeho. Nebo lépe všeho ostatního. Pokud z nějakého důvodu chceme změnit pořadí sloupců v tabulce, potom se hodí právě everything().
planes %>%
select(engine, engines, everything())# A tibble: 3,322 × 9
engine engines tailnum year type manufacturer model seats speed
<chr> <int> <chr> <int> <chr> <chr> <chr> <int> <int>
1 Turbo-fan 2 N10156 2004 Fixed wing mu… EMBRAER EMB-… 55 NA
2 Turbo-fan 2 N102UW 1998 Fixed wing mu… AIRBUS INDU… A320… 182 NA
3 Turbo-fan 2 N103US 1999 Fixed wing mu… AIRBUS INDU… A320… 182 NA
4 Turbo-fan 2 N104UW 1999 Fixed wing mu… AIRBUS INDU… A320… 182 NA
5 Turbo-fan 2 N10575 2002 Fixed wing mu… EMBRAER EMB-… 55 NA
6 Turbo-fan 2 N105UW 1999 Fixed wing mu… AIRBUS INDU… A320… 182 NA
7 Turbo-fan 2 N107US 1999 Fixed wing mu… AIRBUS INDU… A320… 182 NA
8 Turbo-fan 2 N108UW 1999 Fixed wing mu… AIRBUS INDU… A320… 182 NA
9 Turbo-fan 2 N109UW 1999 Fixed wing mu… AIRBUS INDU… A320… 182 NA
10 Turbo-fan 2 N110UW 1999 Fixed wing mu… AIRBUS INDU… A320… 182 NA
# ℹ 3,312 more rowsZmění pořadí sloupců tak, že na první pozici přesune engine a engines a následně do tabulky vyskládá všechny ostatní sloupce. Díky everything() není nutné jejich jména vypisovat. Do verze 1.0.0 bylo použití select() prakticky jedinou možností jak změnit pořadí sloupců. O dtéto verze v dplyr existuje specializovaná funkce relocate(), která také umí pracovat se select helpers.
Další speciální funkce
Při práci s výběry, které jsou v podstatě jen logickým vektorem nad jmény sloupců, je možné používat logické operátory ! (negace), | (OR) a & (AND):
planes %>%
select(!starts_with("engi")) # Vrátí sloupce, které nezačínají na "engi"# A tibble: 3,322 × 7
tailnum year type manufacturer model seats speed
<chr> <int> <chr> <chr> <chr> <int> <int>
1 N10156 2004 Fixed wing multi engine EMBRAER EMB-145XR 55 NA
2 N102UW 1998 Fixed wing multi engine AIRBUS INDUSTRIE A320-214 182 NA
3 N103US 1999 Fixed wing multi engine AIRBUS INDUSTRIE A320-214 182 NA
4 N104UW 1999 Fixed wing multi engine AIRBUS INDUSTRIE A320-214 182 NA
5 N10575 2002 Fixed wing multi engine EMBRAER EMB-145LR 55 NA
6 N105UW 1999 Fixed wing multi engine AIRBUS INDUSTRIE A320-214 182 NA
7 N107US 1999 Fixed wing multi engine AIRBUS INDUSTRIE A320-214 182 NA
8 N108UW 1999 Fixed wing multi engine AIRBUS INDUSTRIE A320-214 182 NA
9 N109UW 1999 Fixed wing multi engine AIRBUS INDUSTRIE A320-214 182 NA
10 N110UW 1999 Fixed wing multi engine AIRBUS INDUSTRIE A320-214 182 NA
# ℹ 3,312 more rowsplanes %>%
select(starts_with("e") & ends_with("s")) # Vrátí sloupce začínající na "e" a zároveň končící na "s"# A tibble: 3,322 × 1
engines
<int>
1 2
2 2
3 2
4 2
5 2
6 2
7 2
8 2
9 2
10 2
# ℹ 3,312 more rowsplanes %>%
select(starts_with("e") | ends_with("s")) # Vrátí sloupce začínající na "e" nebo končící na "s"# A tibble: 3,322 × 3
engines engine seats
<int> <chr> <int>
1 2 Turbo-fan 55
2 2 Turbo-fan 182
3 2 Turbo-fan 182
4 2 Turbo-fan 182
5 2 Turbo-fan 55
6 2 Turbo-fan 182
7 2 Turbo-fan 182
8 2 Turbo-fan 182
9 2 Turbo-fan 182
10 2 Turbo-fan 182
# ℹ 3,312 more rowsPodobně je možné výběry kombinovat pomocí funkce c():
planes %>%
select(starts_with(c("e","s"))) # Vrátí sloupce začínající na "e" nebo na "s"# A tibble: 3,322 × 4
engines engine seats speed
<int> <chr> <int> <int>
1 2 Turbo-fan 55 NA
2 2 Turbo-fan 182 NA
3 2 Turbo-fan 182 NA
4 2 Turbo-fan 182 NA
5 2 Turbo-fan 55 NA
6 2 Turbo-fan 182 NA
7 2 Turbo-fan 182 NA
8 2 Turbo-fan 182 NA
9 2 Turbo-fan 182 NA
10 2 Turbo-fan 182 NA
# ℹ 3,312 more rowsVýběr a přejmenování sloupce
Jednou ze speciálních funkcí je i =. To slouží v select() pro přejmenování. Například volání
planes %>%
select(tailnum, company = manufacturer)# A tibble: 3,322 × 2
tailnum company
<chr> <chr>
1 N10156 EMBRAER
2 N102UW AIRBUS INDUSTRIE
3 N103US AIRBUS INDUSTRIE
4 N104UW AIRBUS INDUSTRIE
5 N10575 EMBRAER
6 N105UW AIRBUS INDUSTRIE
7 N107US AIRBUS INDUSTRIE
8 N108UW AIRBUS INDUSTRIE
9 N109UW AIRBUS INDUSTRIE
10 N110UW AIRBUS INDUSTRIE
# ℹ 3,312 more rowsvybere sloupce tailnum a manufacturer. Sloupec manufacturer však zároveň přejmenuje na company.
Speciálně pro přejmenovávání sloupců je v dplyr obsažena funkce rename() (fakticky jde jen o lehkou mutaci select()). Ta sloupce nevybírá, ale jen přejmenovává. Použití = je v ní povinné:
planes %>%
rename(tailnum, company = manufacturer)Error in `rename()`:
! All renaming inputs must be named.Po opravě získáme správný výsledek:
planes %>%
rename(company = manufacturer)# A tibble: 3,322 × 9
tailnum year type company model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi engi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi engi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi engi… AIRBUS… A320… 2 182 NA Turbo…
# ℹ 3,312 more rowsTabulka obsahuje všechny sloupce, ale jeden z nich byl přejmenován.
13.2 Tvorba a úprava obsahu
Balík dplyr obsahuje dvě základní funkce pro vytváření a agregaci obsahu v tabulkách: mutate() a summarise()
Tvorba nových sloupců s mutate()
Funkce mutate() vytváří nové sloupce, proměnné, v tabulce. Zachovává tedy počet řádků v tabulce a přidává nové sloupce. Syntax mutate() je podobně jako u dalších funkcí z tidyverse poměrně střídmá:
mutate(.data, ...)Funkce přijímá vstupní tabulku a specifikaci sloupců, které se mají vytvořit v .... Fungování mutate() může být ilustrováno následujícím (mírně zjednodušujícím) schématem:

mutate()mutate() může být použito i pro modifikaci stávajících sloupců. V tomto případě však mutate() interně nejprve vytvoří nový sloupec a až následně jím nahradí sloupec původní. Při modifikaci sloupce na opravdu velkých tabulkách tak může mutate() spotřebovávat nečekané množství systémových zdrojů.
Praktické využití mutate() je možné ilustrovat na příkladu. Například můžeme chtít pro každé pozorování (řádek, letadlo) v tabulce planes spočítat, kolik sedadel připadá na jeden motor a zjistit, zda se jedná o vrtulové letadlo:
planes %>%
mutate(
seats_per_engine = (seats/engines) %>% round(),
turbo_prop_plane = engine == "Turbo-prop"
) #%>% # A tibble: 3,322 × 11
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,312 more rows
# ℹ 2 more variables: seats_per_engine <dbl>, turbo_prop_plane <lgl> #select(seats_per_engine, turbo_prop_plane, everything())mutate() vytvořilo dva nové sloupce. Sloupec seats_per_engine obsahuje zaokrouhlený počet sedadel na motor. Za povšimnutí stojí způsob, jakým byl jeho výpočet ve funkci mutate() specifikován. Na levé straně je jméno nově vytvářeného sloupce. Na pravé straně od “=” je postup, který se má použít pro vytvoření jejího obsahu. Jména sloupců z tabulky se přitom používají jako proměnné. Příklad také ukazuje, že v mutate() je možné používat komplikované výrazy včetně trubek %>%.
