library(readr)10 Načítání a ukládání dat ze souborů
Práce s daty začíná vždy jejich načtením a často končí jejich uložením. V této kapitole se naučíte:
- co jsou to textové delimitované tabulární soubory, jak je načíst a uložit
- jak pracovat s nedelimitovanými textovými tabulárními soubory
- jak pracovat s komprimovanými soubory textovými a soubory na webu
- jak uložit a načíst data do nativního R-kového binárního souboru
- jak pracovat s daty uloženými v balících
- jak načíst data uložená v souboru MS Excel
- jak pracovat s daty ve formátu statistických programů SPSS, SAS a Stata
- jak zkontrolovat integritu načtených dat
10.1 Textové tabulární delimitované soubory
Základní způsob výměny dat jsou textové tabulární delimitované formáty, kde jednotlivé řádky odpovídají pozorováním a kde jsou sloupce (proměnné) odděleny nějakým jasně definovaným znakem, např. mezerou, tabelátorem, čárkou, středníkem nebo dvojtečkou. Velká výhoda těchto formátů je, že je možné je načíst téměř do každého softwaru, který pracuje s daty a stejně tak je z něj i vypsat. Zároveň jsou data “čitelná lidmi” a pokud se něco pokazí, je často možné data nějak zachránit. Nevýhodou je, že tyto formáty mohou obsahovat pouze tabulární data (tabulky), jednoduché datové typy (tj. ne složitější objekty, jako jsou např. odhady modelů), nemohou obsahovat metadata (např. atributy), jejich načítání může trvat dlouho (pokud jsou data velká) a že data v těchto formátech na disku zabírají hodně místa (pokud nejsou komprimovaná).
Příkladem dat v textovém tabulárním formátu je např. soubor “bmi_data.csv”. Na disku vypadá takto:
id,height,weight,bmi
1,153,55,23.4952368747
2,207,97,22.6376344839
3,173,83,27.7322997761
4,181,92,28.0821708739
5,164,112,41.6418798334Zde se podíváme na to, jak data v textovém tabulárním formátu načíst a uložit pomocí funkcí z balíku readr. Oproti podobným funkcím ze základního R, tyto funkce načítají data rychleji, umožňují přesněji určit, jak se mají data načíst a neprovádí některé nepříjemné úpravy.1 Před použitím těchto funkcí musíme nejdříve načíst balík readr:
Načítání dat
Všechny funkce z balíku readr, které sloužící k načítání dat, jsou pojmenované read_XXX(), kde XXX je jméno načítaného formátu. Data ve formátu CSV tedy načítá funkce read_csv(). (Pozor! Funkce ze základního R určené k načtení těchto dat jsou pojmenované téměř stejně, jen místo podtržítka je jméno formátu oddělené tečkou. Obdobou funkce read_csv() je funkce read.csv() ze základního balíku. Přestože se funkce jmenují podobně, mají výrazně odlišný interface i chování.) Všechny funkce read_XXX() z balíku readr vracejí tabulku třídy tibble.
Základní funkcí k načtení textových delimitovaných tabulárních dat je funkce read_delim(). Při jejím použití je nezbytné zadat pouze jediný parametr: jméno načítaného souboru včetně cesty. Při takovém použití funkce odhadne, který znak odděluje jednotlivé sloupce (proměnné) v datech. Bezpečnější je však tento oddělovací znak zadat explicitně pomocí parametru delim. V našem případě nastavíme delim = ",":
bmi_data <- read_delim("data/reading_and_writing/bmi_data.csv", delim = ",")Rows: 5 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): id, height, weight, bmi
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.bmi_data# A tibble: 5 × 4
id height weight bmi
<dbl> <dbl> <dbl> <dbl>
1 1 153 55 23.5
2 2 207 97 22.6
3 3 173 83 27.7
4 4 181 92 28.1
5 5 164 112 41.6Textová tabulární data mohou mít jednotlivé proměnné oddělené různě. Existují však tři nejobvyklejší varianty, pro které má readr speciální varianty funkce read_delim():
read_csv()načítá klasický americký standard CSV, kde jsou jednotlivé proměnné oddělené čárkami a celou a desetinnou část čísla odděluje desetinná tečka,read_csv2()načítá “evropskou” variantu CSV, kde jsou jednotlivé proměnné oddělené středníky a desetinná místa v číslech odděluje čárka aread_tsv()načítá variantu formátu, kde jsou proměnné oddělené tabelátorem.
V těchto funkcích není potřeba nastavovat parametr delim; většinu ostatních parametrů mají tyto funkce stejné jako funkce read_delim().
Protože dataset “bmi_data.csv” splňuje klasický formát CSV, můžeme jej pohodlněji načíst i pomocí funkce read_csv():
bmi_data <- read_csv("data/reading_and_writing/bmi_data.csv")Rows: 5 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): id, height, weight, bmi
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Všechny funkce read_XXX() berou první řádek datového souboru implicitně jako jména proměnných. Pokud soubor jména proměnných neobsahuje, je to třeba funkcím říct pomocí parametru col_names. Ten může nabývat jedné ze tří hodnot. Pokud má hodnotu TRUE, pak první řádek souboru chápe jako jména proměnných. Pokud má hodnotu FALSE, pak se předpokládá, že první řádek souboru jména proměnných neobsahuje; z řádku se načtou data a funkce sama jednotlivé proměnné pojmenuje X1, X2 atd. Třetí možností je zadat jména proměnných ručně. V tomto případě musí být parametr col_names zadán jako vektor řetězců, který obsahuje jména jednotlivých proměnných. Na rozdíl od funkcí ze základního R, funkce z balíku readr jména proměnných nijak nemodifikují. V důsledku toho nemusejí být jména proměnných platnými názvy proměnných v R. To je však vždy možné opravit dvěma různými způsoby: Jednou možností je dodatečně změnit jména ručně pomocí funkcí names() nebo setNames(). Druhou možností je pomocí parametru name_repair nastavit funkci, která jména sloupců opraví automaticky. Jednou z možností je zde použít funkci make_clean_names() z balíku janitor. Tato funkce odstraní divné znaky, písmena s háčky, čárkami a jinými akcenty zbaví těchto akcentů, mezery nahradí podtržítky apod. Volání funkce read_csv() pak bude vypadat takto:
bmi_data <- read_csv(
"data/reading_and_writing/bmi_data.csv",
name_repair = janitor::make_clean_names
)Ukážeme si to na příkladu. Soubor “bmi_data_headless.csv” obsahuje stejná data jako soubor “bmi_data.csv”, na prvním řádku však nejsou uvedena jména sloupců, ale dataset začíná přímo daty. Pokud bychom dataset načetli stejně jako výše, funkce read_csv() by první řádek použila k pojmenování proměnných (jména sloupců by navíc v našem případě byla syntakticky nepřípustná, takže bychom je museli používat spolu se zpětnými apostrofy):
read_csv("data/reading_and_writing/bmi_data_headless.csv")Rows: 4 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): 1, 153, 55, 23.4952368747
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# A tibble: 4 × 4
`1` `153` `55` `23.4952368747`
<dbl> <dbl> <dbl> <dbl>
1 2 207 97 22.6
2 3 173 83 27.7
3 4 181 92 28.1
4 5 164 112 41.6Tomu můžeme zabránit tak, že nastavíme parametr col_names = FALSE, takže se první řádek souboru považuje za data:
read_csv(
"data/reading_and_writing/bmi_data_headless.csv",
col_names = FALSE
)Rows: 5 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): X1, X2, X3, X4
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# A tibble: 5 × 4
X1 X2 X3 X4
<dbl> <dbl> <dbl> <dbl>
1 1 153 55 23.5
2 2 207 97 22.6
3 3 173 83 27.7
4 4 181 92 28.1
5 5 164 112 41.6V takovém případě se sloupce tabulky pojmenují X1, X2 atd. Alternativně můžeme pomocí parametru col_names přímo zadat jména jednotlivých sloupců, např. jako col_names = c("id", "výška", "váha", "bmi") (první řádek souboru se bude opět považovat za data):
read_csv(
"data/reading_and_writing/bmi_data_headless.csv",
col_names = c("id", "výška", "váha", "bmi")
)Rows: 5 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): id, výška, váha, bmi
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# A tibble: 5 × 4
id výška váha bmi
<dbl> <dbl> <dbl> <dbl>
1 1 153 55 23.5
2 2 207 97 22.6
3 3 173 83 27.7
4 4 181 92 28.1
5 5 164 112 41.6Některé datové soubory obsahují v prvních řádcích nějaké balastní informace, např. údaje o pořízení dat, copyrightu, parametrech simulace apod. Tyto řádky je možné přeskočit pomocí parametru skip: např. skip = 5 znamená, že se má přeskočit prvních pět řádků. Podobně některé soubory obsahují mezi skutečnými daty komentáře. Pokud jsou tyto komentáře uvozeny nějakým jasným znakem, můžeme je při načítání dat přeskočit pomocí parametru comment: např. comment = "#" znamená, že se přeskočí všechny řádky, které začínají “křížkem”.
