Skupina balíků sdružená v tidyverse představuje kompaktní sadu nástrojů pro práci s daty. Sdílejí datové struktury (tabulky v tidy formátu) i logiku ovládání. Bohužel podobná unifikace chybí u nástrojů, které výzkumník potřebuje pro ekonometrickou (statistickou) analýzu dat, která následuje po zpracování dat. Ekonometrické nástroje jsou v R rozptýleny v mnoha balících různé kvality, které nejsou žádným způsobem koordinovány nebo unifikovány. To velmi znepříjemňuje ekonometrickou analýzu dat v R. I přesto R poskytuje všechny základní a mnoho pokročilých nástrojů a v zásadě pokrývá všechny běžné potřeby výzkumníků.
Účelem této kapitoly není vysvětlovat teorii ekonometrické analýzy nebo diskutovat vhodnost nasazení jednotlivých metod nebo designu regresní analýzy (identifikační strategie), ale seznámit čtenáře se základní logikou fungování ekonometrických nástrojů v R. Právě základní logika fungování je totiž něco, co drtivá většina ekonometrických nástrojů v R sdílí.
Na počátku ekonometrické analýzy má výzkumník data a představu o tom, jak svět funguje (o data generujícím procesu). Pro naprostou většinu ekonometrických nástrojů (a všechny základní) je vhodné připravit si data do podoby tabulky v tidy formátu. Představa o fungování světa (tj. o vztazích mezi proměnnými v datové tabulce) se formalizuje do podoby modelu. Jeho podoba se předává R v podobě speciální datové třídy formula.
Data a specifikovaný model jsou nezbytnými vstupy pro estimátor. Estimátor je typicky funkce, která provede odhad parametrů modelu a vytvoří výstupní objekt. Tento objekt obsahuje typicky pouze samotný odhad parametrů modelu, tabulku dat použitých pro odhad, rezidua, vyrovnané hodnoty a další doplňující údaje. Typicky neobsahuje žádné testy, robustní směrodatné chyby a podobně. Analýza a zobrazení odhadu (výsledků) se v R typicky provádí pomocí specializovaných funkcí, pro které je výstup estimační funkce vstupem.
V této kapitole se naučíte:
Specifikovat model ve třídě Formula/formula
Použít základní estimační funkce
Provádět hromadně odhady více modelových specifikací na stejném vzorku dat
Provádět hromadně odhady jedné modelové specifikace na různých vzorcích dat
Exportovat výsledky do přehledných tabulek
Základní část kapitoly spočívá na moderním ekonometrickém balíku fixest.
V rozšiřujících materiálech najdete jak:
Provést základní diagnostické testy odhadu
Vypočítat robustní směrodatné chyby
15.1 Specifikace modelu pomocí formula
Fungování ekonometrických nástrojů můžeme ilustrovat na příkladu datasetu s výškou, váhou, věkem, sportem, a pohlavím sportovců, kteří se zúčastnili olympijských her v Londýně v roce 2012 (dostupný v VGAMdata::oly12):
# A tibble: 9,038 × 5
Height Weight Sex Age Sport
<dbl> <int> <chr> <int> <chr>
1 1.7 60 M 23 Judo
2 1.93 125 M 33 Athletics
3 1.87 76 M 30 Athletics
4 1.78 85 F 26 Athletics
5 1.82 80 M 27 Handball
# ℹ 9,033 more rows
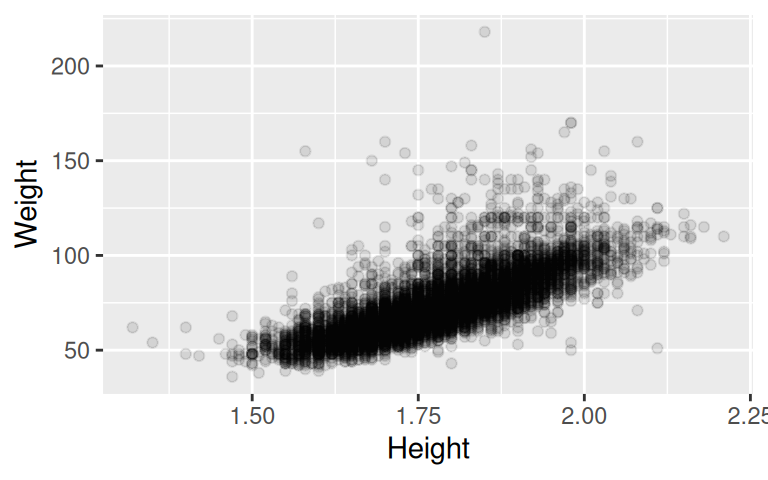
Nejprve nás bude zajímat vztah mezi váhou a výškou sportovců. Ten si můžeme vykreslit pomocí jednoduchého bodového grafu:
Zdá se, že existuje lineární vztah mezi váhou a výškou sportovců, který můžeme popsat rovnicí: \[Weight = \alpha + \beta Height + \varepsilon\] kde \(\alpha\) a \(\beta\) jsou neznámé parametry, které chceme odhadnout a \(\varepsilon\) je náhodná složka.
Tuto rovnici si můžeme představit jako přímku, která je proložena mrakem pozorování:
`geom_smooth()` using formula = 'y ~ x'
Rovnici však musíme zapsat tak, aby byla srozumitelná i pro R. K tomu slouží objekty třídy formula. Jejich formulace následuje syntax:
LHS ~ RHS
Tedy výrazy na levé straně (LHS) \(=\) (zastoupené znakem ~) výrazy na pravé straně (RHS). Rovnici vysvětlující váhu bychom tedy mohli popsat jako:
model <- Weight ~ Heightclass(model)
[1] "formula"
V ekonomii je závislá (vysvětlovaná) proměnná (tedy proměnná na levé straně rovnice) funkcí více než jedné nezávislé (vysvětlující) proměnné. Pokud bychom chtěli vysvětlovat váhu nejen výškou, ale i věkem, potom bychom rozšířili specifikaci následujícím způsobem:
model <- Weight ~ Height + Age
Dodatečná proměnné jsou přidávány pomocí +.
Za povšimnutí stojí, že při použití takovéto specifikace by byl model odhadnut s úrovňovou konstantou \(\alpha\) – i když není explicitně v rovnici přítomna. Explicitně se naopak musí zadat její nepřítomnost připojením -1 nebo 0:
Ve druhé je váha vysvětlována dummy (umělou proměnnou). Výraz Height >= 1.8 vytvoří logickou proměnnou, která je při volání estimační funkce transformována na vektor s hodnotami 1 a 0.
Není tedy potřeba vytvářet nové transformované sloupce v datové tabulce. To je velký rozdíl mezi R a Statou, Gretlem,… (Jakkoliv je v některých případech vytvoření transformovaných proměnných do tabulky doporučeníhodné.)
V rovnici může být přímo přítomna celá řada funkcí – s výjimkou těch, jejichž interpretace by nebyla jasná. Pokud bychom například chtěli odhadnout modelovou specifikaci
potom je nutná sdělit R, že má nejdříve sečíst Height a Age a pro vysvětlení Weight použít až výsledný součet. Pro tyto účely se používá funkce I(). Ta sděluje, že se mají nejprve provést operace definované uvnitř funkce a pro odhad použít až výsledek.