V jednom volání mutate() je možné vytvořit více nových sloupců. Jednotlivé specifikace jsou ve volání odděleny čárkou. Druhý vytvořený sloupec ukazuje příklad vytvoření logické proměnné. Ohledně typu zpracovávaných nebo výsledných proměnných nemá mutate() žádné omezení.
mutate() přidává nově vytvořené sloupce na konec tabulky. Proto je v příkladu použita funkce select(), která je přesunuje na začátek tabulky. Verze 1.0.0 umožňuje nastavit, kde se v tabulce nové sloupce vytvoří, nicméně tato funkcionalita je stále ve fázi vývoje.
U popisu fungování mutate() je výše zmíněná možnost modifikace stávajících sloupců. V praxi se taková operace provede jednoduše. Předpokládejme, že chceme sloupec year nahradit jeho vlastním logaritmem:
planes %>%
mutate(
year = log(year)
)# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <dbl> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 7.60 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 7.60 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 7.60 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 7.60 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 7.60 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 7.60 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
7 N107US 7.60 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
8 N108UW 7.60 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
9 N109UW 7.60 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
10 N110UW 7.60 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,312 more rowsPokud jméno nového sloupce odpovídá některému sloupci, který již je v tabulce obsažen, je tento novým sloupcem nahrazen.
mutate() umí pracovat i s proměnnými, které nejsou součástí tabulky. V následujícím případě je nově vytvořený sloupec this_is_true naplněn konstantou přiřazenou do proměnné x.
x <- TRUE
planes %>%
mutate(
this_is_true = x
) %>%
select(this_is_true, everything())# A tibble: 3,322 × 10
this_is_true tailnum year type manufacturer model engines seats speed
<lgl> <chr> <int> <chr> <chr> <chr> <int> <int> <int>
1 TRUE N10156 2004 Fixed wing… EMBRAER EMB-… 2 55 NA
2 TRUE N102UW 1998 Fixed wing… AIRBUS INDU… A320… 2 182 NA
3 TRUE N103US 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
4 TRUE N104UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
5 TRUE N10575 2002 Fixed wing… EMBRAER EMB-… 2 55 NA
6 TRUE N105UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
7 TRUE N107US 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
8 TRUE N108UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
9 TRUE N109UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
10 TRUE N110UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
# ℹ 3,312 more rows
# ℹ 1 more variable: engine <chr>Stejného výsledku by bylo dosaženo, kdyby byla konstanta definována přímo v mutate() tj. this_is_true = TRUE.
Na proměnnou, která takto do mutate() vstupuje zvnějšku je uvaleno omezení: musí mít délku jedna, nebo délku odpovídající počtu řádků tabulky. Tato podmínka není v následujícím příkladu splněna (vektor x má délku 3):
x <- c(TRUE, TRUE, TRUE)
planes %>%
mutate(
this_is_true = x
) %>%
select(this_is_true, everything())Error in `mutate()`:
ℹ In argument: `this_is_true = x`.
Caused by error:
! `this_is_true` must be size 3322 or 1, not 3.Pokud má vektor x délku 1, potom je tato jedna hodnota přiřazena ke každému řádku. Pokud je délka x právě rovna počtu řádků, potom je ke každému řádku přiřazena hodnota na odpovídající pozici:
x <- 1:nrow(planes)
planes %>%
mutate(
new_variable = x
) %>%
select(new_variable, everything())# A tibble: 3,322 × 10
new_variable tailnum year type manufacturer model engines seats speed
<int> <chr> <int> <chr> <chr> <chr> <int> <int> <int>
1 1 N10156 2004 Fixed wing… EMBRAER EMB-… 2 55 NA
2 2 N102UW 1998 Fixed wing… AIRBUS INDU… A320… 2 182 NA
3 3 N103US 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
4 4 N104UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
5 5 N10575 2002 Fixed wing… EMBRAER EMB-… 2 55 NA
6 6 N105UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
7 7 N107US 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
8 8 N108UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
9 9 N109UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
10 10 N110UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
# ℹ 3,312 more rows
# ℹ 1 more variable: engine <chr>Naprosto stejná pravidla platí pro funkce. V příkladu je použita funkce rnorm(n), která vrací n výběrů z normálního rozdělení. První dva příklady jsou vyhodnoceny bez problémů. Poslední je nekorektní a skončí chybou, protože rnorm(3) vrací vektor o délce 3.
planes %>%
mutate(
new_variable = rnorm(1)
) %>%
select(new_variable, everything())# A tibble: 3,322 × 10
new_variable tailnum year type manufacturer model engines seats speed
<dbl> <chr> <int> <chr> <chr> <chr> <int> <int> <int>
1 0.335 N10156 2004 Fixed wing… EMBRAER EMB-… 2 55 NA
2 0.335 N102UW 1998 Fixed wing… AIRBUS INDU… A320… 2 182 NA
3 0.335 N103US 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
4 0.335 N104UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
5 0.335 N10575 2002 Fixed wing… EMBRAER EMB-… 2 55 NA
6 0.335 N105UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
7 0.335 N107US 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
8 0.335 N108UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
9 0.335 N109UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
10 0.335 N110UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
# ℹ 3,312 more rows
# ℹ 1 more variable: engine <chr>planes %>%
mutate(
new_variable = rnorm(nrow(planes))
) %>%
select(new_variable, everything())# A tibble: 3,322 × 10
new_variable tailnum year type manufacturer model engines seats speed
<dbl> <chr> <int> <chr> <chr> <chr> <int> <int> <int>
1 0.966 N10156 2004 Fixed wing… EMBRAER EMB-… 2 55 NA
2 -0.735 N102UW 1998 Fixed wing… AIRBUS INDU… A320… 2 182 NA
3 -1.09 N103US 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
4 0.550 N104UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
5 0.227 N10575 2002 Fixed wing… EMBRAER EMB-… 2 55 NA
6 -0.388 N105UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
7 -0.419 N107US 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
8 -0.925 N108UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
9 -0.264 N109UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
10 -1.76 N110UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
# ℹ 3,312 more rows
# ℹ 1 more variable: engine <chr>planes %>%
mutate(
new_variable = rnorm(3)
) %>%
select(new_variable, everything())Error in `mutate()`:
ℹ In argument: `new_variable = rnorm(3)`.
Caused by error:
! `new_variable` must be size 3322 or 1, not 3.Úskalí mutate()
Výše byl použit příklad, ve kterém byla při stanovení hodnoty použita proměnná definovaná mimo tabulku. Při troše smůly se může stát, že jméno této proměnné se bude shodovat se jménem některého sloupce. V souladu s logikou R dostane přednost obsah sloupce:
tailnum <- TRUE
planes %>%
mutate(
this_is_true = tailnum
) %>%
select(this_is_true, everything())# A tibble: 3,322 × 10
this_is_true tailnum year type manufacturer model engines seats speed
<chr> <chr> <int> <chr> <chr> <chr> <int> <int> <int>
1 N10156 N10156 2004 Fixed wing… EMBRAER EMB-… 2 55 NA
2 N102UW N102UW 1998 Fixed wing… AIRBUS INDU… A320… 2 182 NA
3 N103US N103US 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
4 N104UW N104UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
5 N10575 N10575 2002 Fixed wing… EMBRAER EMB-… 2 55 NA
6 N105UW N105UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
7 N107US N107US 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
8 N108UW N108UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
9 N109UW N109UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
10 N110UW N110UW 1999 Fixed wing… AIRBUS INDU… A320… 2 182 NA
# ℹ 3,312 more rows
# ℹ 1 more variable: engine <chr>Další úskalí v použití spočívá v tom, že mutate() pracuje nad celou tabulkou a ne nad jednotlivými řádky. Toto chování lze změnit pomocí vhodného zgrupování, ale je potřeba ho mít na paměti. Co to znamená v praxi:
planes %>%
mutate(
mean_year = mean(year, na.rm = TRUE)
) %>%
select(mean_year, everything())# A tibble: 3,322 × 10
mean_year tailnum year type manufacturer model engines seats speed engine
<dbl> <chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 2000. N10156 2004 Fixed … EMBRAER EMB-… 2 55 NA Turbo…
2 2000. N102UW 1998 Fixed … AIRBUS INDU… A320… 2 182 NA Turbo…
3 2000. N103US 1999 Fixed … AIRBUS INDU… A320… 2 182 NA Turbo…
4 2000. N104UW 1999 Fixed … AIRBUS INDU… A320… 2 182 NA Turbo…
5 2000. N10575 2002 Fixed … EMBRAER EMB-… 2 55 NA Turbo…
6 2000. N105UW 1999 Fixed … AIRBUS INDU… A320… 2 182 NA Turbo…
7 2000. N107US 1999 Fixed … AIRBUS INDU… A320… 2 182 NA Turbo…
8 2000. N108UW 1999 Fixed … AIRBUS INDU… A320… 2 182 NA Turbo…
9 2000. N109UW 1999 Fixed … AIRBUS INDU… A320… 2 182 NA Turbo…
10 2000. N110UW 1999 Fixed … AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,312 more rowsmutate() v tomto případě vypočítal průměrnou hodnotu ze všech roků a tu přiřadil ke všem sloupcům. Opět je to dáno tím, že mean neprodukuje vektor o délce odpovídající počtu řádků, ale vektor o délce 1.