Opět si to ukážeme na příkladu. Soubor “bmi_data_comments.csv” opět obsahuje stejná data jako “bmi_data.csv”, na prvních dvou řádcích však obsahuje nějaké informace o experimentu. Na disku vypadá soubor takto:
Experiment no. 747.
Top secret
id,height,weight,bmi
1,153,55,23.4952368747
2,207,97,22.6376344839
3,173,83,27.7322997761
4,181,92,28.0821708739
5,164,112,41.6418798334Tento soubor musíme načíst s pomocí parametru skip; v opačném případě se věci opravdu pokazí (vyzkoušejte si to):
read_csv("data/reading_and_writing/bmi_data_comments.csv", skip = 2)Rows: 5 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): id, height, weight, bmi
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# A tibble: 5 × 4
id height weight bmi
<dbl> <dbl> <dbl> <dbl>
1 1 153 55 23.5
2 2 207 97 22.6
3 3 173 83 27.7
4 4 181 92 28.1
5 5 164 112 41.6Soubor “bmi_data_comments2.csv” obsahuje opět stejná data; nyní jsou však dvě množiny pozorování nadepsány komentáři a jeden řádek má také vlastní komentář:
id,height,weight,bmi
# the first set of observations
1,153,55,23.4952368747
2,207,97,22.6376344839
3,173,83,27.7322997761 # suspicious
# the second set of observations
4,181,92,28.0821708739
5,164,112,41.6418798334V tomto případě musíme zadat znak, kterým začínají komentáře, pomocí parametru comment. Funkce read_XXX() pak ignorují vše od tohoto znaku do konce řádku:
read_csv("data/reading_and_writing/bmi_data_comments2.csv", comment = "#")Rows: 5 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): id, height, weight, bmi
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# A tibble: 5 × 4
id height weight bmi
<dbl> <dbl> <dbl> <dbl>
1 1 153 55 23.5
2 2 207 97 22.6
3 3 173 83 27.7
4 4 181 92 28.1
5 5 164 112 41.6Různé datové soubory kódují chybějící hodnoty různě. Standardně funkce read_XXX() očekávají, že chybějící hodnota je buď prázdná, nebo obsahuje řetězec “NA”. To je však možné změnit parametrem na. Do něj uložíte vektor všech hodnot, které má funkce read_XXX() považovat za NA. Pokud např. váš datový soubor kóduje chybějící hodnoty pomocí tečky, nastavíte na = ".". Pokud navíc může být zadaná chybějící hodnota i jako prázdný řetězec nebo řetězec “NA”, zadáte na = c("", ".", "NA"). (Funkce read_XXX() při načítání jednotlivých hodnot implicitně odstraní všechny úvodní a koncové mezery, takže našemu “tečkovému” pravidlu vyhoví jak řetězce “.”, tak i “ . ”. Toto chování můžete změnit parametrem trim_ws.) Následující kód ukazuje příklad:
read_csv("data/reading_and_writing/bmi_data_na.csv", na = c("", ".", "NA"))Rows: 5 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): id, height, weight, bmi
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# A tibble: 5 × 4
id height weight bmi
<dbl> <dbl> <dbl> <dbl>
1 1 153 55 23.5
2 2 207 97 22.6
3 3 NA 83 27.7
4 4 181 NA 28.1
5 5 164 112 41.6Jak jste si asi všimli, funkce read_XXX() při načítání dat samy odhadnou, jaká data obsahují jednotlivé proměnné, a převedou je na daný datový typ. (Výsledná tabulka třídy tibble tyto typy vypisuje pod jmény proměnných.) Informace o tom, jaký typ funkce zvolila pro který sloupec, se vypíše při načítání: informace má tvar “dbl (4): id, height, weight, bmi” apod. V našem případě se všechny proměnné převedly na reálná čísla. Funkce read_XXX() odhadují typ proměnné na základě prvních 1 000 načtených řádků (toto číslo je možné změnit pomocí parametru guess_max). Nechat si datový typ odhadnout, je pohodlné, ale nepříliš bezpečné. Mnohem rozumnější je zadat datový typ jednotlivých sloupců ručně pomocí parametru col_types. Ten je možné zadat třemi způsoby. Zaprvé, hodnota NULL indikuje, že se typy proměnných mají odhadnout. Zadruhé, datové typy jednotlivých sloupců je možné zadat plnými jmény ve funkci cols(). A zatřetí, tato jména můžeme zkrátit do jednopísmenných zkratek zadaných v jednom řetězci. Seznam typů sloupců a jejich zkratek uvádí tabulka 10.1. Rozdíl mezi funkcemi col_double() a col_number() spočívá v tom, že col_number() umožňuje mít před a za vlastním číslem nějaké nečíselné znaky, které zahodí. To se hodí např. při načítání peněžních údajů, kde col_number() zvládne převést na číslo i řetězce jako $15.30 nebo 753 Kč.
| funkce | význam | zkratka | parametry |
|---|---|---|---|
col_logical() |
logická proměnná | “l” | |
col_integer() |
striktní celé číslo | “i” | |
col_double() |
striktní reálné číslo | “d” | |
col_number() |
flexibilní číslo | “n” | |
col_character() |
řetězec | “c” | |
col_date() |
datum (jen den bez hodin) | “D” | format |
col_datetime() |
datum (den i hodina) | “T” | format |
col_time() |
čas (jen hodiny, minuty a sekundy) | “t” | format |
col_factor() |
faktor | “f” | levels, ordered, include_na |
col_guess() |
typ odhadne R | “?” | |
col_skip() |
proměnná se přeskočí a nenačte | “_” nebo “-” |
Řekněme, že proměnnou id chceme mít uloženou jako typ integer, zatímco ostatní hodnoty jako reálná čísla. Toho můžeme dosáhnout ručně takto (v tomto případě R nevypíše informaci o sloupcích):
bmi_data <- read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = cols(
id = col_integer(),
height = col_double(),
weight = col_double(),
bmi = col_double()
)
)nebo stručněji takto:
bmi_data <- read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = "iddd"
)Specifikací sloupců můžeme samozřejmě změnit i typ sloupců. Někdy např. můžeme chtít načíst všechny proměnné jako řetězce, a pak si je zkonvertovat sami. To můžeme udělat třemi způsoby: 1) sloupce můžeme nastavit pomocí plného volání funkcí col_types = cols(id = col_character(), height = col_character(), weight = col_character(), bmi = col_character()), 2) je můžeme nastavit pomocí zkratkových písmen jako col_types = "cccc" nebo 3) nastavíme implicitní typ sloupce pomocí speciálního parametru .default buď plným voláním funkce col_types = cols(.default = col_character()) nebo pomocí zkratkového písmene:
read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = cols(.default = "c")
)# A tibble: 5 × 4
id height weight bmi
<chr> <chr> <chr> <chr>
1 1 153 55 23.4952368747
2 2 207 97 22.6376344839
3 3 173 83 27.7322997761
4 4 181 92 28.0821708739
5 5 164 112 41.6418798334Nejjednodušší způsob, jak explicitně zadat datové typy sloupců tabulky, je nechat funkci read_XXX() odhadnout datový typ sloupců, a pak specifikaci cols() zkopírovat a případně upravit. Po vlastním načtení je možné specifikaci získat i pomocí funkce spec(), jejímž jediným argumentem je načtená tabulka. Specifikaci je možné zjednodušit pomocí funkce cols_condense(), která nejčastěji používaný datový typ shrne do parametru .default:
cols_condense(spec(bmi_data))cols(
.default = col_double(),
id = col_integer()
)Pokud bychom chtěli vypsat rychlý přehled o tom, v jakém formátu se data načetla, můžeme na výsledek funkce spec() spustit funkci summary(). Výsledek bude ve stejném formátu, v jakém tuto specifikaci vypíší funkce read_XXX():
summary(spec(bmi_data))── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (3): height, weight, bmi
int (1): idNěkteré funkce col_XXX umožňují zadat parametry. Funkce pro načítání data a času umožňují zadat formát, ve kterém je datum nebo čas uložen. Funkce pro načítání faktorů umožňují zadat platné úrovně faktoru, to, zda je faktor ordinální, a to, zda má být hodnota NA součástí úrovní faktoru. Úplný seznam parametrů uvádí tabulka 10.1. Pokud bychom např. chtěli načíst proměnnou id jako faktor se třemi úrovněmi (“1”, “2” a “3”), můžeme to udělat takto (funkce read_XXX() nikdy nic nepřevádí na faktory samy od sebe – pokud chcete proměnnou převést na faktor, musíte o to požádat):
bmi_data <- read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = cols(
id = col_factor(levels = as.character(1:3)),
height = col_integer(),
weight = col_integer(),
bmi = col_double()
)
)Warning: One or more parsing issues, call `problems()` on your data frame for details,
e.g.:
dat <- vroom(...)
problems(dat)Funkce vypíše varování, protože proměnná id obsahuje i jiné než povolené úrovně, a nepovolené úrovně nahradí hodnotami NA. (Pokud bychom chtěli nechat funkci read_XXX() odhadnout úrovně faktoru z dat, museli bychom zadat parametr levels = NULL.)