Výše uvedený příklad by se tak R tlumočil jako
model <- Weight ~I(Height + Age)
Třída formula umožňuje jednoduše jednoduše definovat i interakční členy pomocí operátorů dvojtečka (:) a hvězdička (*):
model <- Weight ~ Height:Sex
Chápe R jako
\[Weight = \alpha + \beta Height\times Sex_{male} + \gamma Height\times Sex_{female} + \varepsilon\] Tato rovnice vyjadřuje možný odlišný mezní efekt výšky na váhu u mužů a žen. Výsledné proložení mrakem pozorování by se tak v bodovém grafu výše vlastně rozpadlo na dvě přímky s odlišným sklonem (parametry \(\beta\) a \(\gamma\)) a shodnou úrovňovou konstantou \(\alpha\).
Další možností jak popsat interakci proměnných je *:
model <- Weight ~ Height*Sex
Tato formula odpovídá jiné rovnici:
\[Weight = \alpha + \beta Height + \epsilon Sex_{male} + \gamma Height\times Sex_{male} + \varepsilon\] Tato specifikace umožňuje odlišnost regresní křivky pro muže a ženy jak ve sklonu, tak v úrovňové konstantě.
Zvláštní význam má i symbol stříšky (^). Rovnici
\[Weight = \alpha + \beta_1 Height + \beta_2 Age + \beta_3 Sex_{male} + \gamma_1 Height\times Sex_{male} + \gamma_2 Height\times Age + \gamma_3 Sex_{male}\times Age + \varepsilon\] můžeme zapsat jako:
model <- Weight ~ (Height + Age + Sex)^2
Výraz se přeloží tak, že výsledná rovnice obsahuje jednotlivé proměnné a také jejich interakce do, v tomto případě, druhého řádu.
Pro třídu formula jsou implementovány i některé zajímavé metody. Velmi užitečná je například funkce update() s velmi prostou syntaxí:
update(old,new,...)
Kde old je původní rovnice a new pravidla, která stanovují, jak se původní rovnice má upravit.
model <- Weight ~ Height + Ageprint(model)
Weight ~ Height + Age
Takto můžeme zachovat všechny proměnné – reprezentované pomocí . a jen některou přidat nebo odebrat:
model %>%update(. ~ . -Age)
Weight ~ Height
Nebo je možné nahradit celou stranu rovnice:
model %>%update(. ~ Age)
Weight ~ Age
Objekty třídy formula a moderní balíčky v R
Většina moderních balíků pro datovou analýzu používá specifikaci modelů pomocí objektů třídy formula. Její možnosti jsou však omezené – zejména pokud jde o tzv. víceprvkové rovnice, které se používají stále později. Příkladem užití takové víceprvkové rovnice může být specifikace fixních efektů, který používá balík fixest (nebo—trochu jinak—i balík lfe):
Weight ~ Height + Age | country
Druhý “prvek” rovnice je oddělen znakem |. V tomto případě druhý prvek rovnice specifikuje proměnnou, který určuje použité fixní efekty. Víceprvkové rovnice nefungují správně, pokud jsou definovány jako objekty třídy formula. Je potřeba je definovat s pomocí balíku Formula. Objekt třídy formula lze konvertovat do třídy Formula pomocí funkce Formula::as.Formula().
15.2 Odhad modelu
Při volání estimační funkce se dohromady spojí všechny tři komponenty: modelová specifikace, data a estimátor.
Základní estimační funkcí je lm(), určená pro odhad lineárních modelů. Funkce přijímá celou řadu parametrů:
lm(formula, data, subset, weights, na.action, method ="qr", model =TRUE, x =FALSE, y =FALSE, qr =TRUE, singular.ok =TRUE, contrasts =NULL, offset, ...)
Mezi základní patří:
formula je objekt třídy “formula”, který obsahuje symbolický popis rovnice, jejíž parametry se mají odhadnout.
data je tabulka (data.frame) která obsahuje data, která se mají použít. Jména sloupců v tabulce musí odpovídat proměnným použitým v parametru formula. Datová tabulka nemusí být specifikována. Pokud je tento parametr prázdný, potom R interpretuje jména v modelu jako jména proměnných z prostředí, ze kterého je funkce lm() volána.
subset je nepovinný parametr, který určuje, které pozorování (řádky) se mají použít pro odhad
weights je vektor vah. Pokud není zadán je pro odhad použit obyčejný OLS estimátor, ve kterém mají všechna pozorování stejnou váhu. V případě zadání vah je vráceno WLS.
Estimačních funkcí v R je mnoho. Většina z nich však používá (teměř) stejný interface jako lm().
Vytvoření matice plánu
Pro odhad použijeme model v následující specifikaci:
model <- Weight ~ Height + Age +I(Age^2) + Sex
Proměnné Weight, Height a Age jsou numerické spojité proměnné. Proměnná Sex je zcela jiný případ. Jsou to kategoriální proměnná, se dvěma úrovněmi (M – muž, F – žena). Taková proměnná nemůže vstoupit do regrese přímo. Je nutné ji transformovat na matici nul a jedniček. Transformovaná matice bude mít vždy o jeden sloupec méně, než kolik má transformovaná proměnná úrovní.
Estimační funkce si všechny vstupní faktory transformuje sama pomocí interního volání funkce model.matrix(). V rámci volání tento funkce se provedou i požadované transformace dat. V případě našeho modelu vytvoření druhé mocniny věku. Výsledkem volání model.matrix() je tedy matice plánu:
Funkce model.matrix() provede požadované transformace numerických proměnných (přidán sloupec I(Age^2)) a pokud najde jinou než numerickou proměnnou (factor) provede jejich transformaci do matice binárních proměnných. Při této transformaci postupuje následovně. Prohlédne si faktor a určí referenční úroveň (level). Ta nebude ve výsledné matici obsažena, pokud by byla, model by nešel odhadnout. Pro každou zbývající úroveň vytvoří vektor, který nabývá hodnoty 1 pro pozorování s danou úrovní faktoru. V příkladu výše si model.frame() vybral jako referenční úroveň hodnotu F a vytvořil vektor SexM, který nabývá hodnoty 1 pro muže a 0 ve všech ostatních případech.
Pokud by byla vstupní kategoriální proměnná třídy character, potom by ji model.frame()nejprve transformoval na factor a pokračoval tak, jak je popsáno výše. Toto chování může být motivem pro to, aby uživatel sám provedl konverzi na faktor. Třída faktor totiž umožňuje nastavit, která úroveň má být použita jako referenční. Toho můžeme docílit pomocí několika cest.
První variantou je konverze do factor s pomocí base::factor(). Tato funkce umožňuje uživateli zadat vektor možných úrovní. První z nich se potom nastaví jako referenční:
factor(Sex$oly12, c("M","F"))
Tento postup lze aplikovat i na proměnné, které již jsou factor. Nevýhodou je nutnost zadávat všechny úrovně. Podobnou variantou je použití funkce forcats::as_factor(). Ta má vlastnost, že pořadí úrovní stanoví podle podle pořadí jejich výskytu v transformovaném vektoru. Problém této funkce je, že pracuje zvláštně s chybějícími hodnotami. (To se pravděpodobně bude během vývoje balíku ještě měnit.)