Agregace proměnných se summarise()
Podstatou agregace je shrnutí obsahu tabulky (jednoho nebo více sloupců) a vytvoření nové tabulky, která obsahuje tyto agregované hodnoty (typicky statistiky jako průměr, medián, minimum, atp.).

summarise()Pro tyto účely slouží v dplyr funkce summarise(). Její použití se v logice velmi podobá mutate(). To ilustruje následující příklad:
planes %>%
summarise(
min_year = min(year, na.rm = TRUE),
max_year = max(year, na.rm = TRUE),
min_engines = min(engines, na.rm = TRUE),
max_engines = max(engines, na.rm = TRUE)
)# A tibble: 1 × 4
min_year max_year min_engines max_engines
<int> <int> <int> <int>
1 1956 2013 1 4V tomto volání funkce summarise() jsou vytvořeny 4 agregované hodnoty: maxima a minima ze sloupců year a engines. Výsledkem je tabulka, která podle stanovených pravidel shrnuje celou tabulku do jediného řádku.
13.3 Další užitečné funkce z balíku dplyr
Balík dplyr obsahuje opravdu velmi mnoho funkcí, které pracují nad jednou tabulkou. V této kapitole je představen lehký výběr těch, které se v praxi datové analýzy používají opravdu často.
Funkce distinct() je ekvivalentem unique() – vrací tabulku, která obsahuje pouze unikátní pozorování. V případě shody více řádků zachovává v nové tabulce první z nich. Proti unique() je rychlejší a hlavně umožňuje specifikovat sloupce, podle kterých se má unikátnost pozorování posuzovat:
planes %>%
distinct(manufacturer, type)# A tibble: 37 × 2
manufacturer type
<chr> <chr>
1 EMBRAER Fixed wing multi engine
2 AIRBUS INDUSTRIE Fixed wing multi engine
3 BOEING Fixed wing multi engine
4 AIRBUS Fixed wing multi engine
5 BOMBARDIER INC Fixed wing multi engine
6 CESSNA Fixed wing single engine
7 CESSNA Fixed wing multi engine
8 JOHN G HESS Fixed wing single engine
9 GULFSTREAM AEROSPACE Fixed wing multi engine
10 SIKORSKY Rotorcraft
# ℹ 27 more rowsV základním nastavení je výstupní tabulka omezena pouze na proměnné, které byly použity k posouzení unikátnosti. Toto chování se dá změnit pomocí parametru .keep_all:
planes %>%
distinct(manufacturer, type, .keep_all = TRUE)# A tibble: 37 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N11206 2000 Fixed wing multi… BOEING 737-… 2 149 NA Turbo…
4 N125UW 2009 Fixed wing multi… AIRBUS A320… 2 182 NA Turbo…
5 N131EV 2009 Fixed wing multi… BOMBARDIER … CL-6… 2 95 NA Turbo…
6 N201AA 1959 Fixed wing singl… CESSNA 150 1 2 90 Recip…
7 N202AA 1980 Fixed wing multi… CESSNA 421C 2 8 90 Recip…
8 N315AT NA Fixed wing singl… JOHN G HESS AT-5 1 2 NA 4 Cyc…
9 N344AA 1992 Fixed wing multi… GULFSTREAM … G-IV 2 22 NA Turbo…
10 N347AA 1985 Rotorcraft SIKORSKY S-76A 2 14 NA Turbo…
# ℹ 27 more rowsUžitečnou funkcí je řazení pozorování. To má v dplyr na starosti funkce arrange(). arrange() přijímá jako parametry vstupní tabulku a jména sloupců, podle kterých má tabulku seřadit:
planes %>%
arrange(manufacturer,engines)# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N365AA 2001 Rotorcraft AGUSTA SPA A109E 2 8 NA Turbo…
2 N125UW 2009 Fixed wing multi… AIRBUS A320… 2 182 NA Turbo…
3 N126UW 2009 Fixed wing multi… AIRBUS A320… 2 182 NA Turbo…
4 N127UW 2010 Fixed wing multi… AIRBUS A320… 2 182 NA Turbo…
5 N128UW 2010 Fixed wing multi… AIRBUS A320… 2 182 NA Turbo…
6 N150UW 2013 Fixed wing multi… AIRBUS A321… 2 199 NA Turbo…
7 N151UW 2013 Fixed wing multi… AIRBUS A321… 2 199 NA Turbo…
8 N152UW 2013 Fixed wing multi… AIRBUS A321… 2 199 NA Turbo…
9 N153UW 2013 Fixed wing multi… AIRBUS A321… 2 199 NA Turbo…
10 N154UW 2013 Fixed wing multi… AIRBUS A321… 2 199 NA Turbo…
# ℹ 3,312 more rowsarrange() nejprve řadí tabulku podle první zadaného sloupce, následně podle druhého, atp. Směr řazení je možné změnit pomocí speciální funkce desc():
planes %>%
arrange(desc(manufacturer),engines)# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N397AA 1985 Fixed wing singl… STEWART MACO FALC… 1 2 NA Recip…
2 N521AA NA Fixed wing singl… STEWART MACO FALC… 1 2 NA Recip…
3 N347AA 1985 Rotorcraft SIKORSKY S-76A 2 14 NA Turbo…
4 N537JB 2012 Rotorcraft ROBINSON HE… R66 1 5 NA Turbo…
5 N376AA 1978 Fixed wing singl… PIPER PA-3… 1 7 NA Recip…
6 N425AA 1968 Fixed wing singl… PIPER PA-2… 1 4 107 Recip…
7 N545AA 1976 Fixed wing singl… PIPER PA-3… 1 7 126 Recip…
8 N350AA 1980 Fixed wing multi… PIPER PA-3… 2 8 162 Recip…
9 N525AA 1980 Fixed wing multi… PIPER PA-3… 2 8 162 Recip…
10 N377AA NA Fixed wing singl… PAIR MIKE E FALC… 1 2 NA Recip…
# ℹ 3,312 more rows13.4 Operace nad sloupci
Funkce z balíku dplyr umožňují spouštět funkce nad specifikovanými sloupci tabulky. Prvním příkladem užití takové funkcionality může být výběr sloupců určitého datového typu:
planes %>%
select(where(is.character))# A tibble: 3,322 × 5
tailnum type manufacturer model engine
<chr> <chr> <chr> <chr> <chr>
1 N10156 Fixed wing multi engine EMBRAER EMB-145XR Turbo-fan
2 N102UW Fixed wing multi engine AIRBUS INDUSTRIE A320-214 Turbo-fan
3 N103US Fixed wing multi engine AIRBUS INDUSTRIE A320-214 Turbo-fan
4 N104UW Fixed wing multi engine AIRBUS INDUSTRIE A320-214 Turbo-fan
5 N10575 Fixed wing multi engine EMBRAER EMB-145LR Turbo-fan
6 N105UW Fixed wing multi engine AIRBUS INDUSTRIE A320-214 Turbo-fan
7 N107US Fixed wing multi engine AIRBUS INDUSTRIE A320-214 Turbo-fan
8 N108UW Fixed wing multi engine AIRBUS INDUSTRIE A320-214 Turbo-fan
9 N109UW Fixed wing multi engine AIRBUS INDUSTRIE A320-214 Turbo-fan
10 N110UW Fixed wing multi engine AIRBUS INDUSTRIE A320-214 Turbo-fan
# ℹ 3,312 more rowsVýběr byl proveden s použitím dodatečné select-helper funce where(). Do té byl vložen výraz, který byl vyhodnocen nad sloupci tabulky. Výsledek, logický vektor, byl potom použit pro výběr funkcí select().