Funkcím read_XXX() je možné sdělit i to, které proměnné z tabulky vyloučit. K tomu slouží funkce col_skip(). Řekněme, že bychom chtěli náši tabulku anonymizovat tím, že z dat odstraníme identifikátory id. Toho můžeme dosáhnout např. takto:
bmi_data <- read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = cols(
id = col_skip(),
height = col_integer(),
weight = col_integer(),
bmi = col_double()
)
)
bmi_data# A tibble: 5 × 3
height weight bmi
<int> <int> <dbl>
1 153 55 23.5
2 207 97 22.6
3 173 83 27.7
4 181 92 28.1
5 164 112 41.6Pokud bychom chtěli načíst jen některé proměnné, stačí nahradit funkci cols() funkcí cols_only() a v ní uvést pouze proměnné, které se mají načíst. Následující kód načte pouze proměnné height a bmi:
bmi_data <- read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = cols_only(
height = col_integer(),
bmi = col_double()
)
)
bmi_data# A tibble: 5 × 2
height bmi
<int> <dbl>
1 153 23.5
2 207 22.6
3 173 27.7
4 181 28.1
5 164 41.6K výběru sloupců, které se mají načíst, je možné použít i sofistikovanější parametr col_select, která používá stejnou syntaxi jako funkce select() z balíku dplyr, viz oddíl 13.1.2. Vybrané sloupce je možné vyjmenovat (bez uvozovek) nebo zavolat pořadím sloupce:
read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = "iddd",
col_select = c(height, bmi)
)# A tibble: 5 × 2
height bmi
<dbl> <dbl>
1 153 23.5
2 207 22.6
3 173 27.7
4 181 28.1
5 164 41.6read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = "iddd",
col_select = c(2, 4)
)# A tibble: 5 × 2
height bmi
<dbl> <dbl>
1 153 23.5
2 207 22.6
3 173 27.7
4 181 28.1
5 164 41.6Pomocí symbolu : je možné vybrat souvisle sloupce od vybraného počátečního po vybraný koncový:
read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = "iddd",
col_select = height:bmi
)# A tibble: 5 × 3
height weight bmi
<dbl> <dbl> <dbl>
1 153 55 23.5
2 207 97 22.6
3 173 83 27.7
4 181 92 28.1
5 164 112 41.6Pomocí symbolu - je možné sloupce vypouštět:
read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = "iddd",
col_select = -c(height, bmi)
)# A tibble: 5 × 2
id weight
<int> <dbl>
1 1 55
2 2 97
3 3 83
4 4 92
5 5 112Speciální funkce starts_with(), ends_with(), contains(), matches() a num_range() umožňují vybírat sloupce podle části jejich názvu; funkce everything() umožní vybrat všechny zbývající sloupce. Sloupce, jejichž název končí na “ht” je např. možné načíst takto:
read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = "iddd",
col_select = ends_with("ht")
)# A tibble: 5 × 2
height weight
<dbl> <dbl>
1 153 55
2 207 97
3 173 83
4 181 92
5 164 112Tyto možnosti je samozřejmě možné i kombinovat:
read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = "iddd",
col_select = c(id, ends_with("ht"))
)# A tibble: 5 × 3
id height weight
<int> <dbl> <dbl>
1 1 153 55
2 2 207 97
3 3 173 83
4 4 181 92
5 5 164 112Parametr col_select umožňuje sloupce i přejmenovat. V tom případě musí parametr obsahovat pojmenovaný seznam:
read_csv(
"data/reading_and_writing/bmi_data.csv",
col_types = "iddd",
col_select = list(id, výška = height, váha = weight, everything())
)# A tibble: 5 × 4
id výška váha bmi
<int> <dbl> <dbl> <dbl>
1 1 153 55 23.5
2 2 207 97 22.6
3 3 173 83 27.7
4 4 181 92 28.1
5 5 164 112 41.6Jak jsme viděli výše, pokud se při načítání jednotlivých sloupců tabulky něco pokazí, funkce read_XXX() o tom vypíší varování a příslušnou “buňku” tabulky doplní hodnotou NA. K tomu může dojít z různých důvodů: Datový typ, který jste zadali (nebo který R odhadlo na základě prvních 1 000 řádků) není dost obecný pro všechny řádky tabulky. První řádky např. obsahují jen celá čísla, zatímco pozdější řádky i reálná čísla. Faktor obsahuje i jiné hodnoty, než zadané platné úrovně atd. Pokud je varování hodně, zobrazí se jen několik prvních varování. Všechna varování je možné vypsat funkcí problems(), jejímž jediným argumentem je načtená tabulka.
Většinou je moudré ladit zadání typů sloupců ve specifikaci cols() tak dlouho, až R nevypisuje žádná varování. To je užitečné zejména v případě, že načítáte různé datové soubory se stejnou strukturou. Když se potom u některého souboru objeví varování, znamená to, že se v datech něco změnilo. Pokud chcete být opravdu důkladně varováni, že k tomu došlo, můžete použít funkci stop_for_problems(). Jejím jediným argumentem je načtená tabulka. Pokud při jeho načtení došlo k nějakým varováním, funkce stop_for_problems() zastaví běh skriptu.
Tabulární datové soubory jsou obyčejné textové soubory bez speciálního formátování. Proto celá řada prvků těchto souborů není standardizovaná. Jednotlivé datové soubory se mohou lišit kódováním, znakem použitým pro oddělení celých a desetinných čísel, znakem použitým pro oddělení tisíců, jmény měsíců a dnů v týdnu apod. Balík readr implicitně používá americkou konvenci: kódování je UTF-8, desetinná místa odděluje tečka, tisíce čárka a veškerá jména jsou anglická. Toto chování můžete změnit pomocí parametru locale, do kterého vložíte objekt vytvořený funkcí locale(). Její základní parametry uvádí tabulka 10.2.
| parametr | význam | impl. hodnota |
|---|---|---|
date_names |
řetězec pro jména datumů (česká “cs”, slovenská “sk”) | “en” |
date_format |
formát data | “%AD” |
time_format |
formát času | “%AT” |
decimal_mark |
znak pro oddělení desetinných míst | “.” |
grouping_mark |
znak pro oddělení tisíců | “,” |
tz |
časová zóna | “UTC” |
encoding |
kódování souboru | “UTF-8” |
asciify |
jestli soubor odstranil diakritiku ze jmen datumů | FALSE |
Nastavení ve funkci locale si můžete vyzkoušet tak, že je necháte vypsat do konzoly. Typické české nastavení data vytvořená z LibreOffice na Linuxu s formátem data typu 31. 12. 2017 by vypadalo takto:
locale("cs",
date_format = "%d.%*%m.%*%Y",
decimal_mark = ",", grouping_mark = ".",
tz = "Europe/Prague")<locale>
Numbers: 123.456,78
Formats: %d.%*%m.%*%Y / %AT
Timezone: Europe/Prague
Encoding: UTF-8
<date_names>
Days: neděle (ne), pondělí (po), úterý (út), středa (st), čtvrtek (čt), pátek
(pá), sobota (so)
Months: ledna (led), února (úno), března (bře), dubna (dub), května (kvě),
června (čvn), července (čvc), srpna (srp), září (zář), října
(říj), listopadu (lis), prosince (pro)
AM/PM: dopoledne/odpoledneSložitější nastavení locale, např. jak nastavit jména dnů a měsíců v nepodporovaném jazyce nebo jak zjistit časovou zónu, najdete v příslušné vinětě balíku readr.
Největší oříšek je v našich končinách zjistit, jaké kódování má daný soubor. K tomu může pomoci funkce guess_encoding(), jejímž jediným parametrem je jméno souboru, jehož kódování chceme odhadnout. Funkce vypíše seznam několika kódování a u nich pravděpodobnost, kterou tomuto kódování přikládá. Pokud funkci vyzkoušíme na našem testovacím souboru, dostaneme následující výsledek:
guess_encoding("data/reading_and_writing/bmi_data.csv")# A tibble: 1 × 2
encoding confidence
<chr> <dbl>
1 ASCII 1Protože náš soubor neobsahuje žádnou diakritiku, je si funkce guess_encoding() zcela jistá, že se jedná o ASCII soubor. (Protože ASCII je podmnožinou UTF-8, nemusíme kódování explicitně deklarovat.)