Další principiálně odlišnou variantou je nastavení referenční úrovně pomocí funkce stats::relevel() (alternativně forcats::fct_relevel()). Ta umožňuje prosté nastavení referenční úrovně:
factor(Sex$oly12) %>%relevel("M")
Po změně referenční úrovně bude výsledek následující:
Zejména v rámci průzkumu dat je zajímavá varianta provést konverzi na faktor v rámci modelu (formula) – všimněte si, že může být aplikována i na numerickou proměnnou:
Weight ~ Height +factor(Age) + Sex
Konverze numerických hodnot do faktoru je poměrně častá zvláště u dotazníkových dat, kde čísla mohou pouze kódovat hodnoty kategoriální proměnné. Dalším případem je například vytvoření fixních efektů pro roky.
Funkce model.matrix(), kterou si estimační funkce volá interně tedy vytvoří matici plánu, která je následně použité při samotném odhadu parametrů modelu. Odhadová procedura si liší podle použité estimační funkce. V případě lm() je to QR dekompozice (https://en.wikipedia.org/wiki/QR_decomposition), při použití glm() jsou to například různé numerické optimalizační algoritmy (defaultně IWLS:https://en.wikipedia.org/wiki/Iteratively_reweighted_least_squares).
15.3 Odhad lineárního modelu s balíkem fixest
V datové analýze se často používá balíček fixest, který obsahuje odhadové funkce feols(), feglm() () a fepois(). Výhodou tohoto balíku je:
schopnost rychle odhadovat modely s velkým počtem fixníxh efektů,
díky modifikovaným formulím (fml) odhadovat v rámci jednoho volání funkce více specifikací,
stejně jako více specifikací na více subsamplech a
zahrnout odhad robustních chyb do výstupního objektu bez nutnosti jeho zpětné modifikace.
V tento moment jsou podstatné dvě odlišnosti oproti lm(). fixest rozumí vlastní modifikované verzi třídy fromula, která se jmenuje fml. Ta umožňuje nejen specifikovat víceprvkové rovnice, ale navíc i používat dodatečné speciální funkce.
Víceprvková rovnice se používá pro identifikaci proměnných, které se mají použít specifikaci fixních efektů. Rovnice
y ~ x | a + b
tak říká, že se y má regresovat na konstantu a proměnnou x s použitím proměnných a a b jako fixních efektů. V tomto případě není důležitý datový typ proměnných a a b – mouhý být typu factor, character, nebo třeba integer. Odhadová funkce použije tyto proměnné k demeanování matice plánu. To zásadně zrychlí odahad modelu. Toto zrychlení je zvláště markantní u ML modelů a při velkém počtu fixních efektů. Funkce ale následně už nevrátí odhady koeficientů pro jednotlivé fixní efekty. Pokud je potřeba je odhadnout, potom je nutné příslušnou proměnnou zařadit do “hlavní” části rovnice – zde například pro a:
y ~ x +factor(a) | b
fixest respektive fml nepoužívá jen víceprvkové rovnice. Umožňuje i použití speciálních funkcí – jak ukazuje následující příklad:
c(y1, y2) ~ x1 +csw(x2, x2^2) |sw0(species)
Použity jsou v ní tři speciální funkce. Na levé straně rovnice je použita funkce c(), která říká, že se modelová specifikace má odhadnout zvlášt pro dvě (mohlo bych jich být samozřejmě i více) závislé proměnné: y1 a y2. Zbývající dvě speciální funkce jsou příkladem tzv. stepwise funkcí. fixest jich má naimplementováno celkem pět:
sw()…nahrazuje sekvenčně členy uvedené ve funkci. Odhad rovnice y ~ x0 + sw(x1, x2) by tak vedl k odhadu dvou rovnic: y ~ x0 + x1 a y ~ x0 + x2.
sw0()…funguje podobně jako sw(), ale přidává i odhad bez proměnných uvedených ve funkci sw0(). Příklad y ~ x0 + sw0(x1, x2) by tak vedl k odhadu tří specifikací: y ~ x0 + x1, y ~ x0 + x2 a y ~ x0.
csw()…přidává uvedené proměnné do modelu kumulativně. Výsledkem y ~ x0 + csw(x1, x2) by tak byl odhad specifikací y ~ x0 + x1 a y ~ x0 + x1 +x2.
csw0()…podobně jako sw0() přidává variantu bez proměnných uvedených v csw0().
mvsw()…odhaduje odhady se všemi kombinacemi proměnných uvedených ve funkci.
Balík fixest nám tedy v jedné rovnici umožňuje “schovat” celý balík specifikací.
Oproti lm() umožňuje fixest odhadnout různé typy standardních chyb již v rámci volání základní estimační funkce. Pro nastavení této funkcionality slouží parametry vcov a cluster.
Parametr vcov přijímá (pro detaily viz nápověda):
typ standardních chyb: iid, hetero, twoway a další. Pokud je daný typ určený pro panelová data, potom je nutné zadat paramtr panel.id, který specifikuje, které proměnné identifikují pruřezovou (např. ID země) a časovou jednotku (např. rok).
výstupní objekt ze speciálních funkcí. Tímto zpúsobem fixest implemetnuje Conley standard errors, které zohledňují prostorovou autokorelace reziduí.
externě vypočítanou koverianční matici.
V případě klastrování chyb je potřeba použít parametr cluster, který přijímá jednostrannou rovnici obshující proměnné definující klastry pozorování.
Následující volání funkce vrací OLS odhady koeficientů v regresy váhy na výšku. Pohlaví je použito jako fixní efekty a standardní chyby jsou klastrovány na úrovni jednotlivých sportů:
Na datech ISPV zkusím odhadnout tzv. gender pay gap. Připomínám, že data nejsou čištěná a jsou náhodně zpermutované – výsledky analýz tudíž nebudou dávat žádný smysl.
Specificky budeme regresovat logaritmus mzdy na dummy pro ženu a sadu vysvětlujících proměnných: tenure (dobu zaměstnání), ISCO, délku zkušeností a její druhou mocninu a dummy pro cizince.
Hint: Baterii odhadnutých modelů je potřeba nějak vypsat do tabulky. K tomu slouží funkce fixest::etable().
NOTE: 829 observations removed because of NA and infinite values (LHS: 101, RHS: 808).
|-> this msg only concerns the variables common to all estimations
Notes from the estimations:
[x 1] The variable 'ISCO19' has been removed because of collinearity (see
$collin.var).