Všiměte si, že funkce is.character() je v příkladu použita bez závorek. Parametrem where() je totiž funkce samotná a nikoliv její výstup.
dplyr umožňuje uživateli provádět i sofistikovanější operace – typicky modifikovat sloupce, které splňují určitou podmínku. Můžeme například chtít konvertovat číselné sloupce na character. Pro tyto účely slouží funkce across(). Ta má dva vstupy: (a) výraz, který identifikuje sloupce, které se mají modifikovat, a (b) výraz, který se má pro samotnou modifikaci použít. řešení by mohlo vypadat následujícím způsobem:
planes %>%
mutate(
across(
# Modifikuj sloupce, které obsahují numerický datový typ (double nebo integer)
where(is.numeric),
#...aplikuj na ně následující funkci:
as.character
)
)# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 <NA> Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 <NA> Turbo…
3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 <NA> Turbo…
4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 <NA> Turbo…
5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 <NA> Turbo…
6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 <NA> Turbo…
7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 <NA> Turbo…
8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 <NA> Turbo…
9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 <NA> Turbo…
10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 <NA> Turbo…
# ℹ 3,312 more rowsUživatel přitom není omezen na existující funkce. Přes sloupce může iterovat vlastní funkci nebo definovat anonymní/lambda funkci přímo v across():
planes %>%
mutate(
across(
where(is.numeric),
function(x) round(x)
)
)# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,312 more rowsJe možné použít i zjednodušený (purrr-stale) zápis pomocí jednostranné rovnice:
planes %>%
mutate(
across(
where(is.numeric),
~round(.x)
)
)# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,312 more rowsFunkce across() funguje výborně s funkcemi jako je mutate() nebo summarise(). V dplyr 1.0.4 přibyly nové funkce, které jsou navženy tak, aby podobným způsobem umožnili pracovat s filter(). Jde o if_any() a if_all(). Jejich syntaxe a parametry jsou stejné jako u across(), ale na rozdíl od across() vracejí logický vektor, který je požadovaným vstupem funkce filter().
Následující příklad ukazuje, jak řešit obyvklý problém v datové analýze – někde nám utíkají pozorování, protože některé řádky v nějakém sloupci obsahují NA. Funkce if_any() nám umožňuje takové řádky lehce najít:
planes %>%
filter(
if_any(
everything(), # tj. hledej ve všech sloupcích
is.na
)
)# A tibble: 3,299 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,289 more rowsFunkce across(), where(), if_any() a if_all() nahrazují tzv. scoped varianty základních funkcí ze starších verzí dplyr.
Aplikace
Spočítejte průměrnou hodinovou mzdu pro každého zaměstnance (řádek) v tabulce ispv a srovnejte ji s proměnnou PRUMVYD. Průměrnou mzdu definujeme jako MZDA/ODPRACD.
Při bližším pohledu na tabulku ispv zjistíte, že všechny sloupce jsou typu character. Vyberte si z tabulky sloupce, které potřebujete a zkonvertujte je na číslo (double). Následně proveďte výpočet.
ispv %>%
# Výběr sloupců výčtem
select(PRUMVYD,MZDA,ODPRACD) %>%
# Před konverzí je data nutné vyčistit -- změnit "," na "."
mutate(
across(
everything(),
# Všiměte si, jak se do kódu zadává funkce a její parametry
str_replace_all,",","."
)
) %>%
# Následně je možné sloupce konvertovat na double
mutate(
across(
everything(),
as.double
)
) %>%
# Alternativně by bylo možné použít anonymní funkci
# mutate(
# across(
# everything(),
# function(x) str_replace_all(x,",",".") %>% as.double()
# )
# ) %>%
# Nyní je možné spočítat průměrnou mzdu -- do nového sloupce
mutate(
Wmean = MZDA/ODPRACD
) %>%
# Můžeme vybrat řádky, kde je nově spočítaná mzda vyšší než reportovaná
filter(
Wmean > PRUMVYD
)Warning: There was 1 warning in `mutate()`.
ℹ In argument: `across(everything(), str_replace_all, ",", ".")`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))# A tibble: 520 × 4
PRUMVYD MZDA ODPRACD Wmean
<dbl> <dbl> <dbl> <dbl>
1 129. 355461 1837. 194.
2 58.3 349753 1808 193.
3 190. 219713 836 263.
4 128. 356932 1704. 209.
5 315. 373404 420 889.
6 122. 269636 212 1272.
7 230. 1140000 592 1926.
8 0 393134 1805. 218.
9 169. 1368612 1117. 1226.
10 0 314986 862 365.
# ℹ 510 more rowsV 520 případech (tj. v cca 50 % případů) je nově spočítaná průměrná mzda vyšší, než průměrná mzda uvedená v datasetu. To není překvapivé, protože dataset vznikl náhodným zpřeházením řádků nezávisle u každého sloupce. Podobné procedura může být použita pro generování trénovacích datasetů. Zkuste si ji naprogramovat.
set.seed(42)
ispv %>%
mutate(
across(
everything(),
sample, 1000, replace = FALSE
)
)# A tibble: 1,000 × 36
ICO IDZAM ROKNAR POHLAVI STOBC VZDELANI INVALD MISTOVP CZICSE CZISCO
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 e3f5ee78f63… 0032… 1968 1 SK H Z CZ0412 1111 72239
2 59388a627d7… 1000… 1962 M cz V Z CZ0806 1111 25140
3 28c9bfcdd42… 760 1982 M CZ T Z CZ0805 1111 52236
4 7d5715db899… 3101… 1991 Z CZ M Z CZ0722 1112 82121
5 9a1b22d03ab… 61037 1970 M CZ L Z CZ0511 1111 52231
6 17fcef127b8… 0001… 1994 2 CZ M Z CZ0642 1100 72313
7 dba7fca2d25… 0002… 1981 Z SK C Z CZ0100 1111 83443
8 449bc97f134… 61803 1995 Z CZ H Z CZ0204 1112 41323
9 da0d4126233… 0000… 1954 2 CZ H Z CZ0100 1111 43210
10 2dcba2e85a3… 8690… 1974 1 CZ L Z CZ0642 1111 22214
# ℹ 990 more rows
# ℹ 26 more variables: VEDOUCI <chr>, KONTOPD <chr>, DOBAZAM <chr>,
# EVIDDNY <chr>, KONECEP <chr>, FONDSTA <chr>, FONDSJE <chr>, ODPRACD <chr>,
# PRESCAS <chr>, ABSCELK <chr>, ABSPLAC <chr>, ABSDOVOL <chr>,
# ABSNEMOC <chr>, ABSNEMZ <chr>, MZDA <chr>, POPRAV <chr>, PONEPRAV <chr>,
# PRIPPCAS <chr>, PRIPLAT <chr>, NAHRADY <chr>, NAHRNEMZ <chr>,
# POHOTOV <chr>, PRUMVYD <chr>, ISCED <chr>, OBORVZD <chr>, year <chr>Zkuste použít vypočítanou průměrnou hodinovou mzdu a spočítat pro celý soubor minimum, maximum, median a průměr.
ispv %>%
select(PRUMVYD,MZDA,ODPRACD) %>%
mutate(
across(
everything(),
function(x) str_replace_all(x,",",".") %>% as.double()
)
) %>%
# Zde použijeme variantu funkce mutate(), která ponechá jen nově vytvořený sloupec:
transmute(
Wmean = MZDA/ODPRACD
) %>%
# Náhodná tvorba datasetu vytváří i paradoxní hodnoty. Ponechte v datech jen
# konečné hodnoty průměrné mzdy
filter(is.finite(Wmean)) %>%
summarise(
across(
everything(),
list(min = min, max = max, median = median, mean = mean),
na.rm = TRUE)
)# A tibble: 1 × 4
Wmean_min Wmean_max Wmean_median Wmean_mean
<dbl> <dbl> <dbl> <dbl>
1 0 253385. 177. 741.13.5 Operace nad skupinami řádků
Všechny předchozí funkce lze s různou mírou elegance nahradit funkcemi ze základního R. Grupované operace však lze nahradit jen obtížně a v žádném případě ne elegantně. Podstatou zgrupované operace je vyhodnocení funkce nad jednotlivými segmenty tabulky. Na obrázku je zgrupovaná operace provedena funkce summarise():
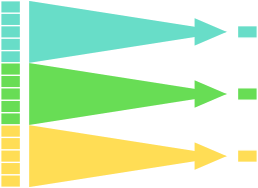
summarise()summarise() je vykonáno nad jednotlivými barvenými grupami. Výsledky za jednotlivé grupy jsou následně složeny do nové tabulky.