Načítání velkých souborů
Načítání velkých souborů funguje stejně jako načítání malých souborů – se dvěma specifiky: trvá déle a zabírá více operační paměti počítače. Balík readr zde pomáhá dvěma způsoby. Předně je možné načítat data do paměti počítače “lenivě” (tzv. lazy load). To znamená, že když načtete datový soubor, funkce read_XXX() ve skutečnosti jen projde strukturu datového souboru (zjistí počet řádků a sloupců, typy sloupců apod.), ale žádná data ve skutečnosti do paměti počítače nenačte. To udělá teprve ve chvíli, kdy o tato data skutečně požádáte, tj. pokusíte si je vypsat, něco s nimi spočítat apod. Přitom se načtou pouze ta data, o která požádáte. To např. znamená, že když po načtení souboru vypíšete jen několik prvních nebo posledních řádků pomocí funkce head() nebo tail(), načtou se pouze tyto řádky. Pokud budete pracovat jen s vybranými sloupci, načtou se jen tyto sloupce. Líné načítání můžete zapnout pomocí parametru lazy = TRUE.
Líné načítání dat může někdy způsobit určité problémy. Načítaný soubor je např. otevřený do té doby, dokud není do paměti načtený celý. V Linuxu a macOs to zpravidla nepůsobí žádné problémy, ve Windows však není s otevřeným souborem možné jinak pracovat. Líní načítání se tak hodní zapnout jen v případě, kdy víte, co děláte, a jde vám o efektivitu načítání. Víc detailů najdete na stránce https://www.tidyverse.org/blog/2021/11/readr-2-1-0-lazy/.
Zadruhé, R dokáže pracovat pouze s proměnnými, které má v operační paměti. Pokud se pokusíte načíst data, která se do paměti počítače nevejdou, R spadne. Pokud tedy máte opravdu hodně velký datový soubor, je užitečné dopředu zjistit, kolik paměti zabere. Objem dat v paměti můžete přibližně odhadnout následujícím způsobem:
- zjistíte, kolik řádků má vaše tabulka (v Linuxu to můžete udělat pomocí prográmku
wc), - načtete prvních 1 000 řádků tabulky (počet řádků omezíte pomocí parametru
n_max); přitom odladíte datové typy jednotlivých sloupců, - zjistíte, kolik paměti tabulka zabírá pomocí funkce
object.size()a - vypočítáte, kolik paměti zabere celý datový soubor: vydělíte velikost vzorku dat tisícem a vynásobíte ji počtem řádků souboru.
Balík readr umožňuje do jisté míry omezení proměnných na operační paměť počítače obejít. K tomu slouží speciální funkce read_XXX_chunked() (ekvivalentem funkce read_delim() je funkce read_delim_chunked()). Tyto funkce čtou datový soubor po kusech. Nad každým kusem provedou nějakou agregační operaci (např. vyberou jen řádky, které splňují určitou podmínku, spočítají nějaké agregátní statistiky apod.) a do paměti ukládají jen výsledky těchto operací. Na detaily použití těchto funkcí se podívejte do jejich dokumentace.
Naštěstí pro vás, valná většina dat, se kterou budete v blízké budoucnosti pracovat, bude nejspíše tak malá, že nic z těchto triků nebudete muset používat. Například tabulka s milionem řádků a 20 sloupci, které všechny obsahují reálná čísla bude v paměti počítač zabírat 1 000 000 \(\times\) 20 \(\times\) 8 \(=\) 160 000 000 bytů, tj. asi jen 153 MB.
Ukládání dat do textových tabulárních delimitovaných souborů
K zapsání dat do tabulárních formátů slouží funkce write_delim(), write_csv(), write_csv2(), write_excel_csv(), write_excel_csv2() a write_tsv(). Prvním parametrem všech těchto funkcí je vždy tabulka, který se má zapsat na disk, druhým je cesta, kam se mají data zapsat. Dále je možné nastavit pomocí parametru na znak pro uložení hodnoty NA a určit, zda se mají data připsat na konec existujícího souboru. Funkce read_delim() umožňuje navíc nastavit pomocí parametru delim znak, který bude oddělovat jednotlivé sloupce tabulky. Funkce write_excel_csv() přidá do souboru kromě běžného CSV i znak, podle kterého MS Excel pozná, že soubor je v kódování UTF-8. Další parametry těchto funkcí najdete v jejich dokumentaci.
Tyto funkce bohužel neumožňují nastavit locale, takže výsledkem je vždy soubor v kódování UTF-8 s desetinnými místy oddělenými pomocí tečky, tisící oddělenými pomocí čárky atd. Pokud potřebujete něco jiného. podívejte se do dokumentace na odpovídající funkce ze základního R (tj. např. funkci write.csv()).
Spojení (connections)
Když R čte nebo zapisuje data, nepracuje přímo se soubory, ale se “spojeními” (connections). Spojení zobecňuje myšlenku souboru – spojení může být lokální soubor, soubor komprimovaný algoritmem gzip, bzip2 apod., URL a další.
Funkce read_XXX() vytvářejí spojení pro čtení dat automaticky. To znamená, že jméno souboru může obsahovat jak lokální soubor, tak URL. Internetový odkaz funkce pozná podle úvodního “http://”, “https://”, “ftp://” nebo “ftps://”. V takovém případě vzdálený soubor automaticky stáhne. Funkce umí číst i některý typy komprimovaných souborů. Ty pozná podle koncovky “.gz”, “.bz2”, .”xz” nebo “.zip”. Takový soubor funkce automaticky dekomprimuje.
Předpokládejme, že náš datový soubor je pro úsporu místa na disku komprimovaný pomocí programu gzip. Pak data načteme jednoduše takto:
bmi_data <- read_csv("data/reading_and_writing/bmi_data.csv.gz",
col_types = "iiid")
bmi_data# A tibble: 5 × 4
id height weight bmi
<int> <int> <int> <dbl>
1 1 153 55 23.5
2 2 207 97 22.6
3 3 173 83 27.7
4 4 181 92 28.1
5 5 164 112 41.6Podobně je možné načíst i data z internetu, stačí nahradit jméno souboru jeho URL. Řekněme, že v proměnné estat_gdp_adr máte uloženou cestu k jedné z datových tabulek Eurostatu (zde jedna z tabulek s hodnotami GDP: https://ec.europa.eu/eurostat/estat-navtree-portlet-prod/BulkDownloadListing?file=data/namq_10_gdp.tsv.gz). Pak můžete tato data načít do R takto:
gdp <- read_tsv(estat_gdp_adr, show_col_types = FALSE)Na rozdíl od funkcí ze základního R umí funkce write_XXX() i přímo zapisovat do komprimovaných souborů bez toho, aby bylo potřeba spojení explicitně deklarovat (např. pomocí funkce gzfile()). Stačí uvést jméno souboru ukončené odpovídající koncovkou. Pokud tedy chceme uložit naši tabulku do komprimovaného souboru, můžeme to provést např. takto:
write_csv(bmi_data, "moje_data.csv.gz")Víc detailů ke spojením najdete např. v (Spector 2008, 23–25) nebo (Peng 2016, 33–35).
Načtení více souborů najednou
Někdy máme data se stejnou strukturou rozdělená do více dílčích souborů. To vzniká typicky v situaci, kdy data zapisuje nějaký senzor nebo robot. Funkce read_XXX() umožňují načíst takové soubory naráz a automaticky je spojit do jedné tabulky. Stačí místo cesty k souboru zadat vektor řetězců, který obsahuje cesty ke všem načítaným souborům:
files <- fs::dir_ls(path = "rawdata", glob = "data*.tsv")
rawdata <- readr::read_tsv(files, id = "path")Funkce dir_ls() z balíku fs najde všechny soubory v adresáři rawdata, která odpovídají zadané masce, tj. např. soubory data0001.tsv, data0002.tsv atd. a absolutní cesty k těmto souborům vrátí jako vektor řetězců. Následně funkce read_tsv() všechny tyto soubory načte a spojí do jedné tabulky rawdata. Pokud je zadán parametr id, pak funkce k vlastním datům přidá i sloupec, do kterého uloží zadanou cestu k načítaným souborům. Jméno tohoto sloupce určí parametr id; zde se tedy bude jmenovat “path”. Přidání tohoto sloupce je užitečné např. v případě, že vlastní data neobsahují všechny proměnné a chybějící proměnné jsou součástí jména datového souboru nebo cesty k němu.