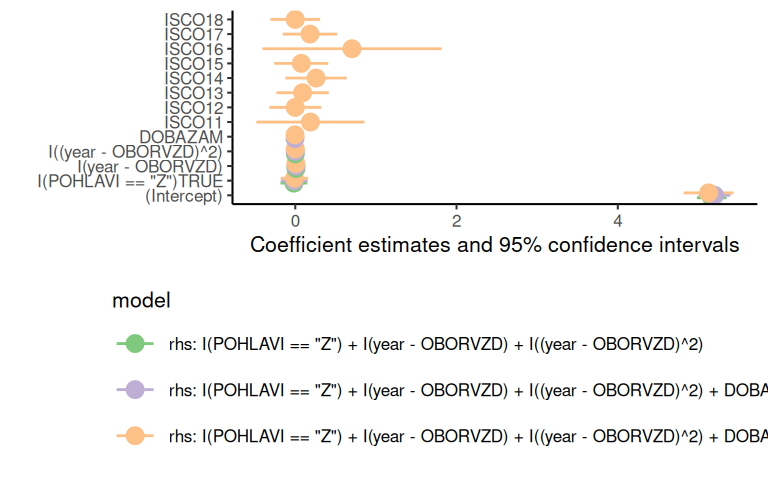
Data obsahují IČO zaměstnavatelů. Zkusíme je vložit do regrese jako fixní efekt a porovnáme výsledky s nimi a bez nich. ISCO nyní také definujeme jako fixní efekt.
NOTE: 829 observations removed because of NA and infinite values (LHS: 101, RHS: 808).
|-> this msg only concerns the variables common to all estimations
Nyní můžeme zkusit odhadnout specifikaci bez fixních efektů pro každé pohlaví (POHLAVI) zvlášť. Pro odhad stejné sady rovnic na různých dílčích vzorcích lze ve fixest použít parametry split nebo fsplit z níchž oba přijímají jednostranou rovnici idetifikující proměnnou, která definuje vzorky. V případě použití split se rovnice odhnou jen pro dílčí vzorky. U fsplit se specifikace odhadne i pro plný vzorek.
Omezení této varianty je, že se vzorky nemohou překrývat.
(Zvláštní hodnoty v tabulkách jsou dány malým počtem pozorování.)
fixest a panelová data
Odhadhové funkce mají i další vlastnosti, které se hodí pro práci s panelovými daty. První z nich je parametr panel.id, který umožnǔje (jako jednostrannou rovnici) identifikovat ID průřezové a časové jednotky.
V případě panelových dat je možné použít speciální funkci, která vytváří zpožděné (\(t-n\))/zrychlené (\(t+n\)) proměnné: l()/f(). Existuje i funkce, která vytváří diference: d(). Například můžeme nyní vysvětlovat mzdy zpožděným ISCO:
NOTE: 829 observations removed because of NA and infinite values (LHS: 101, RHS: 808).
|-> this msg only concerns the variables common to all estimations
Notes from the estimations:
[x 1] The variable 'ISCO19' has been removed because of collinearity (see
$collin.var).
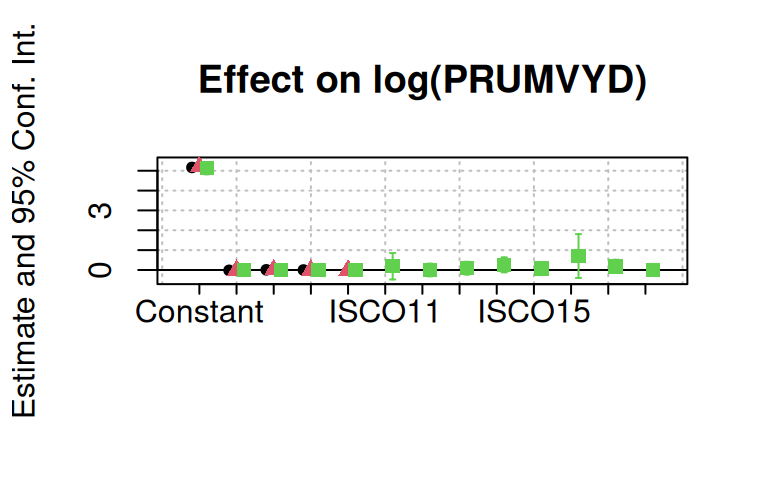
…nebo pro prezentaci můžete využít funkce z jiných balíků. Za pozornost slouží zejména moderní balík modelsummary a funkce modelplot().
NOTE: 829 observations removed because of NA and infinite values (LHS: 101, RHS: 808).
|-> this msg only concerns the variables common to all estimations
Notes from the estimations:
[x 1] The variable 'ISCO19' has been removed because of collinearity (see
$collin.var).
p
Její obrovskou výhodou je, že produkuje objekt třídy ggplot, který lze dále modifikovat:
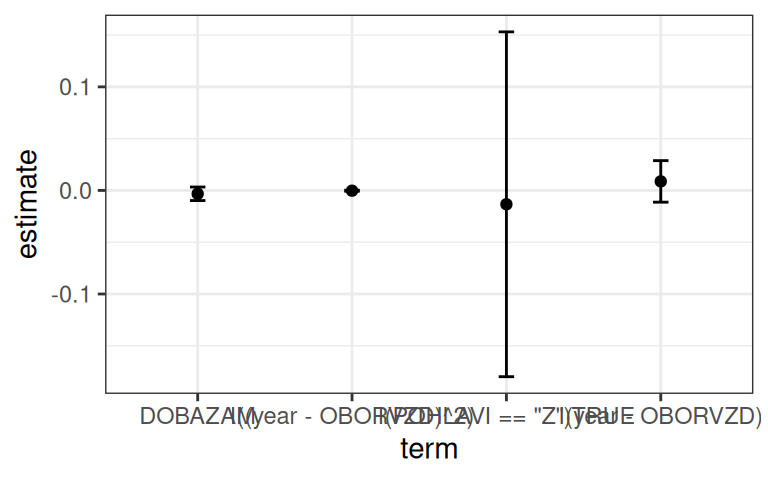
Největší svobodu ve vizualizaci výsledků dává uživateli manuální zpracování odahdů. Zde je ale malý rpoblém Balí ggplot umožňuje pracovat s tabulkami – nikoliv objekty, které produkují odhadové funkce. Ty je nutné konverotvat na tabulky. Přesně tuto funkcionalitu posktuje balík broom. Základní funkcí balíků, je tidy(), která konvertuje různé objekty na tabulky – z výsledků regrese tak například vytváří tabulku s koeficienty:
Nevýhodou broom je omezená podpora modelů/objektů. Pro každou třídu objektů musí být v balíku implementována zvláštní funkce – například tidy.lm() atp.
S tabulku vzniklou z tidy() můžeme vytvořit zcela vlastní vizualizaci:
NOTE: 829 observations removed because of NA and infinite values (LHS: 101, RHS: 808).
15.4 Odhad více modelů
Často můžeme chtít odhadnout model v různých specifikacích, nebo na různých vzorcích dat.
Odhad různých specifikací na stejných datech
Častá úloha je odhad různých modelových specifikací na stejném vzorku pozorování. fixest má podobný iterátor vestavěný a lze Pro tyto účely doporučuji následující postup:
Vytvořit si list se všemi rovnicemi (specifikacemi)
Odhadnout model pro všechny specifikace pomocí funkce map() z balíku purrr
Nejprve vytvoříme různé modelové specifikace s pomocí funkce update():
Models <-list(# Baseline model model,# Přidána interakce Sex*Height model %>%update(.~. + Sex*Height),# Přidán fixní efekt na zemi původu atleta model %>%update(.~. +factor(Country)))
Nyní pomocí purrr::map() zavoláme lm() na všechny prvky listu Models – tedy na všechny modelové specifikace:
Spec_models <- purrr::map(Models, lm, data = VGAMdata::oly12)Spec_models <- purrr::map(Models, function(x) lm(x, data = VGAMdata::oly12))Spec_models <- purrr::map(Models, ~lm(., data = VGAMdata::oly12))
Všechny tři výše uvedené způsoby použití map() jsou v pořádku.