V praktickém nasazení nás například může zajímat minimální, maximální a průměrný počet sedadel v letadlech jednotlivých výrobců.
V prvním kroku je potřeba pomocí funkce group_by() vytvořit grupování – tj. identifikovat řádky, které tvoří jednu grupu. Následně je možné volat funkci summarise():
planes %>%
group_by(manufacturer) %>%
summarise(
min_seats = min(seats, na.rm = TRUE),
mean_seats = mean(seats, na.rm = TRUE),
max_seats = max(seats, na.rm = TRUE)
)# A tibble: 35 × 4
manufacturer min_seats mean_seats max_seats
<chr> <int> <dbl> <int>
1 AGUSTA SPA 8 8 8
2 AIRBUS 100 221. 379
3 AIRBUS INDUSTRIE 145 187. 379
4 AMERICAN AIRCRAFT INC 2 2 2
5 AVIAT AIRCRAFT INC 2 2 2
6 AVIONS MARCEL DASSAULT 12 12 12
7 BARKER JACK L 2 2 2
8 BEECH 9 9.5 10
9 BELL 5 8 11
10 BOEING 100 175. 450
# ℹ 25 more rows# Alternativní zápis sumarizace -- víc ukecaný, ale možná na čtení transparentnější.Protože nás zajímají počty sedadel v letadlech “jednotlivých výrobců” je pro zgrupování použita proměnná manufacturer. group_by však umí vytvořit i grupy tvořené kombinací více proměnných. Například by bylo možné zjistit počty sedadel pro skupinu vymezenou výrobcem a typem letounu:
planes %>%
group_by(manufacturer, type) %>%
summarise(
min_seats = min(seats, na.rm = TRUE),
mean_seats = mean(seats, na.rm = TRUE),
max_seats = max(seats, na.rm = TRUE)
)`summarise()` has regrouped the output.
ℹ Summaries were computed grouped by manufacturer and type.
ℹ Output is grouped by manufacturer.
ℹ Use `summarise(.groups = "drop_last")` to silence this message.
ℹ Use `summarise(.by = c(manufacturer, type))` for per-operation grouping
(`?dplyr::dplyr_by`) instead.# A tibble: 37 × 5
# Groups: manufacturer [35]
manufacturer type min_seats mean_seats max_seats
<chr> <chr> <int> <dbl> <int>
1 AGUSTA SPA Rotorcraft 8 8 8
2 AIRBUS Fixed wing multi engine 100 221. 379
3 AIRBUS INDUSTRIE Fixed wing multi engine 145 187. 379
4 AMERICAN AIRCRAFT INC Fixed wing single engi… 2 2 2
5 AVIAT AIRCRAFT INC Fixed wing single engi… 2 2 2
6 AVIONS MARCEL DASSAULT Fixed wing multi engine 12 12 12
7 BARKER JACK L Fixed wing single engi… 2 2 2
8 BEECH Fixed wing multi engine 9 9.5 10
9 BELL Rotorcraft 5 8 11
10 BOEING Fixed wing multi engine 100 175. 450
# ℹ 27 more rowsV group_by() je možné použít proměnné všech typů (jakkoliv u double to asi příliš často nedává smysl).
Grupované operace pochopitelně nejsou omezeny pouze na summarise(). Následující příklad ukazuje použití s mutate(). Jako cvičení můžete kód analyzovat a zjistit, co dělá.
planes %>%
group_by(manufacturer) %>%
mutate(
year_diff = year - mean(year, na.rm = TRUE)
) %>%
select(tailnum, manufacturer, year, year_diff) %>%
arrange(manufacturer, year)# A tibble: 3,322 × 4
# Groups: manufacturer [35]
tailnum manufacturer year year_diff
<chr> <chr> <int> <dbl>
1 N365AA AGUSTA SPA 2001 0
2 N186US AIRBUS 2002 -5.20
3 N187US AIRBUS 2002 -5.20
4 N188US AIRBUS 2002 -5.20
5 N338NB AIRBUS 2002 -5.20
6 N339NB AIRBUS 2002 -5.20
7 N340NB AIRBUS 2002 -5.20
8 N341NB AIRBUS 2002 -5.20
9 N342NB AIRBUS 2002 -5.20
10 N343NB AIRBUS 2002 -5.20
# ℹ 3,312 more rowsV prvním kroku kód přidá zgrupování k tabulce planes. Výsledek této operace můžeme vidět pomocí funkce class():
planes %>%
group_by(manufacturer) %>%
class()[1] "grouped_df" "tbl_df" "tbl" "data.frame"Třída tabulky planes byla rozšířena o grouped_df. To umožní kompatibilním metodám nakládat s tabulkou speciálním způsobem: provést operaci zgrupovaně. Pokud pro danou funkci není “zgrupovaná” metoda dostupná, provede se funkce jako obvykle nad celou tabulkou:
planes %>%
group_by(manufacturer) %>%
summary() tailnum year type manufacturer
Length:3322 Min. :1956 Length:3322 Length:3322
Class :character 1st Qu.:1997 Class :character Class :character
Mode :character Median :2001 Mode :character Mode :character
Mean :2000
3rd Qu.:2005
Max. :2013
NA's :70
model engines seats speed
Length:3322 Min. :1.000 Min. : 2.0 Min. : 90.0
Class :character 1st Qu.:2.000 1st Qu.:140.0 1st Qu.:107.5
Mode :character Median :2.000 Median :149.0 Median :162.0
Mean :1.995 Mean :154.3 Mean :236.8
3rd Qu.:2.000 3rd Qu.:182.0 3rd Qu.:432.0
Max. :4.000 Max. :450.0 Max. :432.0
NA's :3299
engine
Length:3322
Class :character
Mode :character
Třída grouped_df() zůstává u tabulky zachována, dokud není jinou funkcí odstraněna. dplyr umožňuje grupování odstranit funkcí ungroup():
planes %>%
group_by(manufacturer) %>%
ungroup() %>%
class()[1] "tbl_df" "tbl" "data.frame"S vývojem dplyr postupně toto pravidlo přestává platit. Dobrým příkladem je funkce summarise(), která nově získala parametry .groups a .by (ten má např. i mutate()).
Nastavením .groups = "drop" můžete zrušit grupování u výstupního objektu ze summarise():
planes %>%
group_by(manufacturer, type) %>%
summarise(
min_seats = min(seats, na.rm = TRUE),
mean_seats = mean(seats, na.rm = TRUE),
max_seats = max(seats, na.rm = TRUE),
.groups = "drop"
) %>%
class()[1] "tbl_df" "tbl" "data.frame"Parametrem .by můžete funkce instruovat, aby vytvořily dočasné grupování, které nemusí být přítomno ve vstupním a není obsaženo ve výstupním objektu. Použití .by tedy eliminuje potřebu použít group_by() a .groups/ungroup() u předchozího příkladu. Výstup by přitom zůstal stejný:
planes %>%
summarise(
min_seats = min(seats, na.rm = TRUE),
mean_seats = mean(seats, na.rm = TRUE),
max_seats = max(seats, na.rm = TRUE),
.by = c(manufacturer, type)
)# A tibble: 37 × 5
manufacturer type min_seats mean_seats max_seats
<chr> <chr> <int> <dbl> <int>
1 EMBRAER Fixed wing multi engine 20 45.6 55
2 AIRBUS INDUSTRIE Fixed wing multi engine 145 187. 379
3 BOEING Fixed wing multi engine 100 175. 450
4 AIRBUS Fixed wing multi engine 100 221. 379
5 BOMBARDIER INC Fixed wing multi engine 55 74.0 95
6 CESSNA Fixed wing single engine 2 4.33 6
7 CESSNA Fixed wing multi engine 6 7.33 8
8 JOHN G HESS Fixed wing single engine 2 2 2
9 GULFSTREAM AEROSPACE Fixed wing multi engine 22 22 22
10 SIKORSKY Rotorcraft 14 14 14
# ℹ 27 more rowsAplikce
Vypočítejte průměrnou mzdu (z proměnné PRMUVYD) pro každé ISCO a pohlaví. ISCO definujte na 1. úrovni (tj. ISCO1).