Načtení tabulárních dat v RStudiu
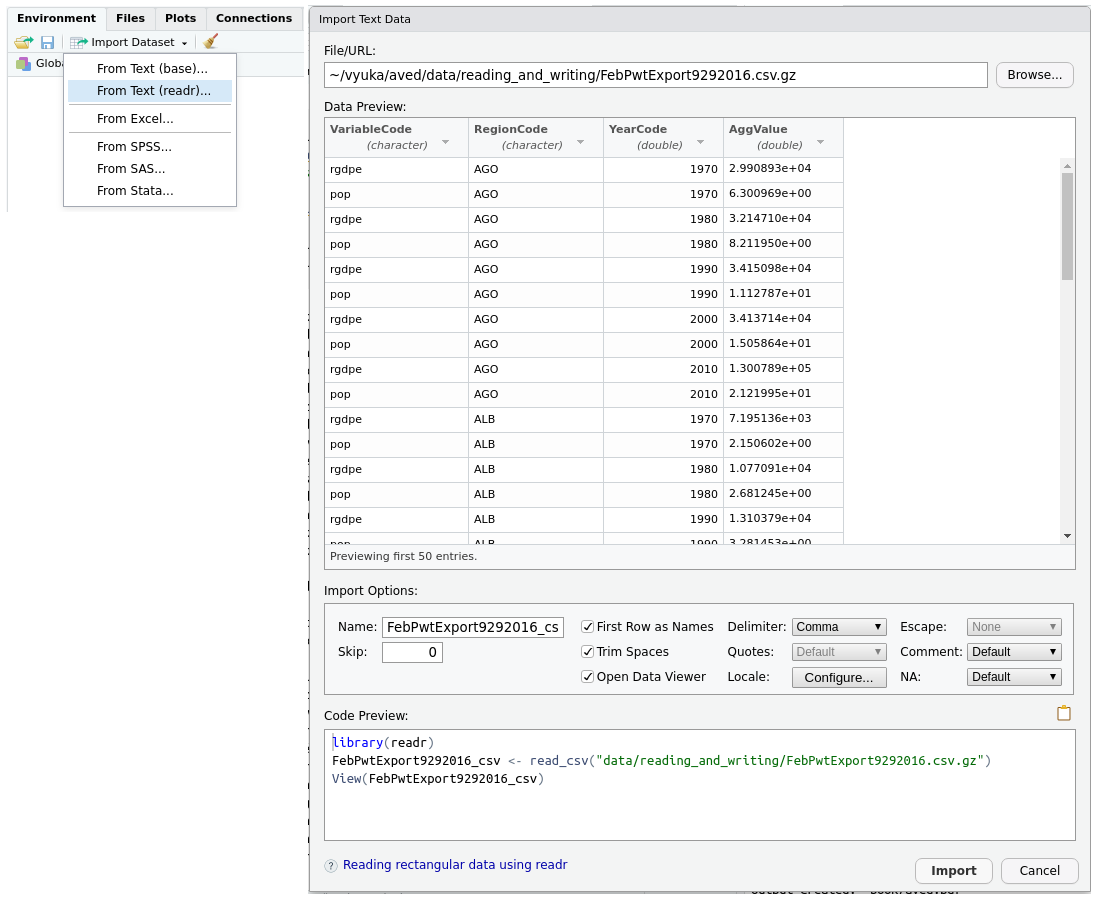
Při interaktivní práci je možné využít toho, že RStudio umí načíst tabulární textová data. V záložce Environment klikněte na Import Dataset a zvolte From Text (readr)..., viz levá část obrázku 10.1. Nástroj odhadne většinu potřebných parametrů a zbytek (včetně locale) je možné konfigurovat, viz pravá část obrázku 10.1. Příjemné je, že nástroj vygeneruje i potřebný kód, který můžete překopírovat do svého skriptu. Nástroj vám tedy umožní vizuálně odladit základní nastavení načítání dat, detaily můžete doladit později ve skriptu.
10.2 Další textové formáty
Balík readr umožňuje číst data i z dalších typů textových formátů. Nejjednodušším případem jsou tabulární formáty, které nejsou delimitované, tj. jednotlivé sloupce nejsou oddělené jasně definovaným znakem. Sem patří zejména dva typy formátů. V prvním jsou jednotlivé sloupce oddělené mezerami (nebo jinými “bílými znaky”, např. tabelátory). V ideálním případě jsou mají všechny sloupce díky bílým znakům právě stejnou šířku. K načtení těchto formátů slouží funkce read_table(). Druhou možností jsou formáty s pevnou šířkou sloupců. K jejich načtení můžete použít funkci read_fwf(). Všechny tyto funkce mají syntaxi velmi podobnou funkcím na čtení delimitovaných formátů.
Soubor “bmi_data.txt” obsahuje stejná data jako výše, ovšem tentokrát jsou oddělená jen bílými místy, v našem případě mezerami:
id height weight bmi
1 153 55 23.4952368747
2 207 97 22.6376344839
3 173 83 27.7322997761
4 181 92 28.0821708739
5 164 112 41.6418798334Použít funkce read_delim() a její speciální varianty není možné, protože nemáme jasný oddělující znak (dokonce ani mezera by nefungovala, vyzkoušejte si to a vysvětlete, proč). Naštěstí pro nás je možné tato data snadno načíst pomocí funkce read_table():
read_table("data/reading_and_writing/bmi_data.txt",
col_types = "iiid")# A tibble: 5 × 4
id height weight bmi
<int> <int> <int> <dbl>
1 1 153 55 23.5
2 2 207 97 22.6
3 3 173 83 27.7
4 4 181 92 28.1
5 5 164 112 41.6Naše tabulka má všechny sloupce stejně široké, můžeme tedy použít i funkci read_fwf(). V tomto případě je však třeba specifikovat hranice jednotlivých sloupců. K tomu slouží pomocné funkce fwf_empty(), fwf_widths, fwf_positions() a fwf_cols(). Nejjednodušší z nich je funkce fwf_widths(), do které se zadává šířka jednotlivých sloupců. Formát FWF také nepodporuje jména sloupců, takže musíme přeskočit první řádek, který jména obsahuje, a jména sloupců zadat ručně ve funkci fwf_widths():
read_fwf("data/reading_and_writing/bmi_data.txt",
fwf_widths(c(2, 7, 7, 13), c("id", "výška", "váha", "bmi")),
col_types = "iiid",
skip = 1)# A tibble: 5 × 4
id výška váha bmi
<int> <int> <int> <dbl>
1 1 153 55 23.5
2 2 207 97 22.6
3 3 173 83 27.7
4 4 181 92 28.1
5 5 164 112 41.6Na další detaily se podívejte do dokumentace. Balík readr neobsahuje žádné funkce pro výpis do těchto formátů.
V případě, že textová data nejsou formátována ani jedním z výše popsaných formátů, je možné načíst textový soubor jako řetězec a data si zpracovat sami pomocí funkcí, které se naučíte v kapitole 11. K načtení textového souboru po jednotlivých řádcích slouží funkce read_lines() a read_lines_raw(), které načtou jednotlivé řádky ze souboru a uloží je do vektoru řetězců, kde každý prvek odpovídá jednomu řádku. Obě funkce umožní zadat, kolik řádků načíst (parametr n_max) a kolik počátečních řádků přeskočit (parametr skip). Funkce read_lines() umožňuje zadat i kódování textu pomocí locale způsobem popsaným výše. Náš testovací datový soubor bychom načetli takto:
read_lines("data/reading_and_writing/bmi_data.csv")[1] "id,height,weight,bmi" "1,153,55,23.4952368747"
[3] "2,207,97,22.6376344839" "3,173,83,27.7322997761"
[5] "4,181,92,28.0821708739" "5,164,112,41.6418798334"Funkce write_lines() umožňuje uložit vektor řetězců do souboru. Na detaily se podívejte do dokumentace.
Pokud není způsob, jakým jsou v textovém souboru data rozdělena do řádků, užitečný, je možné načíst celý soubor do jednoho řetězce. K tomu slouží funkce read_file() a read_file_raw(). Funkce write_file() zapíše řetězec do souboru. Detaily použití opět najdete v dokumentaci.
10.3 Nativní R-kové binární soubory
Textové tabulární datové formáty jsou výborné při předávání dat mezi lidmi. Při vlastním zpracování dat je však výhodnější použít vlastní binární datový formát R. Jeho výhodou je, že data zabírají na disku méně místa, načítají se rychleji, mohou jakékoli datové typy včetně složitých objektů, obsahovat metadata včetně atributů a jde v nich ukládat i jiná data, než jsou tabulky (např. seznamy, pole, různé objekty apod.).