Výsledné objekty jsou nyní uložené jako položky listu Spec_models. K nim můžeme přistupovat pomocí subsetování:
Spec_models[[2]] %>% summary
Call:
lm(formula = ., data = VGAMdata::oly12)
Residuals:
Min 1Q Median 3Q Max
-59.122 -5.646 -1.235 3.622 135.458
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -78.890968 3.402356 -23.187 < 2e-16 ***
Height 78.901728 1.814233 43.490 < 2e-16 ***
Age 0.392204 0.108875 3.602 0.000317 ***
I(Age^2) -0.003842 0.001807 -2.126 0.033527 *
SexM -39.474467 4.065283 -9.710 < 2e-16 ***
Height:SexM 25.695023 2.313338 11.107 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 10.06 on 9032 degrees of freedom
(1346 observations deleted due to missingness)
Multiple R-squared: 0.6084, Adjusted R-squared: 0.6082
F-statistic: 2807 on 5 and 9032 DF, p-value: < 2.2e-16
Odhad modelu na dílčích datech
Základní model můžeme odhadnout na různých vzorcích dat – v tomto případě pro různé sporty (proměnná Sport). Pro podobnou operaci existuje více přístupů. Historicky byla pro takové operace určena funkce dplyr::do(). Ta však bude v budoucnosti v balíku dplyr nahrazena a není ještě zcela jasné jak.
Dobrou variantou je postup analogický k odhadu více modelů na stejných datech. Nyní chceme odhadnout stejný model na různých datech. V předchozím případě jsme přes list rovnic iterovali pomocí funkce map(). Nyní bychom chtěli iterovat přes list tibblů. Ten vytvoříme pomocí funkce split() z base R.
Vstupy split() bude úplný tibble a pravostranná formule se jménem vektoru, podle kterého se má tento tibble rozdělit na menší tibblíky (bylo by možné použít přímo i tento vektor ve tvaru .$Sport). Typicky je tento vektor přímo součástí vstupního tibble. To není problém – můžeme využí placeholder .. Dejme tomu, že chceme odhadnout parametry pro každý sport zvlášť:
Sport_models <- oly12 %>%split(~ Sport) %>%map(# Zde si pomáháme anonymní funkcí, která nám pomůže doručit data# do správného parametru funkce lm()function(x) lm(Models[[1]], data = x) )
Analogicky lze použít funkci group_split() z dplyr, která rozdělí tabulku na list dílčích tabulek podle zgrupování. V takovém případě by celý kód vypadal následovně:
oly12 %>%group_by(Sport) %>%group_split() %>%map(function(x) lm(Models[[1]], data = x) )
Výsledná proměnná je list, který obsahuje odhadnuté modely:
Sport_models[1:3] %>%print()
$Archery
Call:
lm(formula = Models[[1]], data = x)
Coefficients:
(Intercept) Height Age I(Age^2) SexM
-45.146045 56.714558 0.459166 0.002153 10.191336
$Athletics
Call:
lm(formula = Models[[1]], data = x)
Coefficients:
(Intercept) Height Age I(Age^2) SexM
-145.12558 123.04350 -0.40467 0.01024 2.15605
$Badminton
Call:
lm(formula = Models[[1]], data = x)
Coefficients:
(Intercept) Height Age I(Age^2) SexM
-70.285717 75.702484 0.093450 0.001788 3.787492
S modely uloženými v seznamu. Následující kód například opět za využívá map(). Pomocí broom::glance() vytvoří tabulku modelů seřazenou sestupně podle adjustovaného koeficientu determinace:
Sport_models %>%# Varinata map_dfr() je ekvivalentní k map() %>% bind_rows()map_dfr(glance) %>%arrange(desc(adj.r.squared)) %>%print()
(Pozn. takové řazení je užitečné jenom ve velmi omezeném počtu případů.)
15.5 Tvorba regresních tabulek
Existuje mnoho balíků, které umožňují vytvořit regresní tabulku, formátovat ji, a nakonec ji exportovat do různých formátů. Historicky oblíbený balík je stargazer, ten už ale byl nahrazen modernějšími alternativami. Těch je velmi mnoho a není jednoduché některou z nich doporučit.
Základní funkcionalitu poskytuje funkce etable() z balíku fixest, která nabízí exporty do data.frame a formátu tex. Pro jednoduché aplikace může být zcela dostačující. Pro složitější aplikace se jako perspektivní jeví kombinace balíků modelsummary pro tvorbu tabulek a gt pro jejich formátování. Balík modelsummary navíc implementuje nástroje pro tvorbu deskriptivních statistik.
Všechny jsou uloženy do jednoho objektu eml třídy fixest_multi, což je fakticky list objektů třídy fixest. Tuto třídu modelsummary podporuje – což není automatické.
Základní funkcí je modelsummary(), která umí zpracovat jednolivý model, jejich list a pojemnovaný list. Tato funkce má (v porovnání třeba se stargazer) relativně uměřený počet parametrů:
output…umožňuje zadat jméno výstupního souboru (formáty docx, html, tex, xlsx, txt, csv a další) nebo typ výstupního objektu. Zajímavou varinatou je třeba data.frame a gt, který vytvoří výstupní objekt, který lze dále upravovat s pomocí balíku gt.
fmt…upravuje formátování čísel. V základním nastavení přijímá počet desetinných míst, na které se má zaokrouhlovat. Možností je však mnohem více – viz nápověda.
estimate…umožňuje formátovat reportování odhadů. Nastavení “{estimate}{stars}” například produkuje u nás obvyklé značení statistické významnosti s pomocí hvězdiček.
statistic…parametr analogický k estimate.
stars…definuje, jak jsou vytvářeny hvězdičky signalizující statistickou významnost. Pro nás obvyklou varinatu například generuje nastavení c('*' = .1, '**' = .05, '***' = 0.01)
S těmito paramatry mužeme tabulku velmi přiblížit požadovanému výstupu:
Taková tabulka však stále obsahuje pro čtenáře nesrozumitelná jména proměnných a obrovský počet (často zbytečných) statistik. To se dá ovlivnit nastavením dalších parametrů coef_map a gof_map, pomocí kterých lze měnit nejen popisky, ale i pořadí proměnných:
15.6 Export a fromátování tabulek s balíkem gt (TBD)
Balík modelsummary umí vytvářet a prostřednistvím parametru output i exportovat tabulky do mnoha různých formátů. Jednou z možností je i output = "gt". V tom případě vytoří modelsummary datovou sturkturu, kterou lze dále modifikovat nástroji z balíku gt, který je určen výhradně pro porkočilé formátování tabulek. Taková funkcionalita je zvláště užitečná v případě tvorby automatizovaných dokumentů v RMarkdown (soubory .Rmd) nebo Quarto (soubory .qmd), které umožňují v jednom souboru kombinovat text, kódy i grafické výstupy. (Například tato kniha je vytvořená v Quartu.)