ispv %>%
# Pro jednoduchost si necháme jen sloupce, které potřebujeme
select(CZISCO,POHLAVI,PRUMVYD) %>%
# map(unique) # Můžeme se podívat na hodnoty v jednotlivých sloupcích a vidíme,
# že data potřebují vyčistit.
mutate(
POHLAVI = case_when(
POHLAVI %in% c("1","M") ~ "M",
TRUE ~ "Z"
),
PRUMVYD = PRUMVYD %>% str_replace_all(",",".") %>% as.double()
) %>%
# Také potřebujeme definovat ISCO1
mutate(
# Doporučení -- u číselných kódů (ISCO, NACE,...) si nechávejte
# datový typ na character. Snižuje to riziko zavlečení chyb.
CZISCO = str_sub(CZISCO,1,1)
) %>%
# Chybějící ISCO a POHLAVI neumíme opravit. Chceme je vyloučit.
drop_na(CZISCO,POHLAVI) %>%
group_by(CZISCO,POHLAVI) %>%
summarise(
Wmean = mean(PRUMVYD),
.groups = "drop"
) %>%
# Tabulku lze transformovat pro lepší orientaci
pivot_wider(
names_from = POHLAVI, values_from = Wmean
)# A tibble: 10 × 3
CZISCO Z M
<chr> <dbl> <dbl>
1 0 160. NA
2 1 158. NA
3 2 NA NA
4 3 NA NA
5 4 NA 180.
6 5 NA NA
7 6 341. 151.
8 7 NA NA
9 8 NA NA
10 9 176. NA 13.6 Slovesa pracující se dvěma (nebo více) tabulkami
Data bývají často dostupná ve více tabulkách, které mohou například mohou pocházet z různých zdrojů: HDP ze Světové banky, migrace z Eurostatu, atp. Pro účely datové analýzy je nutné takové tabulky spojovat do jednoho celku.
dplyr podporuje dva druhy spojovacích operací:
- bind spojuje tabulky, které mají stejnou strukturu – v podstatě přidává sloupce (
bind_cols()) nebo řádky (bind_rows()) - join slučuje tabulky podle určitého definovaného klíče – například sloučí k sobě údaje o jednom člověku z více tabulek, které mohou mít naprosto odlišnou strukturu (více funkcí
*_join())
Spojování tabulek s bind_*()
Funkcí bind_rows() a bind_cols() je spojovat tabulky se stejnou strukturou. V případě, že jsou pozorování se stejnými proměnnými rozděleny do více tabulek, je potřeba tabulky poskládat “pod sebe”. Jinými slovy přidávat další a další řádky s dodatečnými pozorováními. V tomto případě se hodí použít funkci bind_rows(...). Ta jako argument přijímá jména (neomezeného počtu) tabulek a nebo seznam (list) tabulek. Fungování bind_rows() můžeme demonstrovat na tabulce dplyr::band_members:
band_members# A tibble: 3 × 2
name band
<chr> <chr>
1 Mick Stones
2 John Beatles
3 Paul BeatlesDo bind_rows() můžeme vložit více tabulek:
bind_rows(band_members, band_members, band_members)# A tibble: 9 × 2
name band
<chr> <chr>
1 Mick Stones
2 John Beatles
3 Paul Beatles
4 Mick Stones
5 John Beatles
6 Paul Beatles
7 Mick Stones
8 John Beatles
9 Paul Beatles…nebo list tabulek:
bind_rows(
list(band_members, band_members, band_members)
)# A tibble: 9 × 2
name band
<chr> <chr>
1 Mick Stones
2 John Beatles
3 Paul Beatles
4 Mick Stones
5 John Beatles
6 Paul Beatles
7 Mick Stones
8 John Beatles
9 Paul BeatlesVýsledky jsou pochopitelně stejné. Schopnost spojit tabulky uložené v seznamu je zvláště užitečná v případě, že pracujeme například s výstupem funkce map() z balíku purrr.
Předchozí příklady byly bezproblémové, protože tabulky měly stejnou strukturu – tedy stejně pojmenované sloupce se stejnými datovými typy. Co se stane v případě volání bind_rows() na nekonzistentní tabulky ukazuje následující příklad:
band_members %>%
rename(NAME = name) %>%
bind_rows(., band_members)# A tibble: 6 × 3
NAME band name
<chr> <chr> <chr>
1 Mick Stones <NA>
2 John Beatles <NA>
3 Paul Beatles <NA>
4 <NA> Stones Mick
5 <NA> Beatles John
6 <NA> Beatles Paul bind_rows() pod sebe složil hodnoty ze sloupců stejného jména. Sloupce s neshodujícími se jmény zachoval, ale do tabulky doplnil NA.
band_members %>%
rename(NAME = name) %>%
bind_rows(., band_members)# A tibble: 6 × 3
NAME band name
<chr> <chr> <chr>
1 Mick Stones <NA>
2 John Beatles <NA>
3 Paul Beatles <NA>
4 <NA> Stones Mick
5 <NA> Beatles John
6 <NA> Beatles Paul V případě nekonzistentních datových typů je situace zajímavější. V následujícím příkladu je sloupec name konvertován z character na factor a následně je tabulka spojena s nezměněnou tabulkou band_members:
band_members %>%
mutate(
name = as.factor(name)
) %>%
bind_rows(., band_members)# A tibble: 6 × 2
name band
<chr> <chr>
1 Mick Stones
2 John Beatles
3 Paul Beatles
4 Mick Stones
5 John Beatles
6 Paul BeatlesR umí provést automatickou konverzi faktorů na znaky. Provede ji, ale vypíše i upovídané varování. Výsledek je nicméně perfektně použitelný a ve většině případů bude odpovídat přání uživatele.
Větší problém nastane, pokud se ve spojovaných tabulkách vyskytnou sloupce stejného jména a rozdílných datových typů, u kterých R neumí provést automatickou konverzi. V tomto případě jde o double a character:
band_members %>%
mutate(
name = rnorm(n())
) %>%
bind_rows(., band_members)Error in `bind_rows()`:
! Can't combine `..1$name` <double> and `..2$name` <character>.Tato operace se neprovede a R vrátí chybu.
Podobně jako bind_rows() funguje funkce bind_cols(). Tabulky ovšem neskládá “pod sebe”“, ale”vedle sebe”. Předpokladem jejího použití je opět shodná struktura tabulek. To v tomto případě znamená zejména to, že jedno pozorování je vždy na stejném řádku. Pozorování je tak vlastně identifikováno číslem řádku. Syntaxe je stejná jako u bind_rows():
bind_cols(band_members, band_members, band_members)New names:
• `name` -> `name...1`
• `band` -> `band...2`
• `name` -> `name...3`
• `band` -> `band...4`
• `name` -> `name...5`
• `band` -> `band...6`# A tibble: 3 × 6
name...1 band...2 name...3 band...4 name...5 band...6
<chr> <chr> <chr> <chr> <chr> <chr>
1 Mick Stones Mick Stones Mick Stones
2 John Beatles John Beatles John Beatles
3 Paul Beatles Paul Beatles Paul Beatles Za povšimnutí stojí, že pokud jsou ve spojovaných tabulkách shodná jména sloupců, bind_cols() je do výsledné tabulky přidá všechny. Aby se však zabránilo nepřípustné duplicitě ve jménech sloupců, rozšíří duplicitní jména o příponu.
Z logiky věci nejsou problém odlišné datové typy ve spojovaných tabulkách, ale problém můžou představovat tabulky s různým počtem řádků:
band_members %>%
slice_sample(n = 2) %>%
#sample_n(2) %>% # Obsolentní funkce
bind_cols(band_members,.)Error in `bind_cols()`:
! Can't recycle `..1` (size 3) to match `..2` (size 2).Protože u bind_cols() jsou pozorování fakticky identifikována číslem řádku, tak není možné takovou operaci smysluplně provést. bind_cols() v takovém případě nic nehádá, nic nepředpokládá ani nerecykluje, ale poctivě vyvěsí bílou vlajku a vrátí chybu.