K uložení jednotlivých proměnných slouží funkce save(). Nejdříve se uvedou jména všech proměnných, které se mají uložit, a pak cesta k souboru, kam se mají uložit (další parametry jsou popsány v dokumentaci). Cestu je nutné zadat pojmenovaných parametrem file. Data se do těchto souborů obvykle ukládají s koncovkami .RData nebo .rda.
save(bmi_data, file = "bmi_data.RData")Pokud je proměnných více, oddělí se čárkou:
save(var1, var2, var3, var4, file = "somefile.RData")Někdy chcete uložit všechny proměnné, které máte v paměti R. K tomu slouží funkce save.image() (detaily viz dokumentace).
Data uložená pomocí funkcí save() nebo save.image() načteme do pracovního prostředí R pomocí funkce load(). Funkce načte všechny proměnné obsažené v daném datovém soubory včetně metadat, tj. není možné si vybrat jen jednotlivé proměnné uložené v souboru. Proměnným zůstanou jejich původní jména, tj. není možné načíst vybranou proměnnou do nové proměnné. Funkce data načte do pracovního prostředí, tj. nevrací je jako hodnotu funkce. Jediným důležitým parametrem funkce load() je cesta k datovému souboru:
load("bmi_data.RData")Pokud chcete do nativního binárního souboru uložit jen obsah jedné proměnné a ten pak opět načíst do nové proměnné, můžete použít dvojici funkcí saveRDS() a readRDS():
saveRDS(bmi_data, file = "bmi_data.RData")
bmi <- readRDS("bmi_data.RData")Balík readr implementuje lépe pojmenované obdoby těchto funkcí: read_rds() a write_rds(). Hlavní rozdíl mezi saveRDS() a write_rds() spočívá v tom, že funkce z balíku readr data implicitně nekomprimuje. Data tedy zabírají na disku více místa, ale podle dokumentace se načítají rychleji. (Ve skutečnosti rychlost načtení nekomprimovaných oproti komprimovaným datům závisí na relativní rychlosti počítače a disku, kde jsou data uložená. Pokud je počítač rychlý, ale disk pomalý, pak může být výhoda při načítání nekomprimovaných dat minimální.)
10.4 Načítání dat z balíků
Mnoho balíků v R obsahuje nějaká data. K načtení těchto dat slouží funkce data(). Stejně jako funkce load() ani tato funkce data nevrací, nýbrž je jako svůj vedlejší efekt načte přímo do pracovního prostředí R:
library(ggplot2)
data("diamonds")
head(diamonds)# A tibble: 6 × 10
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48Funkce data() může vypsat i seznam dat obsažených v daném balíku:
data(package = "ggplot2")Funkce data() umožňuje i načíst data bez načtení balíku. K tomu stačí zadat jméno balíku:
data("economics", package = "ggplot2")
head(economics)# A tibble: 6 × 6
date pce pop psavert uempmed unemploy
<date> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1967-07-01 507. 198712 12.6 4.5 2944
2 1967-08-01 510. 198911 12.6 4.7 2945
3 1967-09-01 516. 199113 11.9 4.6 2958
4 1967-10-01 512. 199311 12.9 4.9 3143
5 1967-11-01 517. 199498 12.8 4.7 3066
6 1967-12-01 525. 199657 11.8 4.8 3018Některé balíky zpřístupní svá data hned při svém načtení, takže není třeba je zpřístupňovat pomocí funkce data(). Tato data jsou obvykle zpřístupněna “líně”: implicitně se data nenačtou do paměti, ale pouze do vyhledávací cesty. Do paměti počítače se načtou až ve chvíli, kdy je poprvé jakkoli použijete.
Data v balících bývají obvykle dokumentovaná stejným způsobem, jako funkce. Nápověda je tedy dostupná pomocí funkce help() i pomocí otazníku. Po načtení dat economics můžete dokumentaci zobrazit např. takto: ?economics.
10.5 Načítání dat z MS Excelu
Někteří lidé (a některé statistické úřady) dávají data k dispozici jako soubory uložené z Microsoft Excelu. Používat tato data může být poněkud ošidné, protože datové “buňky” jsou často obalené různým balastem, který je potřeba odstranit. Nejbezpečnějším způsobem načtení dat z Excelu je tak data v Excelu ručně upravit, následně vyexportovat do CSV souboru a ten pak načíst způsobem popsaným v oddíle 10.1. Tak máte největší kontrolu nad tím, co se děje.
Data z Excelu je však v R možné načíst i přímo pomocí balíku readxl (umí načíst jak soubory.xls, tak .xlsx). Balík poskytuje dvě hlavní funkce: excel_sheets() a read_excel(). Funkce excel_sheets() má jediný argument (jméno souboru) a vypíše seznam listů, které Excelový soubor obsahuje.
Funkce read_excel() načte jeden list z Excelového souboru a vrátí jej jako tabulku třídy tibble. Jejím prvním parametrem je opět název excelového souboru. Druhým parametrem (sheet) určíte, který list se má načíst (implicitně první). List je možné zadat jménem (jako řetězec), nebo pozicí (jako celé číslo). Parametr range určuje oblast, která se má z excelového listu načíst (implicitně celý list). Nejjednodušší způsob určení oblasti je pomocí excelových rozsahů. Pokud např. chceme načíst buňky od B5 po E17, nastavíme range = "B5:E17". Sofistikovanější výběry jsou popsané v dokumentaci k balíku cellranger. Pokud rozsah zabere i oblast “prázdných buněk”, pak jsou chybějící hodnoty označeny jako NA.
Funkce read_excel() se v ostatních ohledech chová podobně jako funkce read_csv() z balíku readr. První řádek výběru interpretuje funkce jako názvy sloupců. Pokud to nevyhovuje, je možné toto chování modifikovat pomocí parametru col_names, jehož specifikace je stejná jako u funkce read_csv().
Typy jednotlivých sloupců funkce read_excel() odhaduje z prvních 1 000 řádků dat. Pomocí parametru col_types je však možné jednotlivé sloupce zadat, a to jako vektor následujících řetězců: “skip”, “guess”, “logical”, “numeric”, “date”, “text” a “list”. První možnost sloupec přeskočí, druhá odhadne typ. Typ “list” vytvoří sloupec typu seznam (normálně je každý sloupec tabulky atomický vektor), což umožní, aby každá buňka sloupce mohla mít vlastní datový typ zjištěný z dat. Ostatní typy mají očividný význam. Pokud je zadán právě jeden typ, R jej recykluje a použije pro všechny sloupce.
Funkce umožňuje také přeskočit několik prvních řádků výběru pomocí parametru skip, načíst maximálně určitý počet řádků pomocí parametru n_max a zadat, jaká hodnota z excelového souboru se převede na hodnotu NA v R pomocí parametru na. Na další parametry funkce se podívejte do dokumentace.
Následující kód ukazuje příklad, jak funkce použít:
library(readxl)
excel_sheets("data/reading_and_writing/FebPwtExport9292016.xlsx")[1] "Preface" "Data" "Variables" "Regions" dt <- read_excel("data/reading_and_writing/FebPwtExport9292016.xlsx",
sheet = "Data",
col_types = c("text", "text", "numeric", "numeric"))
head(dt)# A tibble: 6 × 4
VariableCode RegionCode YearCode AggValue
<chr> <chr> <dbl> <dbl>
1 rgdpe AGO 1970 29909.
2 pop AGO 1970 6.30
3 rgdpe AGO 1980 32147.
4 pop AGO 1980 8.21
5 rgdpe AGO 1990 34151.