Poznámka: gt je jedním z mnoha balíků, které umožňují fromátování tabulek. Mezi další patří třeba DT, flextable, formattable, huxtable a ftextra. Balík gt se však aktivně vyvíjí a v kombinaci s modelsummary představuje mocnou kombinaci. Naučit se gt je však docela velká investice, která se vyplatí právě zejména u tvorby automatizovaných dokumentů.
Pro ukázku použití gt vytvoříme datovou sturkturu ve formátu připraveného pro gt:
Za povšimnutí stojí, že objekt obsahuje skutečně pouze odhad – data, odhadnuté koeficienty, rezidua, vyrovnané hodnoty a dodatečné informace. Neobsahuje žádné dodatečné výpočty jako například diagnostické testy.
Pro objekty třídy lm existuje metoda generické funkce print(). Její výstupy však nejsou nijak zvlášť informativní:
print(est_model)
Call:
lm(formula = model, data = oly12)
Coefficients:
(Intercept) Height Age I(Age^2) SexM
-1.060e+02 9.463e+01 4.097e-01 -4.094e-03 5.592e+00
Obsahuje jen použité volání a odhadnuté hodnoty koeficientů. Více se dozvíme pomocí funkce summary():
summary(est_model)
Call:
lm(formula = model, data = oly12)
Residuals:
Min 1Q Median 3Q Max
-56.334 -5.717 -1.336 3.756 135.665
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.060e+02 2.385e+00 -44.444 < 2e-16 ***
Height 9.463e+01 1.141e+00 82.918 < 2e-16 ***
Age 4.097e-01 1.096e-01 3.738 0.000187 ***
I(Age^2) -4.094e-03 1.819e-03 -2.250 0.024442 *
SexM 5.592e+00 2.560e-01 21.840 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 10.13 on 9033 degrees of freedom
Multiple R-squared: 0.6031, Adjusted R-squared: 0.6029
F-statistic: 3431 on 4 and 9033 DF, p-value: < 2.2e-16
V tomto případě vidíme kromě odhadů koeficientů i směrodatné chyby a výsledky testů statistické významnosti koeficientů (v tomto případě t-testů). Výstup je také doplněn několika dalšími údaji jako je výsledek F-testu a (adjustovaný) koeficient determinace. Funkce summary() poskytuje rychlý pohled na výsledky, nicméně ten může být zavádějící. Funkce totiž vrací pouze standardní výstupy. Nijak například nereflektuje možné zkreslení odhadu směrodatných odchylek kvůli heteroskedasticitě a podobně. Všimněte si, že summary() používá méně obvyklé – a přísnější – hvězdičkové značení!
Práce s výsledkem odhadů
V R najdete řadu specializovaných funkcí, které dokážou z výsledného modelu získávat, nebo na jeho základě dopočítávat užitečné informace. Tabulka obsahuje jejich základní přehled:
Funkce
Popis
coefficients(), coefs()
Vrací odhadnuté koeficienty – obsah .$coefficients
residuals(), resid()
Vrací vektor reziduí – pro objekty lm je výstup identický s .$residuals
fitted.values()
Vrací očekávané hodnoty – obsah .$fitted.values
predict()
Umožňuje dopočítat predikce pro jiná data, než na kterých byl model odhadnut
plot()
Vrací diagnostické grafy vytvořené pomocí základní grafiky (ne v ggplot2)
confint()
Vrací konfidenční intervaly pro odhady koeficientů
deviance()
Vrací MSE – průměr čtverců reziduí
vcov()
Vrací odhad kovarianční matice
logLik()
Vrací log-likelihood
AIC()
Vrací Akaikovo informační krítérium (AIC)
BIC()
Vrací Schwarzovo Bayesian kritérium (BIC)
nobs()
Vrací počet pozorování
Pro některé účely je vhodné seznámit se i se sofistikovanějšími funkcemi. Pro účely diagnostiky nebo okometrického posouzení kvality vyrovnání může být užitečné výsledky odhadu vizualizovat. Výsledky jsou však schované ve zvláštním objektu a ne v tabulce, kterou potřebujeme pro použití s ggplot2. Pro transformaci různých objektů do tabulky existuje v ggplot2 funkce fortify(). Stejnou funkcionalitu poskytuje i balík broom. Pro objekty třídy lm je ekvivalentem funkce broom::augment():
# A tibble: 9,038 × 11
Weight Height Age `I(Age^2)` Sex .fitted .resid .hat .sigma .cooksd
<int> <dbl> <int> <I<dbl>> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 60 1.7 23 529 M 67.7 -7.71 0.000453 10.1 5.26e-5
2 125 1.93 33 1089 M 91.3 33.7 0.000474 10.1 1.05e-3
3 76 1.87 30 900 M 85.2 -9.15 0.000299 10.1 4.89e-5
4 85 1.78 26 676 F 70.3 14.7 0.000336 10.1 1.41e-4
5 80 1.82 27 729 M 79.9 0.110 0.000235 10.1 5.58e-9
# ℹ 9,033 more rows
# ℹ 1 more variable: .std.resid <dbl>
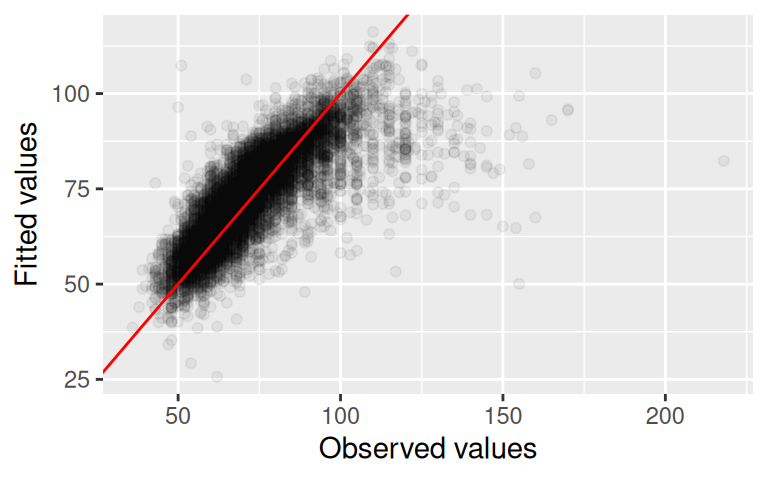
Pozor, broom navrací tibble. Proto je užitečné výstup do tibble konvertovat. Výsledek je již jednoduše použitelný pro vizualizaci pomocí ggplot2. Následující obrázek ukazuje korelaci pozorovaných (observed) a vyrovnaných (fitted) hodnot. Do obrázku je přidána pomocí geom_abline() i osa kvadrantu na která se pozorované a vyrovnané hodnoty rovnají.
Balík broom obsahuje i další užitečné funkce: tidy() a glance(). Funkce tidy() vrací tabulku s odhady parametrů, směrodatných odchylek, testových statistik a p-hodnot:
Tyto funkce jsou mimořádně užitečné při strojovém zpracovávání velkého množství odhadnutých modelů. Funkce z balíku broom přitom neslouží jenom pro převádění objektů lm do tabulky. Jejich záběr je mnohem obecnější a obsahují metody pro mnohem více tříd objektů.