Slučování tabulek s *_join()
Mutating joins
Slučování tabulek lze provádět pomocí různých slučovacích funkcí. Ty jsou v dplyr jednotně pojmenovány tak, že končí řetězcem *_join. Jejich základní skupina – tzv. mutating joins*, tj. slučovací funkce, které přidávají sloupce, se v zásadě chová jako “inteligentní” varianta bind_cols(). Pozorování však není definováno číslem řádku, ale proměnnou nebo kombinací více proměnných.
Pro ilustraci slučování jsou potřeba dvě tabulky. Vedle band_members využijeme dplyr::band_instruments:
band_instruments# A tibble: 3 × 2
name plays
<chr> <chr>
1 John guitar
2 Paul bass
3 Keith guitarPravděpodobně nejčastěji používanou slučovací funkcí je left_join():
left_join(
x,
y,
by = NULL,
copy = FALSE,
suffix = c(".x", ".y"),
...,
keep = NULL,
na_matches = c("na", "never"),
multiple = "all",
unmatched = "drop",
relationship = NULL
)Jako argument přijímá právě dvě tabulky x a y. Slučovací funkce v dplyr obecně umí pracovat pouze se dvěma tabulkami. Toto omezení je však možné obejít – viz dále.
Dalším důležitým parametrem je by jeho hodnota určuje, podle kterých sloupců se má provést slučování – tedy které sloupce definují pozorování. V případě, že je hodnota parametru NULL, potom se sloučení provede na základě všech sloupců, jejich jméno je v obou tabulkách. V tomto případě vrátí dplyr informaci o tom, které sloupce použil.
Příklad použití left_join():
left_join(band_members, band_instruments)Joining with `by = join_by(name)`# A tibble: 3 × 3
name band plays
<chr> <chr> <chr>
1 Mick Stones <NA>
2 John Beatles guitar
3 Paul Beatles bass left_join() funguje tak, že vrací všechny řádky z x a všechny sloupce z tabulky x i y. Řádky z x, pro které neexistuje shoda v tabulce y mají v připojených sloupcích NA.
V tomto příkladu nebyl vyplněn parametr by. left_join() tedy jako klíč pro slučování použil sloupec name, který se jako jediný vyskytoval v obou slučovaných tabulkách. Volání
left_join(band_members, band_instruments, by = "name")# A tibble: 3 × 3
name band plays
<chr> <chr> <chr>
1 Mick Stones <NA>
2 John Beatles guitar
3 Paul Beatles bass by pochopitelně vedlo ke stejným výsledkům.
Ve verzi dplyr 1.1.2 bylo joinovací funkce zcela přepracovány. Hlavní rozdíl pro uživatele spoučívá právě v parametru by. Ten nyní může přijímat jmená sloupců nebo hodnotu funkce join_by().
Slučování s pomocí jmen sloupců
V případě slučování tabulek, ve kterých se vyskytují shodná jména sloupců, která ovšem neidentifikují pozorování je nutné parametr by specifikovat. Sloučení tabulek se stejnými názvy sloupců by jinak dopadlo například takto:
left_join(band_members, band_members)Joining with `by = join_by(name, band)`# A tibble: 3 × 2
name band
<chr> <chr>
1 Mick Stones
2 John Beatles
3 Paul BeatlesVýsledkem by byla vstupní tabulka x. Pří specifikování identifikačního sloupce (například name) bude výsledek odlišný:
left_join(band_members, band_members, by = "name")# A tibble: 3 × 3
name band.x band.y
<chr> <chr> <chr>
1 Mick Stones Stones
2 John Beatles Beatles
3 Paul Beatles BeatlesSlučované tabulky v tomto případě obsahují sloupec se shodným jménem, který není použit ke slučování. V tom případě je tento sloupec (podobně jako u bind_cols()) přejmenován připojením přípony. Podobu přípony je možné specifikovat parametrem suffix:
left_join(band_members, band_members, by = "name", suffix = c(".prvni",".druhy"))# A tibble: 3 × 3
name band.prvni band.druhy
<chr> <chr> <chr>
1 Mick Stones Stones
2 John Beatles Beatles
3 Paul Beatles Beatles V předchozích příkladech byl parametr by použit pouze pro specifikaci jednoho sloupce, jehož jméno bylo přítomno v obou slučovaných tabulkách. Možností nastavení je však více:
bymůže obsahovat jména více sloupců zadaných jako nepojmenovaný vektor, napříkladby = c("name","band")bymůže obsahovat i pojmenovaný vektor. Ten má ale zvláštní interpretaci. Jméno každého prvku odpovídá v takovém případě jménu sloupce z tabulkyxa hodnota jménu sloupce z tabulkyy. To umožňuje slučování tabulek, i když tyto neobsahují ani jeden sloupec se shodným jménem. Praktickou ukázkou je následující příklad, který využívá tabulkudplyr::band_instruments2:
band_instruments2# A tibble: 3 × 2
artist plays
<chr> <chr>
1 John guitar
2 Paul bass
3 Keith guitarCílem je sloučit tabulky band_members a band_instruments2 podle jména hudebníka. Tato proměnná se však jmenuje name v band_members a artist v band_instruments2:
left_join(band_members, band_instruments2, by = c("name" = "artist"))# A tibble: 3 × 3
name band plays
<chr> <chr> <chr>
1 Mick Stones <NA>
2 John Beatles guitar
3 Paul Beatles bass Používání slučovacích funkcí však má svoje úskalí. Představme si situaci, kdy identifikace pozorování není jednoznačná – tedy situaci, kdy identifikátor pozorování odpovídá více řádkům. Vytvoříme tabulku band_instruments3, která bude právě tuto podmínku splňovat:
band_instruments3 <- bind_rows(band_instruments, band_instruments)
print(band_instruments3)# A tibble: 6 × 2
name plays
<chr> <chr>
1 John guitar
2 Paul bass
3 Keith guitar
4 John guitar
5 Paul bass
6 Keith guitarIdentifikátor – jméno hudebníka – teď není unikátní. Přináleží mu právě dva řádky. Následně tuto novou tabulku sloučíme s band_members:
left_join(band_members, band_instruments3, by = "name")# A tibble: 5 × 3
name band plays
<chr> <chr> <chr>
1 Mick Stones <NA>
2 John Beatles guitar
3 John Beatles guitar
4 Paul Beatles bass
5 Paul Beatles bass Zde je patrné, že výsledek může být problematický. Výsledná tabulka má větší počet řádků, než vstupní tabulka x – řádky, pro které bylo v tabulce y více záznamů se namnožily. dplyr tuto operaci provedl bez jakéhokoliv varování. Je proto kritické kontrolovat v průběhu sestavování datasetu konzistenci dat. Jinak se lehko může stát, že výsledná tabulka a analýza na ni postavená bude bezcenná.
Slučování tabulek s pomocí funkce join_by()
Standardní využití by umožňuje napojování tabulek pouze při shodě hodnot v použitých sloupcích. Použití funkce join_by(), kterou je možno vložit do parametru by joinovacích funkcí, toto omezení odstarňuje. Tradiční využití paramteru by se tak vlastně stává jenom speciálním případem specifikace funkce join_by().