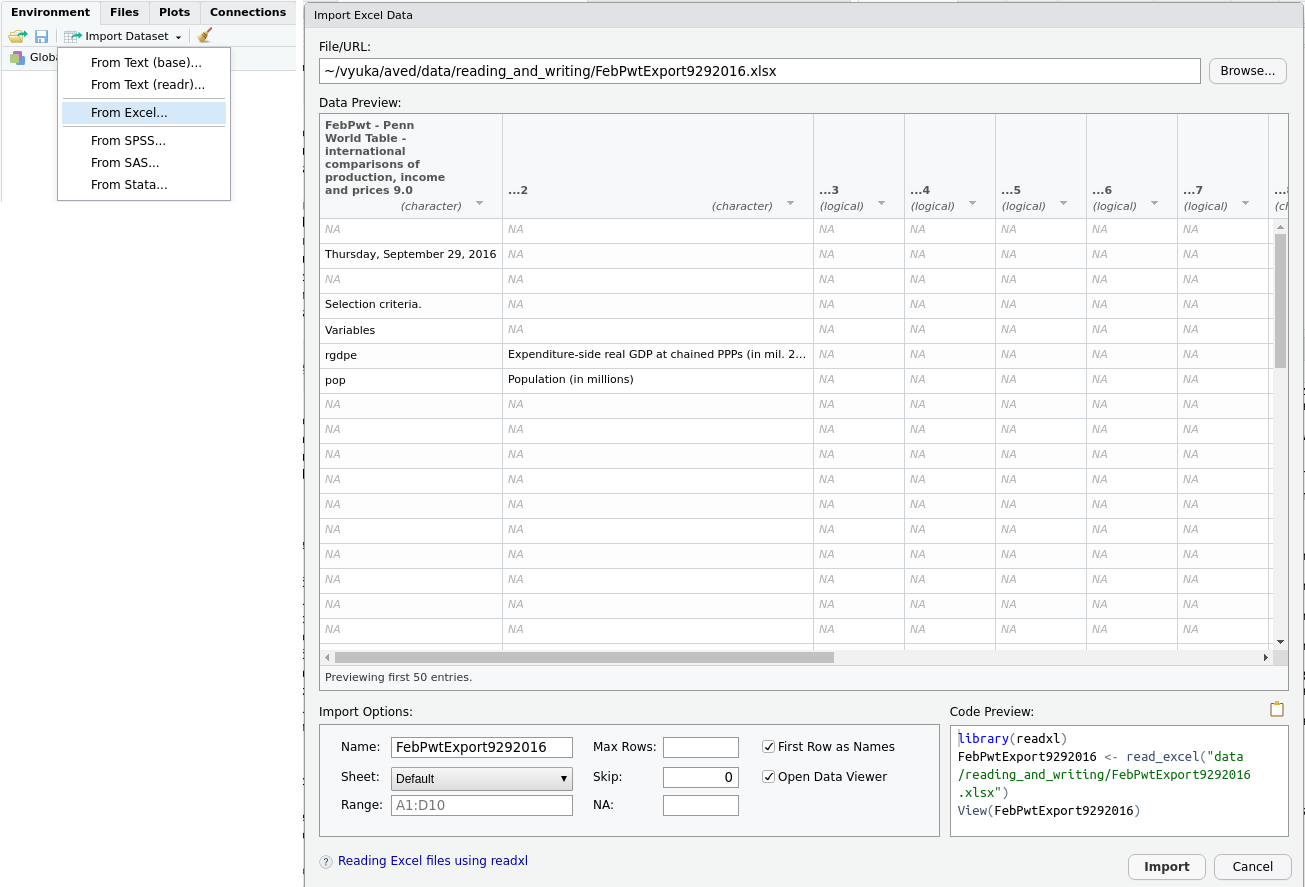
6 pop AGO 1990 11.1 Pokud je balík readxl nainstalován, pak RStudio umožňuje načíst excelové soubory pomocí interaktivního nástroje Import Dataset dostupného v panelu Environment, viz levá část obrázku 10.2. Po jeho spuštění zvolte From Excel.... Nástroj umožňuje dokonce vybrat list a rozsah dat, nastavit jména sloupců a několik dalších věcí, viz pravá část obrázku 10.2. Nástroj opět vygeneruje kód, který je možné zkopírovat a vložit do skriptu.
Balík readxl zatím neumožňuje data do excelových souborů zapisovat. Pokud to potřebujete, podívejte se na balík openxlsx.
10.6 Data z jichých statistických programů
Někdy jsou data distribuovaná v nativním formátu některého statistického softwaru. K jejich načtení je možné použít balíky haven a foregin. Balík haven slouží k načítání a ukládání souborů v nativních formátech programů SPSS, SAS a Stata. Balík foreign umí načítat některé další datové formáty (a do vybraných formátů i zapisovat). Pokud nějaký formát umí číst oba balíky, doporučuji použít balík haven, na který se zde zaměříme. Jak se používá balík foreign, zjistíte v jeho dokumentaci.
K načítání dat poskytuje balík haven následující funkce: funkce read_dta() a read_stata() čtou soubory Stata DTA, funkce read_por(), read_sav() a read_spss() čtou soubory SPSS POR a SAV a funkce read_xpt() a read_sas() čtou soubory SAS. Všechny tyto funkce vracejí načtená data jako tabulku třídy tibble. Funkce write_dta, write_sas, write_sav a write_xpt() zapisují odpovídající formáty. Před jejich použitím je potřeba balík haven načíst; užitečné je zároveň načíst i balík labelled:
library(haven)
library(labelled)Data pak načteme očekávávaným způsobem, kdy jméno souboru je prvním parametrem funkce read_xxx():
dt <- read_spss("nama_10_gdp.sav")Přitom mohou nastat dva problémy. První spočívá v tom, že velké množství dat uložených v těchto formátech zřejmě nebylo vytvořených přímo v programech Stata, SPSS nebo SAS, nýbrž je vytvořily nějaké konvertory, které braly data z databáze. Tyto konvertory často daný formát zcela nedodržují, takže vlastní software takto vytvořená data načte, ale balík haven si s nimi neporadí. V tom případě je potřeba načíst data do originálního softwaru (někdy stačí jeho svobodná obdoba, např. pro software SPSS program PSPP) a data uložit do formátu CSV. Někdy také pomůže data znovu uložit do nativního formátu daného softwaru – balík haven si s nimi potom poradí. Alternativně je možné vyzkoušet balík foreign. V některých případech uspěje tam, kde haven selhal.
Druhý problém spočívá v tom, že všechny tři výše zmíněné programy používají poněkud jiné datové struktury než R. Zejména se to týká “popisků dat” a kódování chybějících hodnot. Detaily rozdílů najdete ve vinětě balíku haven s názvem “Conversion semantics”. Zde se zaměříme pouze na popisky hodnot ve vektorech. Stata, SPSS a další statistické programy umožňují “přibalit” k proměnné (sloupci v tabulce) nějaké dodatečné informace. Ukázkovým příkladem může být uchovávání dotazníkových dat. Předpokládejme, že respondenti odpovídali na následující otázku:
Máte rádi zpěv ve sprše?
- Určitě ano
- Spíše ano
- Spíše ne
- Určitě ne
Samotná odpověď je typicky uložena jako číslo kódující odpověď nebo druh chybějící odpovědi (např. “irelevantní”, nebo “odmítl odpovědět” a podobně). Význam těchto číselných kódů může být popsán právě v těchto “přibalených” informacích. Ty často obsahují i samotné znění otázky. Balík haven převede při načítání dat sloupce s přibalenými informacemi do třídy labelled. Balík zároveň implementuje i základní funkce a metody pro práci s daty této třídy; další funkce jsou obsaženy v balíku labelled.
Vektor třídy labelled je možné vytvořit i uměle pomocí labelled() z balíku haven:
lvector <- labelled(c(1,1,2,3,1,4,-99),
c("Určitě ano" = 1,
"Spíše ano" = 2,
"Spíše ne" = 3,
"Určitě ne" = 4,
"Odmítl odpovědět" = -99)
)
class(lvector)[1] "haven_labelled" "vctrs_vctr" "double" Po načtení jsou vektory této třídy součástí načtené tabulky. Zde si pro jednoduchost takovou tabulku vytvoříme ručně:
ltable <- tibble::tibble(lvector)
print(ltable)# A tibble: 7 × 1
lvector
<dbl+lbl>
1 1 [Určitě ano]
2 1 [Určitě ano]
3 2 [Spíše ano]
4 3 [Spíše ne]
5 1 [Určitě ano]
6 4 [Určitě ne]
7 -99 [Odmítl odpovědět]Číst informace z “labels” umožňují funkce val_labels() a var_label() z balíku labelled. Funkce var_labels() vrací “labels” přiřazené proměnné – tj. celému sloupci (typicky znění otázky). val_labels() vrací “labels” pro kódovací hodnoty v tabulce:
val_labels(ltable)$lvector
Určitě ano Spíše ano Spíše ne Určitě ne
1 2 3 4
Odmítl odpovědět
-99 Pro třídu labelled je v R dostupné jen velmi málo metod. Proto bývá obvyklým krokem jejich konverze do jiného datové typu. Při této operaci je užitečné být opatrný. Pouhé odstranění “lables” totiž za sebou zanechá vektory celých čísel nebo tajemně kódovaných řetězců. K touto účelu slouží funkce zap_labels():
zap_labels(ltable)# A tibble: 7 × 1
lvector
<dbl>
1 1
2 1
3 2
4 3
5 1
6 4
7 -99Lepším způsobem je konverze kódovacích hodnot na faktor. K tomu slouží funkce as_factor(), která umí převést jeden vektor i celou tabulku. Alternativně je možné popisky převést na faktor i pomocí funkce to_factor() nebo na vektor řetězců pomocí funkce to_character() z balíku labelled.
as_factor(ltable)# A tibble: 7 × 1
lvector
<fct>
1 Určitě ano
2 Určitě ano
3 Spíše ano
4 Spíše ne
5 Určitě ano
6 Určitě ne
7 Odmítl odpovědětPodobným způsobem je možné se vyrovnat i s různě kódovanými chybějícími hodnotami, viz viněta “Conversion semantics”.