Zvláštní pozornost se vyplatí věnovat funkci predict(). Ty v základní konfiguraci vrací prostě vyrovnané hodnoty:
all.equal(predict(est_model),fitted(est_model))
[1] TRUE
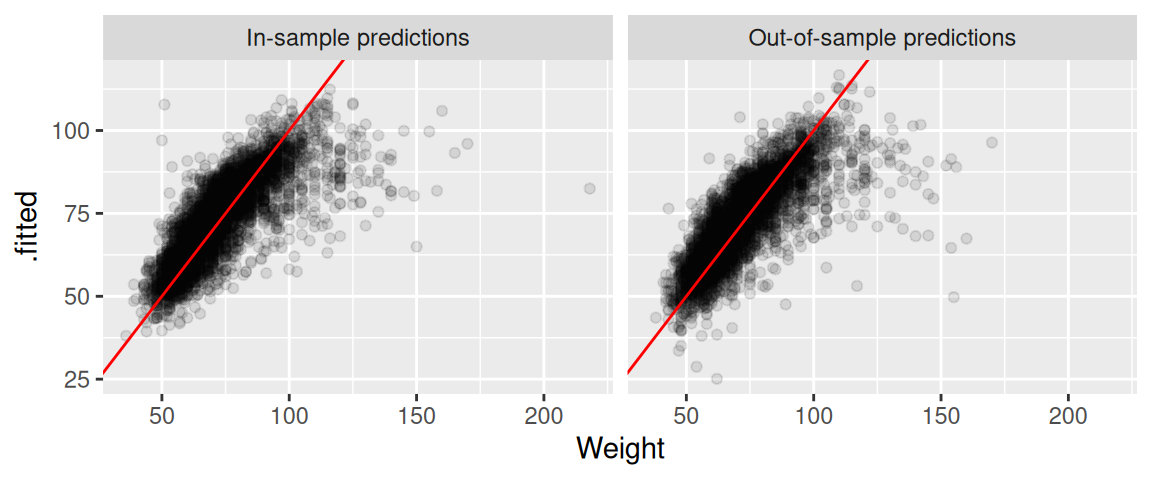
Při mnoha aplikacích nás spíše zajímá schopnost modelu predikovat out-of-sample. Tedy predikovat hodnoty vysvětlované proměnné na jiném vzorku dat, než který byl použit k odhadu parametrů. I pro tento účel se hodí funkce predict().
Nejprve si tabulku oly12 rozdělíme na dvě dílčí tabulky oly12_a a oly12_b:
Obrázky zhruba ukazují, že odhadnutý model si vede dobře i v out-of-sample predikcích. tedy predikcích vypočítaných na jiných datech, než jaké byly použity pro odhad modelu. Vzhledem k tomu, že vzorek byl rozdělen náhodně to asi není žádné velké překvapení.
Diagnostika
Vlivná pozorování
Populárním způsobem, jak najít pozorování, která významně ovlivňují výsledky modelu, je použití leave-one-out strategií. V nich se sleduje efekt vyloučení jednoho pozorování na odhady koeficientů, popřípadě na vyrovnaná pozorování. V R jsou implementovány v influence.measures():
influence.measures(est_model) -> infl_obsinfl_obs %>% class
[1] "infl"
influence.measures() najednou volá celou řadu diagnostických testů – mj. dfbetas() (vliv jednoho pozorování na odhadnuté koeficienty) a dffits() (vliv jednoho pozorování na vyrovnané hodnoty).
Výstupní objekt třídy infl obsahuje dva prvky (matice). .$infmat obsahuje hodnoty jednotlivých statistik a .$is.inf rozhodnutí (o podezření), zda se jedná o vlivné pozorování.
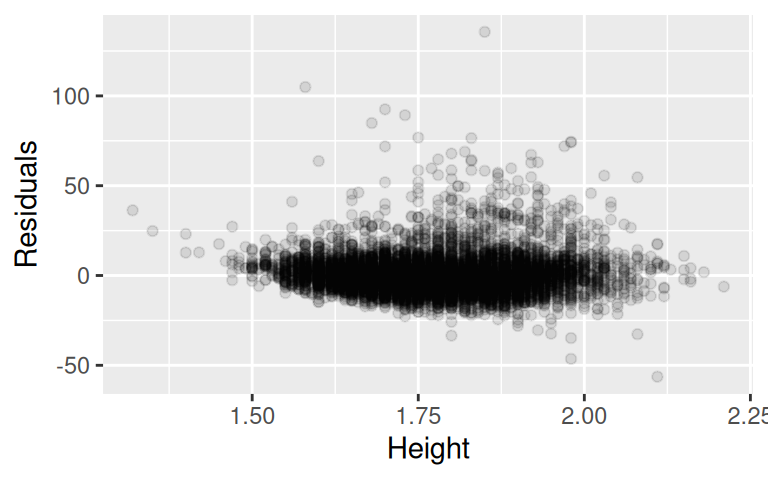
Hodnoty, u kterých se predikce velmi odlišuje od pozorovaných hodnot jsou podle statistiky DFFIT jsou navrženy jako vlivné.
Tyto výsledky naznačují, že se v datech může dít něco zvláštního, nebo že nemáme k dispozici dostatečný počet pozorování z určité části prostoru – v tomto případě například u sportovců s vyšší hmotností.
Normalita reziduí
Prvním způsobem, jak ověřit normalitu reziduí je pohledem na jejich rozdělení. Pomoci může například Q-Q plot, který porovnává kvantily normálního rozdělení a standardizovaných reziduí. V případě, že je rozdělení reziduí normální, by pozorování měla ležet na ose kvadrantu:
Ani jeden okometrický test pro normalitu příliš nehovoří. Nicméně je potřeba nepodlehnout zdání. R poskytuje baterii statistických testů.
Například můžeme zkusit otestovat normalitu pomocí Kolmogorov-Smirnovova testu:
residuals(est_model) %>%ks.test(., 'pnorm') -> ks
Warning in ks.test.default(., "pnorm"): ties should not be present for the
one-sample Kolmogorov-Smirnov test
class(ks)
[1] "ks.test" "htest"
print(ks)
Asymptotic one-sample Kolmogorov-Smirnov test
data: .
D = 0.44131, p-value < 2.2e-16
alternative hypothesis: two-sided
Výstupem ks.test() je objekt typu htest. Tato třída je oblíbená pro výsledky statistických testů. Pro tuto třídu existují metody v balíku broom, např.:
tidy(ks)
# A tibble: 1 × 4
statistic p.value method alternative
<dbl> <dbl> <chr> <chr>
1 0.441 0 Asymptotic one-sample Kolmogorov-Smirnov test two-sided
Nulovou hypotézou K-S testu je normalita, kterou tento test zamítá.
Testy linearity
Z testů linearity je dostupný například Rainbow test, který srovnává kvalitu vyrovnání v modelech odhadnutých “uprostřed” pozorování a na celém vzorku.
V R je Rainbow test dostupný v balíku lmtest ve funkci raintest:
raintest(formula, fraction =0.5, order.by =NULL, center =NULL,data=list())
Parametr fraction udává velikost samplu pro odhad modelu “uprostřed”. V parametru order.by se udává proměnná, podél které se mají pozorování řadit.