Funkce join_by() umožňuje následující typy operací, pro jejichž fungování využijeme jednoduché tabulky definované v manuálu k dplyr:
sales <- tibble(
id = c(1L, 1L, 1L, 2L, 2L),
sale_date = as.Date(c("2018-12-31", "2019-01-02", "2019-01-05", "2019-01-04", "2019-01-01"))
)
sales# A tibble: 5 × 2
id sale_date
<int> <date>
1 1 2018-12-31
2 1 2019-01-02
3 1 2019-01-05
4 2 2019-01-04
5 2 2019-01-01promos <- tibble(
id = c(1L, 1L, 2L),
promo_date = as.Date(c("2019-01-01", "2019-01-05", "2019-01-02"))
)
promos# A tibble: 3 × 2
id promo_date
<int> <date>
1 1 2019-01-01
2 1 2019-01-05
3 2 2019-01-02- equality joins, kde se pozorování spojí při shodě hodnot – toto je právě ekvivalent tradičního nastavení
by. - inequality joins, které umožňují definovat “shodu” pomocí podmínek:
left_join(
sales,promos,
# Spoj řádky, které:
# 1) mají shodné id,
# 2) sales_date je větší nebo rovno promo_date
by = join_by(
id, sale_date >= promo_date
)
)# A tibble: 6 × 3
id sale_date promo_date
<int> <date> <date>
1 1 2018-12-31 NA
2 1 2019-01-02 2019-01-01
3 1 2019-01-05 2019-01-01
4 1 2019-01-05 2019-01-05
5 2 2019-01-04 2019-01-02
6 2 2019-01-01 NA - Rolling joins umožňují použití speciální funkce
closest(), která v rámci potenciálních matchů deifnovaných zadanou podmínkou vrátí nejbližší match. Výsledná tabulka obsahuje nejbliží match pro každý řádek z tabulkysales.
left_join(
sales,promos,
by = join_by(
id, closest(sale_date > promo_date)
)
)# A tibble: 5 × 3
id sale_date promo_date
<int> <date> <date>
1 1 2018-12-31 NA
2 1 2019-01-02 2019-01-01
3 1 2019-01-05 2019-01-01
4 2 2019-01-04 2019-01-02
5 2 2019-01-01 NA - Overlap joins umožňují využití speciálních funkcí
between(),within(), aoverlaps().
Další mutating joins
left_join() není jediný mutating join implementovaný v dplyr, další jsou následující:
right_join()je bratrleft_join(). Vrací sloupce zxiy, ale řádky zy.inner_join()vrací sloupce zxiy, ale pouze řádky, která jsou jak vx, tak vy.full_join()vrací všechny sloupce a všechny řádky zxay.
Aplikace
V tabulce ispv ponechte jenom pozorování, kde je průměrná mzda vyšší, než minimální mzda. Hodnota minimální mzdy se postupně mění. Její hodnoty jsou definovány v následující tabulce:
Wmin <- tribble(
~year,~Wmin,~WHmin,
2007,8000,48.1,
2013,8500,50.6,
2015,9200,55,
2016,9900,58.7,
2017,11000,66,
2018,12200,73.2,
2019,13350,79.8,
2020,14600,87.3,
2021,15200,90.5,
2022,16200,96.4
) Pozor! Tabulka Wmin obsahuje údaje jenom k letům, kdy došlo ke změně minimální mzdy. My však potřebujeme mít údaje pro všechny roky mezi lety 2007 a 2022. Potřebujeme tedy tabulku nejprve doplnit.
Wmin <- Wmin %>%
complete(year = 2007:2022) %>%
arrange(year) %>%
fill(Wmin,WHmin,.direction = "down")Nyní tabulku s minimální mzdou napojíme na tabulku ispv.
ispv %>%
left_join(.,Wmin)Joining with `by = join_by(year)`Error in `left_join()`:
! Can't join `x$year` with `y$year` due to incompatible types.
ℹ `x$year` is a <character>.
ℹ `y$year` is a <double>.R má tendenci dělat automatické konverze datových typů, ale ne vždy!
Wmin %>%
mutate(
year = as.character(year)
) %>%
left_join(ispv,.) %>%
mutate(
PRUMVYD = PRUMVYD %>% str_replace_all(",",".") %>% as.double()
) %>%
filter(
PRUMVYD >= WHmin
)Joining with `by = join_by(year)`# A tibble: 880 × 38
ICO IDZAM ROKNAR POHLAVI STOBC VZDELANI INVALD MISTOVP CZICSE CZISCO
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 9a1b22d03ab… 480 1985 1 CZ M Z CZ0100 1111 54141
2 b545141626d… 1639 1965 1 CZ H Z CZ0323 1111 82197
3 3fce46ceb84… 7854… 1961 1 CZ T Z CZ0427 1112 31155
4 55d7abb8e1c… 1163… 1956 2 CZ T Z CZ0100 1111 91122
5 902c3df93cd… 2077… 1983 2 CZ H Z CZ0513 1111 24339
6 9d30f64c730… 0525… 1983 1 CZ E Z CZ0806 1112 13213
7 7f9356f49ab… 399 1968 2 CZ T Z CZ0803 1112 81899
8 0530aa024e6… 55310 1981 2 CZ V Z CZ0204 1111 43220
9 13b3afe68f8… 12553 1980 1 CZ H Z CZ0805 1111 44125
10 17fcef127b8… 296 1953 2 CZ M Z CZ0643 1111 33131
# ℹ 870 more rows
# ℹ 28 more variables: VEDOUCI <chr>, KONTOPD <chr>, DOBAZAM <chr>,
# EVIDDNY <chr>, KONECEP <chr>, FONDSTA <chr>, FONDSJE <chr>, ODPRACD <chr>,
# PRESCAS <chr>, ABSCELK <chr>, ABSPLAC <chr>, ABSDOVOL <chr>,
# ABSNEMOC <chr>, ABSNEMZ <chr>, MZDA <chr>, POPRAV <chr>, PONEPRAV <chr>,
# PRIPPCAS <chr>, PRIPLAT <chr>, NAHRADY <chr>, NAHRNEMZ <chr>,
# POHOTOV <chr>, PRUMVYD <dbl>, ISCED <chr>, OBORVZD <chr>, year <chr>, …Filtering joins
Druhou skupinou slučovacích funkcí jsou tzv. filtering joins. Tyto funkce opět pracují nad dvěma tabulkami x a y, ale vždy vrací sloupce pouze z tabulky x.
První takovou funkcí je semi_join(), který vrací pouze ty řádky, které existují v obou tabulkách x i y. Je to vlastně blízký příbuzný inner_join().
Pro ilustraci fungování filtering joins můžeme porovnat výsledky těchto funkcí:
inner_join(band_members, band_instruments, by = "name")# A tibble: 2 × 3
name band plays
<chr> <chr> <chr>
1 John Beatles guitar
2 Paul Beatles bass semi_join(band_members, band_instruments, by = "name")# A tibble: 2 × 2
name band
<chr> <chr>
1 John Beatles
2 Paul Beatlesinner_join() vrací sloupce z obou tabulek – skutečně “slučuje”. semi_join() vrací sloupce pouze z první tabulky – spíše tedy filtruje na základě informací z druhé tabulky.
Druhou funkcí z této skupiny slučovacích funkcí je anti_join(), která je svým způsobem inverzní k semi_join(). Vrací řádky z x, které nejsou obsaženy v y:
anti_join(band_members, band_instruments, by = "name")# A tibble: 1 × 2
name band
<chr> <chr>
1 Mick StonesSlučování více tabulek
Všechny funkce *_join() pracují s dvěma tabulkami. V drtivé většině případů je to zcela postačující, nicméně najdou se i výjimky. V takovém případě je možné využit funkci reduce() z balíku purrr (součást tidyverse).
reduce(.x, .f, ..., .init)Funkce má dva základní argumenty:
-.x…je seznam (list) nebo atomický vektor -.f…je funkce přijímající 2 vstupy -...…dodatečné argumenty pro funkci .f
reduce() funguje tak, že provádí “akumulaci”. Nejprve aplikuje funkci .f na první dva prvky .x. V druhé iteraci aplikuje .f na výstup první iterace a na třetí prvek .x a tak dále.
list(band_members, band_members, band_members, band_instruments) %>%
reduce(., left_join, by = "name")# A tibble: 3 × 5
name band.x band.y band plays
<chr> <chr> <chr> <chr> <chr>
1 Mick Stones Stones Stones <NA>
2 John Beatles Beatles Beatles guitar
3 Paul Beatles Beatles Beatles bass Za pozornost stojí varianty jména sloupce band, které přesně odpovídají mechanismu fungování reduce(). V první iteraci nastal konflikt jmen sloupců. Obě slučované tabulky obsahovaly sloupec pojmenovaný band a proto ve výsledné tabulce dostaly příponu. V druhé iteraci již ke konfliktu nedošlo. Stará tabulka totiž obsahovala jména band.x a band.y a nová band. Sloupec z nové tabulky tak byl připojen bez změny jména.
Příklad by mohl pokračovat:
list(band_members, band_members, band_members, band_members) %>%
reduce(., left_join, by = "name")# A tibble: 3 × 5
name band.x band.y band.x.x band.y.y
<chr> <chr> <chr> <chr> <chr>
1 Mick Stones Stones Stones Stones
2 John Beatles Beatles Beatles Beatles
3 Paul Beatles Beatles Beatles Beatles