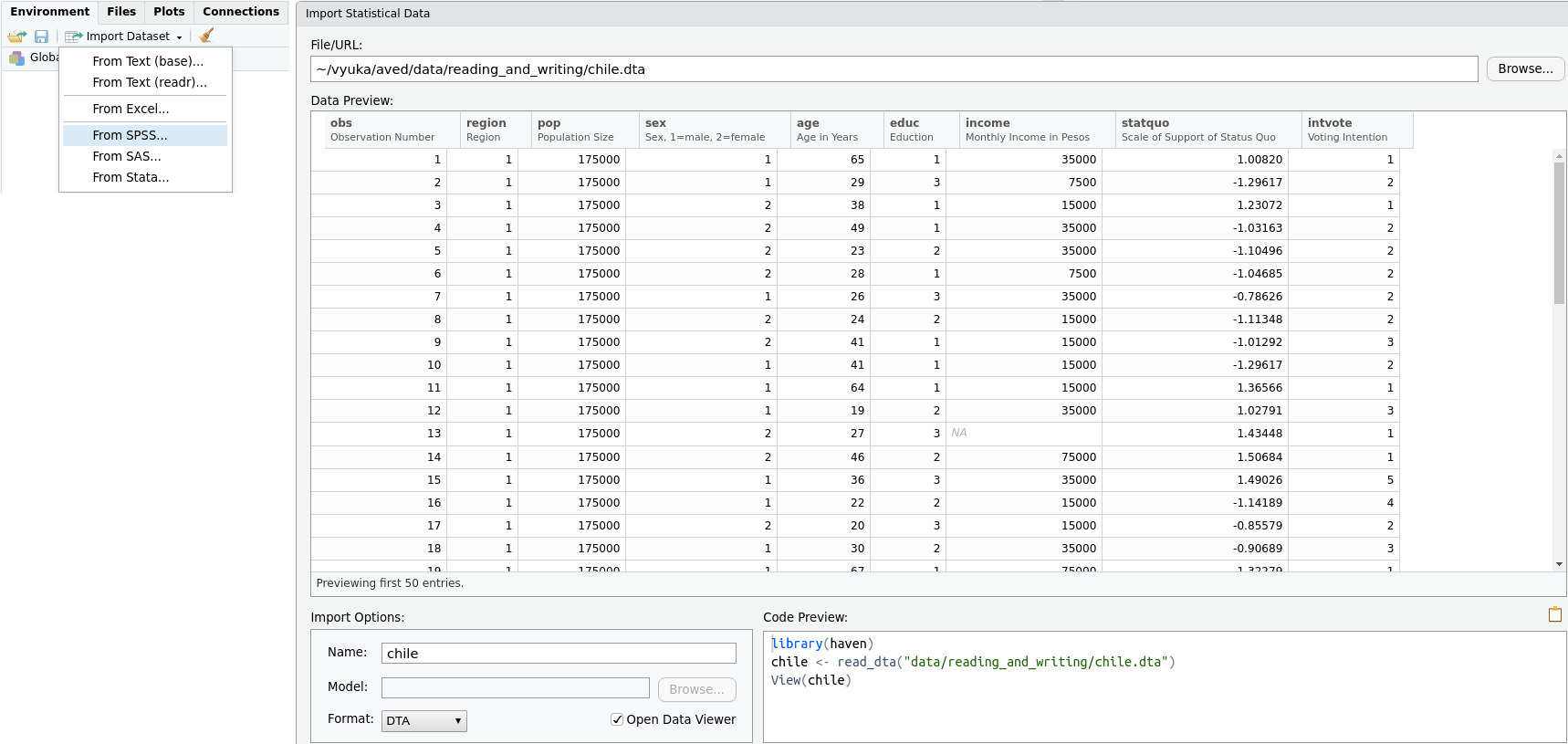
Pokud máte balík haven nainstalovaný, můžete v RStudiu načítat data z SPSS, SASu a Staty i interaktivně, když v záložce Import Dataset v tabu Environment zvolíte From SPSS..., From SAS... nebo From Stata..., viz levá strana obrázku 10.3. Nástroj nemá žádná zvláštní nastavení, opět však vygeneruje kód, který můžete vložit do svého skriptu, viz , viz pravá strana obrázku 10.3.
10.7 Rychlá cesta k datům: balík rio
Pokud chcete rychle načíst data z datového souboru (lokálního nebo na webu, nekomprimovaného nebo komprimovaného) a nepotřebujete mít důkladnou kontrolu nad zpracováním dat, můžete použít balík rio. Tento balík představuje wrapper nad balíky, které načítají data včetně balíků readxl, haven, foreign a mnoha dalších, takže umí načíst všechna data, která umí načíst funkce implementované v těchto balících. Balík implementuje především dvě funkce: import() a export(). Funkce import() načte data z datového souboru a uloží je do proměnné třídy data.frame. Funkce export() uloží data do datového souboru. Typ datového souboru odhadují obě funkce z koncovky dat. Načítání a ukládání některých méně obvyklých formátů může vyžadovat doinstalování potřebných balíků. Seznam všech podporovaných formátů obsahuje viněta k balíku.
Funkce import() vyžaduje nutně jen jeden parametr: cestu k načítanému souboru. Pokud by se formát dat odhadl z koncovky souboru špatně, umožňuje parametr format zadat typ dat ručně. Parametr setclass umožňuje změnit datovou strukturu, kterou funkce vrátí. Implicitně je to data.frame, ale povolený je mimo jiné i tibble. Další parametry najdete v dokumentaci k funkci. Funkce export() vyžaduje nutně jméno ukládané tabulky a jméno souboru včetně cesty. Další parametry opět najdete v dokumentaci.
Několik příkladů použití:
library(rio)
bmi <- import("data/reading_and_writing/bmi_data.csv.gz")
chile <- import("data/reading_and_writing/chile.dta")
xls <- import("data/reading_and_writing/FebPwtExport9292016.xlsx")
export(bmi, "test.csv")
export(bmi, "test.sav")10.8 Kontrola načtených dat
Když načtete data ze souboru do paměti počítače, je obvykle moudré zkontrolovat, že se načetla všechna data, že se načetla správně a že znamenají to, co si myslíte. Vyplatí se projít minimálně těchto několik kroků:
- Zkontrolujte, že má tabulka správný počet řádků (
nrow()) a sloupců (ncol()), tj. že se načetlo vše a nenačetl se nějaký “odpad” uložený na začátku nebo konci datového souboru. - Podívejte se na začátek (
head()) a konec (tail()) tabulky; to opět pomůže zkontrolovat, zda se nenačetl nějaký zmatek na začátku nebo konci souboru a že vše vypadá tak, jak má. - Zkontrolujte strukturu tabulky (v tabulce třídy tibble vypsané nahoře, jinak pomocí funkce
str()) – jména sloupců, jejich typy a hodnoty. - Podívejte se na souhrnné statistiky dat (
summary()): Jaké jsou hodnoty proměnných, zda dávají smysl a zda jsou správně velké. Porovnejte hodnoty s tím, co víte odjinud. Zkontrolujte také, kde hodnoty chybí apod.
Pokud jsou hodnoty “divné”, může to indikovat různé problémy. Jednou jsem dostal data, která mimo jiné obsahovala ceny jízdenek na různých evropských železnicích. Ceny ve Francii vypadaly podsatně vyšší než jinde. Podrobnější průzkum dat ukázal, že ve francouzských datech někoho napadlo kódovat chybějící ceny hodnotou 9999 (eur). Jindy jsem analyzoval ceny letenek na různých trasách. Tyto ceny se vzpíraly jakékoli logice. Nakonec se ukázalo, že data jsou kódovaná v různých měnách – některé letenky v eurech, jiné v dolarech, další v jenech nebo korunách. V datech z divočiny bývá také často problém v desetinných čárkách, které někdy chybí, v jednotkách (někdo zadává ceny v korunách, jiný v tisících) apod. Pointa je jasná: k datům nemůžete přistupovat jako k “daným věcem”, ale potřebujete zkontrolovat, zda se načetla technicky správně a zda mají skutečně ten význam, který si myslíte.
Od verze 2.0 neumí funkce z balíku readr načítat soubory, které mají řádky oddělené pouze pomocí tzv. carriage return (znaku
\r). Přestože žádný operační systém by už od roku 2001 neměl takové soubory vytvářet, můžete je v divočině občas dosud najít. Nejjednodušší způsob, jak takový soubor načíst, je použít funkce ze základního R.↩︎