Parametr formula může být naplněn i odhadnutým lm modelem. V tom případě není nutné zabývat se parametrem data.
library(lmtest)raintest(model, order.by =~ Height, data = oly12)
Rainbow test
data: model
Rain = 1.1287, df1 = 4519, df2 = 4514, p-value = 2.397e-05
Rain test v tomto případě zamítá nulovou hypotézu. To znamená, že fit na neomezeném vzorku je významně horší, než na podmnožině “prostředních” pozorování. Tento výsledek indikuje možný problém s linearitou.
Heteroskedasticita a odhad robustních chyb
Pokud je porušena homoskedasticita – tzn. konstantní rozptyl náhodné složky – potom není OLS estimátor BLUE (Best linear unbiased estimator), nicméně odhady parametrů jsou stále nevychýlené (unbiased). To bohužel neplatí pro odhady jejich rozptylu – ty naopak vychýlené jsou a v důsledku jsou nedůvěryhodné i testy statistické významnosti parametrů.
V reálném světě je podmínka homoskedasticity porušena velmi často. Jestli tomu tak je můžeme testovat pomocí mnoha testů. Jako příklad mohou sloužit příbuzné testy bptest() z balíku lmtest a ncvTest z balíku car:
lmtest::bptest(est_model)
studentized Breusch-Pagan test
data: est_model
BP = 73.288, df = 4, p-value = 4.585e-15
car::ncvTest(est_model)
Non-constant Variance Score Test
Variance formula: ~ fitted.values
Chisquare = 535.0632, Df = 1, p = < 2.22e-16
Oba testy testují nulovou hypotézu o homoskedasticitě oba ji suverénně zamítají – p-hodnoty obou testů jsou v podstatě nerozlišitelné od nuly.
Odhady směrodatných chyb lze korigovat použitím tzv. HC (heteroskedasticity consistent) estimátorů kovarianční matice. Ty jsou implementovány například v balících car (car::hccm), ale zejména v balíku sandwich.
Balík sandwich obsahuje celou řadu nástrojů pro odhad kovarianční matice pro průřezová i panelová data. Bližší pozornost budeme věnovat dvěma. Základní funkci vcovHC() a také relativně nově implementované funkci pro výpočet klastrovaných robustních chyb vcovCL().
vcovCL(x, cluster =NULL, type =NULL, sandwich =TRUE, fix =FALSE, ...)
Vstupem funkce je odhadnutý model (x). V parametru type se potom specifikuje způsob korekce heteroskedasticity (viz ?vcovHC()). V případě funkce vcovCL() je navíc nutné specifikovat proměnnou, nebo v případě více dimenzí proměnné, podle kterých se mají standardní chyby klastrovat. Klastrování se typicky používá v situaci, kdy určitá pozorování na sobě nejsou nezávislá. Klasický příklad je prospěch dětí z jedné třídy. Podstata dat sportovců naznačuje, že i v tomto případě je klastrování namístě. Jako specifické skupiny můžeme chápat sportovce věnující se jedné disciplině. Po vcovCL() tedy bude chtít spočítat kovarianční maticí klastrovanou podél proměnné Sport. Tu musíme dodat jako samostatný vektor. V objektu totiž není zahrnuta:
Výsledkem je odhad kovarianční matice. Zpravidla nás ovšem více zajímá odhad významnosti parametrů – provedení statistických testů s použitím robustní kovarianční matice jako vstupu. Pro tento účel použijeme funkci coeftest() z balíku lmtest:
coeftest(x, vcov. =NULL, df =NULL, ...)
Prvním vstupem funkce coeftest() je odhadnutý model. (Funkce má implementovány metody pro modely třídy lm a glm.) Druhým parametrem je kovarianční matice nebo funkce, která se má použít pro její výpočet. Pokud je tento parametr ponechán prázdný, potom coeftest() použije nekorigovanou kovarianční matici:
library(lmtest)coeftest(est_model)
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.0601e+02 2.3853e+00 -44.4438 < 2.2e-16 ***
Height 9.4635e+01 1.1413e+00 82.9183 < 2.2e-16 ***
Age 4.0966e-01 1.0960e-01 3.7378 0.0001868 ***
I(Age^2) -4.0944e-03 1.8193e-03 -2.2505 0.0244416 *
SexM 5.5916e+00 2.5603e-01 21.8397 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Zadaní jména funkce jako parametru vcov. je vhodné tehdy, pokud nepotřebujete provádět žádné další nastavení parametrů výpočtu kovarianční matice:
coeftest(est_model, vcov. = vcovHC)
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.0601e+02 2.4526e+00 -43.2250 < 2.2e-16 ***
Height 9.4635e+01 1.2120e+00 78.0841 < 2.2e-16 ***
Age 4.0966e-01 9.2268e-02 4.4398 9.109e-06 ***
I(Age^2) -4.0944e-03 1.5164e-03 -2.7002 0.006944 **
SexM 5.5916e+00 2.4404e-01 22.9123 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
V případě klastrovaných chyb však potřebuje takové nastavení provést – minimálně potřebujeme zadat vektor podél kterého se má klastrovat. Do vcov. v tomto případě potřebujeme zadat celou kovarianční matici – tedy výstup funkce vcovCL:
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.0601e+02 1.2031e+01 -8.8116 < 2.2e-16 ***
Height 9.4635e+01 7.6075e+00 12.4396 < 2.2e-16 ***
Age 4.0966e-01 2.8184e-01 1.4535 0.1461
I(Age^2) -4.0944e-03 5.0661e-03 -0.8082 0.4190
SexM 5.5916e+00 9.8945e-01 5.6512 1.642e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Klastrovat lze podél více proměnných. V tomto případě je potřeba do parametru cluster vložit list vektorů nebo data.frame. Nyní zkusíme cvičně klastrovat nejen podle sportovního odvětví, ale i podle pohlaví:
V mnoha případech je užitečné se na diagnostiku podívat prostřednictvím vizualizací. Tuto možnost nabízí například funkce plot(), která má pro tento účel implementovanou metodu. Její fungování můžete vyzkoušet zadáním plot(est_model). Tento postup logicky pracuje se základní grafikou. Existují však i řešení, které podobně uživatelsky přítulně vykreslí diagnostické grafy s pomocí ggplot2. Jedním z nich je funkce ggplot2::autoplot(), která využívá služeb balíku ggfortify:
library(ggfortify)autoplot(est_model)
Warning: `fortify(<lm>)` was deprecated in ggplot2 4.0.0.
ℹ Please use `broom::augment(<lm>)` instead.
ℹ The deprecated feature was likely used in the ggfortify package.
Please report the issue at <https://github.com/sinhrks/ggfortify/issues>.
Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
ℹ Please use tidy evaluation idioms with `aes()`.
ℹ See also `vignette("ggplot2-in-packages")` for more information.
ℹ The deprecated feature was likely used in the ggfortify package.
Please report the issue at <https://github.com/sinhrks/ggfortify/issues>.
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
ℹ The deprecated feature was likely used in the ggfortify package.
Please report the issue at <https://github.com/sinhrks/ggfortify/issues>.